【论文笔记】—曝光不足图像增强—Supervised—DeepUPE—2019-CVPR
参考笔记:阅读笔记Underexposed Photo Enhancement using Deep Illumination Estimation_YongjieShi的博客-CSDN博客
弱光图像和曝光不足图像的区别?弱光是客观的,是自然的现实存在。曝光不足是主观的,是技术问题。
【论文介绍】
在网络中引入中间光照,将输入与预期的增强结果相关联。
和以往的图像到图像的生成不太一样,这篇文章首先产生了三个亮度的通道,用这三个亮度的通道的逆去乘原图像,得到的最后增强之后的图像。
【题目】:Underexposed photo enhancement using deep illumination estimation
【DOI】:10.1109/cvpr.2019.00701
【会议】:2019-CVPR
【作者】:Ruixing Wang, Qing Zhang, Chi-Wing Fu, Xiaoyong Shen, Wei-Shi Zheng, Jiaya Jia
【paper】:https://openaccess.thecvf.com/content_CVPR_2019/papers/Wang_Underexposed_Photo_Enhancement_Using_Deep_Illumination_Estimation_CVPR_2019_paper.pdf
【video】:https://www.youtube.com/watch?v=h2Ve268bYcE&t=3153s
【code_TensorFlow】:https://github.com/Jia-Research-Lab/DeepUPE【创新点】
- 网络:提出了一个端到端的用于欠曝光图像增强的网络结构,相对于图像到图像的预测,这个网络只image-to-illumination的预测。
- loss函数:设计了基于不同illumination的约束和先验的loss函数。
- 数据集:作者搞了一个数据集合,有三千张欠曝光的图像,并且作者请了一些专家进行修饰。
【图像增强模型】

其中 I 是未增强的图片,~I 是增强之后的图像,相当于是对正常曝光的图。
和以往的图像到图像的生成不太一样,这篇文章首先产生了三个亮度的通道,用这三个亮度的通道的逆去乘原图像,得到的最后增强之后的图像。

作者专门解释了一下这个公式为什么work,作者说重要的优点是,亮度图比较简单,而且其中还蕴含着先验知识,如果输出亮度图的话,实际上网络有很强的泛化能力来学到不同光照条件下的复杂的摄影调整。除此之外,通过对illumination map 建立约束,模型也能够定制增强之后的结果。比如,通过约束 illumination map 的局部光滑,对比度可以得到增强,或者 通过约束亮度图的幅度,可以调整增强之后的结果。
【网络结构】
网络结构包含一个local和一个global的模块,能够获取不同尺度的信息,然后因为输出尺寸的比较小,所以能够保证效率的问题。
首先,对输入进行下采样并将其编码到特征图中,提取局部和全局特征,并将其串联以通过卷积层预测低分辨率照明。
然后,对结果进行上采样以产生全分辨率多通道照明S (热色图),并将其用于恢复全分辨率增强图像。
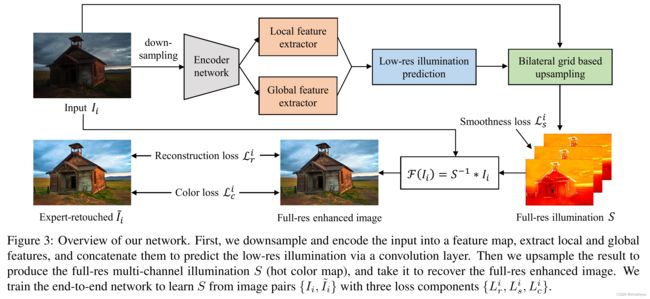
- 增强曝光不足的照片需要同时调整局部特征(如对比度、细节锐度、阴影和高光)和全局特征(如颜色分布、平均亮度和场景类别)。从编码器网络产生的特性来考虑局部和全局环境,参见图3顶部。
- 为了驱动网络从输入的低曝光图像 Ii 和相应的专家修饰的图像 ~Ii 中学习光照映射,我们设计了一个损失函数smooth loss ,该函数对光照具有先验的平滑性,对增强图像具有重建和颜色损失,参见图3底部。
- 这些策略从 ( I, ~I) 有效地学习S,通过丰富的摄影调整来恢复增强后的图像。
【损失函数】
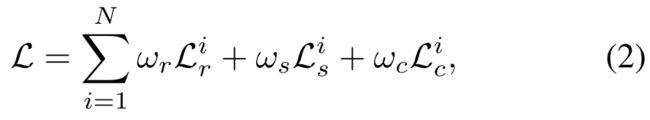
重建的loss:
就是直接比较两幅图像的接近程度:
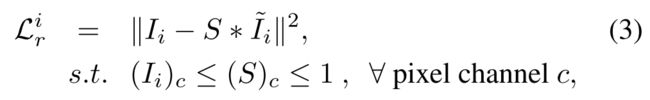
smooth loss:
就是为了对输出的亮度图进行一个光滑,这是基于两篇文章提出来的理论,表述的是亮度应该是局部光滑(locally smooth)的。
smooth loss有两个优点:第一个是可以减少过拟合和增加网络的泛化能力;第二个优点是它可以增加图像的对比度。
作者举了一个例子,比如p和q有相似的亮度的话,那么经过s变换之后,这个在亮度图上的差异应该会被放大,所以需要对这个亮度图进行约束:
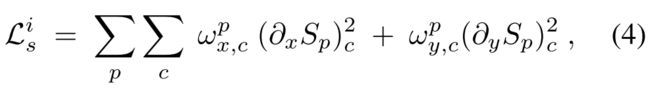
其中,
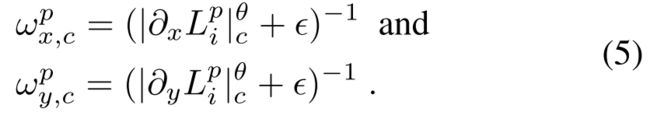
大致的意思是,如果原图的某个pixel比较smooth的话,那么这一项的loss的系数就会很大,如果原图的某个pixel很sharp的话,那么它对应的亮度图对应的像素的系数会很小。就是如果原图很smooth的话,得到的亮度图应该也是smooth的,如果原图是sharp的话,那么对应的亮度图也应该是sharp的。作者还说道,对于曝光不足的图片,图像内容和细节通常较弱,照明不一致会导致大的梯度。
color loss:
就是计算对应pixel(RGB三通道表示的三维向量)的余弦距离,作者说L2 norm只能够测量两个向量之间的距离,不能够保证他们的方向是一致的,不能够保证color vector有一致的方向,所以L2度量方式可能导致明显的 color mismatch。
这个读者感觉这个地方考虑的是角度相似性的问题,比如预测得到的 rgb 三个通道的向量如果只是和原图的 rgb 相差一个 scale 的话,那么应该余弦距离是为0的,但是只差一个 scale 就是只差一个亮度,这种做法能够保证优化的方向是一致的,至于具体的距离可以交给L2 norm。
【数据集】
MIT-Adobe FiveK dataset,这个数据集合有一个缺点就是它只用来做普通的图片的数据增强而不是欠曝光的图像的数据增强。
所以作者准备做的这个问题,之前没有过类似的数据集合,作者用EOS 5D相机来拍摄图片,同时,在Flicker这个网站上也收集了大约15%的图片,搜索的关键词欠曝光,低光,或者backit等关键词。然后作者说他们雇佣了3个专家来用 adobe 的 lightroom 调整图像,用调整之后的图像作为gt进行训练。作者的数据集合包含各种各样的场景,包含了各种各样的亮度。总的来讲,作者的3000张图片中,有2750张图片用来做训练,250张图片用来做测试。作者现在还没有公开训练数据,只公开了测试数据。
低照度图像数据集_chaikeya的博客-CSDN博客_低光数据集
【实验结果】

作者说他们的网络也有一些局限性,比如在非常暗的环境下并不能恢复出来detail,我感觉emm因为训练数据不够用呗~
还有就是去噪能力不够,感觉训练数据都是非常clean的,除了暗之外,所以这里的shortcoming,感觉意义不是特别大.