ocr表格识别(四)——文本检测DBnet原理及其实现
文本检测DBnet原理及其实现
- 文本检测之DBnet
- 文本检测之DBnet模型构建
-
- Backbone选择与构建
- 构建FPN特征金字塔
- DBhead 可微二值化
文本检测之DBnet
-
DB(DifferenttiableBinarization)可微二值化是一个基于分割的文本检测算法,其 提出可微分阈值Differenttiable Binarization module(DB module)采用动态的阈值区分文本区域与背景。
-
基于分割的普通文本检测算法其流程如上图中的蓝色箭头所示,此类方法得到分割结果之后采用一个固定的阈值得到二值化的分割图,之后采用诸如像素聚类的启发式算法得到文本区域。

-
DB算法的流程如图中红色箭头所示,最大的不同在于DB有一个阈值图,通过网络去预测图片每个位置处的阈值,而不是采用一个固定的值,更好的分离文本背景与前景。
-
DB算法有以下几个优势:算法结构简单,无需繁琐的后处理;在开源数据上拥有良好的精度和性能;在传统的图像分割算法中,获取概率图后,会使用标准二值化(Standard Binarize)方法进行处理,将低于阈值的像素点置0,高于阈值的像素点置1,公式如下:
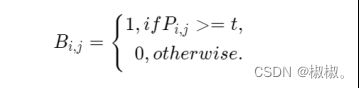
-
但是标准的二值化方法是不可微的,导致网络无法端对端训练。为了解决这个问题,DB算法提出了可微二值化(Differentiable Binarization,DB)。可微二值化将标准二值化中的阶跃函数进行了近似,使用如下公式进行代替:
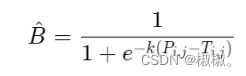
-
其中,P是上文中获取的概率图,T是上文中获取的阈值图,k是增益因子,在实验中,根据经验选取为50。标准二值化和可微二值化的对比图如下图3(a)所示。
-
当使用交叉熵损失时,正负样本的loss分别为:
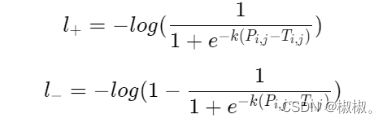
-
对输入求偏导则会得到:
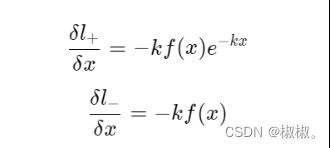
-
可以发现,增强因子会放大错误预测的梯度,从而优化模型得到更好的结果。图3(b) 中,x<0x<0x<0 的部分为正样本预测为负样本的情况,可以看到,增益因子k将梯度进行了放大;而 图3(c) 中x>0x>0x>0的部分为负样本预测为正样本时,梯度同样也被放大了。

DB算法整体结构如下图所示:

-
输入的图像经过网络Backbone和FPN提取特征,提取后的特征级联在一起,得到原图四分之一大小的特征,然后利用卷积层分别得到文本区域预测概率图和阈值图,进而通过DB的后处理得到文本包围曲线。
文本检测之DBnet模型构建
-
Backbone网络,负责提取图像的特征
-
FPN网络,特征金字塔结构增强特征
-
Head网络,计算文本区域概率图
-因此,需要从以上三个方面来依次构建DBNET文本检测网络模型。
本节使用PaddlePaddle分别实现上述三个网络模块,并完成完整的网络构建。 -
可以通过安装paddleocr来进行代码实现,或者下载paddleocr源码进行实现。
Backbone选择与构建
- 这里采用MobileNetV3 large结构作为backbone。
from ppocr.modeling.backbones.det_mobilenet_v3 import MobileNetV3
import paddle
fake_inputs = paddle.randn([1, 3, 640, 640], dtype="float32")
# 1. 声明Backbone
model_backbone = MobileNetV3()
model_backbone.eval()
# 2. 执行预测
outs = model_backbone(fake_inputs)
# 3. 打印网络结构
print(model_backbone)
#data_format=NCHM NCHM分别代表的含义:[batch, in_channels, in_height, in_width]
# 4. 打印输出特征形状
for idx, out in enumerate(outs):
print("The index is ", idx, "and the shape of output is ", out.shape)
#mobilenetv3:
class MobileNetV3(nn.Layer):
def __init__(self,
in_channels=3,
model_name='large',
scale=0.5,
disable_se=False,
**kwargs):
"""
the MobilenetV3 backbone network for detection module.
Args:
params(dict): the super parameters for build network
"""
super(MobileNetV3, self).__init__()
self.disable_se = disable_se
if model_name == "large":
cfg = [
# k, exp, c, se, nl, s,
[3, 16, 16, False, 'relu', 1],
[3, 64, 24, False, 'relu', 2],
[3, 72, 24, False, 'relu', 1],
[5, 72, 40, True, 'relu', 2],
[5, 120, 40, True, 'relu', 1],
[5, 120, 40, True, 'relu', 1],
[3, 240, 80, False, 'hardswish', 2],
[3, 200, 80, False, 'hardswish', 1],
[3, 184, 80, False, 'hardswish', 1],
[3, 184, 80, False, 'hardswish', 1],
[3, 480, 112, True, 'hardswish', 1],
[3, 672, 112, True, 'hardswish', 1],
[5, 672, 160, True, 'hardswish', 2],
[5, 960, 160, True, 'hardswish', 1],
[5, 960, 160, True, 'hardswish', 1],
]
cls_ch_squeeze = 960
elif model_name == "small":
cfg = [
# k, exp, c, se, nl, s,
[3, 16, 16, True, 'relu', 2],
[3, 72, 24, False, 'relu', 2],
[3, 88, 24, False, 'relu', 1],
[5, 96, 40, True, 'hardswish', 2],
[5, 240, 40, True, 'hardswish', 1],
[5, 240, 40, True, 'hardswish', 1],
[5, 120, 48, True, 'hardswish', 1],
[5, 144, 48, True, 'hardswish', 1],
[5, 288, 96, True, 'hardswish', 2],
[5, 576, 96, True, 'hardswish', 1],
[5, 576, 96, True, 'hardswish', 1],
]
cls_ch_squeeze = 576
else:
raise NotImplementedError("mode[" + model_name +
"_model] is not implemented!")
supported_scale = [0.35, 0.5, 0.75, 1.0, 1.25]
assert scale in supported_scale, \
"supported scale are {} but input scale is {}".format(supported_scale, scale)
inplanes = 16
# conv1
self.conv = ConvBNLayer(
in_channels=in_channels,
out_channels=make_divisible(inplanes * scale),
kernel_size=3,
stride=2,
padding=1,
groups=1,
if_act=True,
act='hardswish')
self.stages = []
self.out_channels = []
block_list = []
i = 0
inplanes = make_divisible(inplanes * scale)
for (k, exp, c, se, nl, s) in cfg:
se = se and not self.disable_se
start_idx = 2 if model_name == 'large' else 0
if s == 2 and i > start_idx:
self.out_channels.append(inplanes)
self.stages.append(nn.Sequential(*block_list))
block_list = []
block_list.append(
ResidualUnit(
in_channels=inplanes,
mid_channels=make_divisible(scale * exp),
out_channels=make_divisible(scale * c),
kernel_size=k,
stride=s,
use_se=se,
act=nl))
inplanes = make_divisible(scale * c)
i += 1
block_list.append(
ConvBNLayer(
in_channels=inplanes,
out_channels=make_divisible(scale * cls_ch_squeeze),
kernel_size=1,
stride=1,
padding=0,
groups=1,
if_act=True,
act='hardswish'))
self.stages.append(nn.Sequential(*block_list))
self.out_channels.append(make_divisible(scale * cls_ch_squeeze))
for i, stage in enumerate(self.stages):
self.add_sublayer(sublayer=stage, name="stage{}".format(i))
def forward(self, x):
x = self.conv(x)
out_list = []
for stage in self.stages:
x = stage(x)
out_list.append(x)
return out_list
构建FPN特征金字塔
- 负责图像特征增强
import paddle
# 1. 从PaddleOCR中import DBFPN
from ppocr.modeling.necks.db_fpn import DBFPN
# 2. 获得Backbone网络输出结果
fake_inputs = paddle.randn([1, 3, 640, 640], dtype="float32")
model_backbone = MobileNetV3()
in_channles = model_backbone.out_channels
# 3. 声明FPN网络
model_fpn = DBFPN(in_channels=in_channles, out_channels=256)
# 4. 打印FPN网络
print('FPN模型输出:',model_fpn)
# 5. 计算得到FPN结果输出
outs = model_backbone(fake_inputs)
fpn_outs = model_fpn(outs)
# 6. 打印FPN输出特征形状
print(f"The shape of fpn outs {fpn_outs.shape}")
#Conv2d(in_channels=3,out_channels=64,kernel_size=4,stride=2,padding=1,data_format=NCHM),输入通道数,输出通道数,卷积核大小,数据格式为NCHM batch channels in_hight in_width
其中DBFTN类函数:
class DBFPN(nn.Layer):
def __init__(self, in_channels, out_channels, **kwargs):
super(DBFPN, self).__init__()
self.out_channels = out_channels
weight_attr = paddle.nn.initializer.KaimingUniform()
self.in2_conv = nn.Conv2D(
in_channels=in_channels[0],
out_channels=self.out_channels,
kernel_size=1,
weight_attr=ParamAttr(initializer=weight_attr),
bias_attr=False)
self.in3_conv = nn.Conv2D(
in_channels=in_channels[1],
out_channels=self.out_channels,
kernel_size=1,
weight_attr=ParamAttr(initializer=weight_attr),
bias_attr=False)
self.in4_conv = nn.Conv2D(
in_channels=in_channels[2],
out_channels=self.out_channels,
kernel_size=1,
weight_attr=ParamAttr(initializer=weight_attr),
bias_attr=False)
self.in5_conv = nn.Conv2D(
in_channels=in_channels[3],
out_channels=self.out_channels,
kernel_size=1,
weight_attr=ParamAttr(initializer=weight_attr),
bias_attr=False)
self.p5_conv = nn.Conv2D(
in_channels=self.out_channels,
out_channels=self.out_channels // 4,
kernel_size=3,
padding=1,
weight_attr=ParamAttr(initializer=weight_attr),
bias_attr=False)
self.p4_conv = nn.Conv2D(
in_channels=self.out_channels,
out_channels=self.out_channels // 4,
kernel_size=3,
padding=1,
weight_attr=ParamAttr(initializer=weight_attr),
bias_attr=False)
self.p3_conv = nn.Conv2D(
in_channels=self.out_channels,
out_channels=self.out_channels // 4,
kernel_size=3,
padding=1,
weight_attr=ParamAttr(initializer=weight_attr),
bias_attr=False)
self.p2_conv = nn.Conv2D(
in_channels=self.out_channels,
out_channels=self.out_channels // 4,
kernel_size=3,
padding=1,
weight_attr=ParamAttr(initializer=weight_attr),
bias_attr=False)
def forward(self, x):
c2, c3, c4, c5 = x
in5 = self.in5_conv(c5)
in4 = self.in4_conv(c4)
in3 = self.in3_conv(c3)
in2 = self.in2_conv(c2)
out4 = in4 + F.upsample(
in5, scale_factor=2, mode="nearest", align_mode=1) # 1/16
out3 = in3 + F.upsample(
out4, scale_factor=2, mode="nearest", align_mode=1) # 1/8
out2 = in2 + F.upsample(
out3, scale_factor=2, mode="nearest", align_mode=1) # 1/4
p5 = self.p5_conv(in5)
p4 = self.p4_conv(out4)
p3 = self.p3_conv(out3)
p2 = self.p2_conv(out2)
p5 = F.upsample(p5, scale_factor=8, mode="nearest", align_mode=1)
p4 = F.upsample(p4, scale_factor=4, mode="nearest", align_mode=1)
p3 = F.upsample(p3, scale_factor=2, mode="nearest", align_mode=1)
fuse = paddle.concat([p5, p4, p3, p2], axis=1)
return fuse
DBhead 可微二值化
import math
import paddle
from paddle import nn
import paddle.nn.functional as F
from paddle import ParamAttr
# 1. 从PaddleOCR中imort DBHead
from ppocr.modeling.heads.det_db_head import DBHead
import paddle
# 2. 计算DBFPN网络输出结果
fake_inputs = paddle.randn([1, 3, 640, 640], dtype="float32")
model_backbone = MobileNetV3()
in_channles = model_backbone.out_channels
model_fpn = DBFPN(in_channels=in_channles, out_channels=256)
outs = model_backbone(fake_inputs)
fpn_outs = model_fpn(outs)
# 3. 声明Head网络
model_db_head = DBHead(in_channels=256)
# 4. 打印DBhead网络
print('DBhead网络模型',model_db_head)
# 5. 计算Head网络的输出
db_head_outs = model_db_head(fpn_outs)
print(f"The shape of fpn outs {fpn_outs.shape}")
print(f"The shape of DB head outs {db_head_outs['maps'].shape}")
DBhead类函数构建:
class DBHead(nn.Layer):
"""
Differentiable Binarization (DB) for text detection:
see https://arxiv.org/abs/1911.08947
args:
params(dict): super parameters for build DB network
"""
def __init__(self, in_channels, k=50, **kwargs):
super(DBHead, self).__init__()
self.k = k
binarize_name_list = [
'conv2d_56', 'batch_norm_47', 'conv2d_transpose_0', 'batch_norm_48',
'conv2d_transpose_1', 'binarize'
]
#transpose转置 BN归一化标准化
thresh_name_list = [
'conv2d_57', 'batch_norm_49', 'conv2d_transpose_2', 'batch_norm_50',
'conv2d_transpose_3', 'thresh'
]
self.binarize = Head(in_channels, binarize_name_list, **kwargs)
self.thresh = Head(in_channels, thresh_name_list, **kwargs)
#计算时采用的网络层不一样。
def step_function(self, x, y):
#将标准二值化进行可微分化 1/(1+exp(-k*(x-y)))可微二值化
#k为增益因子,根据经验k一般取值为50. x为上文得到的概率图 y为上文得到的阈值图
return paddle.reciprocal(1 + paddle.exp(-self.k * (x - y)))
def forward(self, x, targets=None):
shrink_maps = self.binarize(x) #计算上文二值化概率图
if not self.training:
return {'maps': shrink_maps}
threshold_maps = self.thresh(x) #计算上文阈值图
#将上文阈值概率图与二值图进行计算。
binary_maps = self.step_function(shrink_maps, threshold_maps)
#然后将得到的三个值进行拼接,返回最终的结果。
y = paddle.concat([shrink_maps, threshold_maps, binary_maps], axis=1)
return {'maps': y}
- 建议可以下载代码运行一下,最主要的还是要看懂代码的实现原理以及网络的构建过程。今天的学习就到这里了,下次见。
源码地址: 链接