java liveness_Kubernetes Liveness and Readiness Probes
在设计关键任务、高可用应用程序时,弹性是要考虑的最重要因素之一。
当应用程序可以快速从故障中恢复时,它便具有弹性。
云原生应用程序通常设计为使用微服务架构,其中每个组件都位于容器中。为了确保Kubernetes托管的应用程序高可用,在设计集群时需要遵循一些特定的模式,其中有“健康探测模式”。应用高可观察性原则(HOP)可确保您的应用程序收到的每个请求都能及时找到响应。
The High Observability Principle (HOP)
高可观察性原则是基于容器的应用程序设计原则之一。微服务体系要求每个服务不关心(也不应该关心)被调用方如何处理请求。
HOP原则要求每个服务必须公开几个API端点,其意义在于揭示服务健康状态,Kubernetes调用这些端点,决定下一步的路由和负载平衡。
“
设计良好的云原生程序应将日志事件记录到STDERR和STDOUT,由logstash、Fluent等日志摄取服务将这些日志运送到集中式监控(例如Prometheus)和日志聚合系统(例如ELK)。下图说明了云原生应用程序如何遵守健康状况探测模式和高可观察性原则。
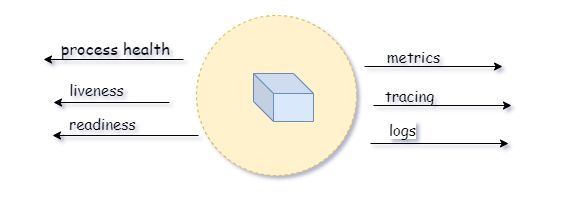
How to Apply Health Probe Pattern in Kubernetes?
我之前写过ASP.NetCore + Docker健康检查的原创:[web程序暴露http健康检查端点,平台轮询探测],Kubernetes针对不同场合细化了探针,更为强大的是给出对应决策。

Liveness Probes
使用[存活探针]判断什么时候重启容器。
使用存活探针检查应用本身是否无响应、死锁, 有时候重启容器常常能解决此类问题。
我们以kubernetes官方demo为例:
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5 # 指示kubectl等待5s才执行首次探测
periodSeconds: 5 # 间隔5秒轮询
在第5秒kubectl开始首次liveness探测
在30秒进行的每次探测均成功
30s之后容器内文件被删除,之后间隔5s的探测会失败,根据liveness默认配置连续3次失败就会放弃探测,放弃探测意味着重启容器,故容器会在第45s重启
重启之后又开始以上流程, 故可以看到此探针以重启的决策尝试修复应用问题。
这个探针会体现到kubectl get pod的RESTARTS列
![]()
Readiness Probes
使用[就绪探针]判断容器是否就绪,是否可以接受流量。
Pod内所有容器ready,则该Pod被认为ready,当pod没有ready,将会从服务负载均衡中移除。
“
有些时候,应用程序临时不可用(加载大量数据或者依赖外部服务),这个时候,重启这个Pod无济于事,但你也不希望请求被发送到该Pod
下面的应用强依赖mongodb,我们针对这些依赖项设置了readiness探针
services.AddHealthChecks()
.AddCheck(nameof(MongoHealthCheck), tags: new[] { "readyz" });
// ----------------------
app.UseHealthChecks("/readyz", new HealthCheckOptions
{
Predicate = (check) => check.Tags.Contains("readyz")
});
以下代码探测Mongodb的连通性
sealed class MongoHealthCheck : IHealthCheck
{
private readonly IMongoDatabase _defaultMongoDatabase;
public MongoHealthCheck(IDefaultMongoDatabaseProvider defaultMongoDatabaseProvider)
{
_defaultMongoDatabase = defaultMongoDatabaseProvider.GetDatabase();
}
public async Task CheckHealthAsync(HealthCheckContext context, CancellationToken cancellationToken = default)
{
var doc = await _defaultMongoDatabase.RunCommandAsync(
new BsonDocumentCommand(
new BsonDocument() {
{ "ping", "1" }
}),
cancellationToken: cancellationToken);
var ok = doc["ok"].ToBoolean();
if (ok)
{
return HealthCheckResult.Healthy("OK");
}
return HealthCheckResult.Unhealthy("NotOK");
}
}
对于依赖项的探测,探测周期和超时时间可以设置的稍长一点
readinessProbe:
httpGet:
path: /readyz
port: 80
initialDelaySeconds: 5
periodSeconds: 60 # 60s探测一次
timeoutSeconds: 30 # 每次探测30s超时,与应用建立与依赖项的连接超时时间一致
failureThreshold: 3 # 连续3次探测失败,该Pod会被标记为`Unready`
Startup Probes
使用[启动探针]判断容器应用是否已经启动。如果配置了这个探针,则该探针成功之前将会禁用存活和就绪探针。
配置探针
initialDelaySeconds:容器启动,探针延后工作,默认是0s
periodSeconds 探针探测周期,默认10s
timeoutSeconds:探针工作的超时时间,默认1s
successThreshold:连续几次探测成功,该探针被认为是成功的,默认1次
failureThreshold:连续几次探测失败,该探针被认为最终失败,对于livenes探针最终失败意味着重启,对于readiness探针意味着该pod Unready, 默认3次。
强烈建议根据应用结构合理设置探针参数,避免不切实际的认定失败导致的频繁重启或 Unready。
结束语:
Kubernetes生态这么庞大,为啥单独拎出k8s探针, 是因为k8s探针是与应用程序结构密切相关的机制。就使用方式看:
存活探针:用于快速判断应用进程是否无响应,尝试重启修复;
就绪探针:判断应用及依赖项是否就绪,是否可以分配流量,如果不能就标记Unready,从负载均衡器中移除该Pod。
Kubernetes存活、就绪探针可以极大地提高服务的健壮性和弹性,并提供出色的最终用户体验。
干货周边也很重要
如果本文对你有帮助,
不妨来个分享、点赞、在看三连