使用 OpenCV与 HAAR 级联算法进行人脸检测和人脸识别
AI人脸识别是一种从数字图像或视频帧中识别或验证人脸的技术。人类可以毫不费力地快速识别面部。这对我们来说是一项轻松的任务,但对计算机来说却是一项艰巨的任务。因为存在各种复杂性,例如低分辨率、遮挡、光照变化等。这些因素高度影响计算机更有效地识别人脸的准确性。首先要了解人脸检测和人脸识别的区别。
人脸检测:人脸检测通常被认为是在图像中找到人脸(位置和大小),并可能提取它们以供人脸检测算法使用。
人脸识别:人脸识别算法用于查找图像中唯一描述的特征。人脸图像已经被提取、裁剪、调整大小,并且通常在灰度中进行转换。
人脸检测和人脸识别有多种算法。在这里,我们将学习使用 HAAR 级联算法进行人脸检测。
HAAR级联算法基本概念
HAAR 级联是一种机器学习方法,其中级联函数是从大量正面和负面图像中训练出来的。正图像是由人脸组成的图像,负图像是没有人脸的图像。在人脸检测中,图像特征被视为从图片中提取的数字信息,可以将一幅图像与另一幅图像区分开来。
我们将算法的每个特征应用于所有训练图像。每个图像在开始时都被赋予相等的权重。它找到了将面部分类为正面和负面的最佳阈值。可能存在错误和错误分类。 我们选择错误率最小的特征,这意味着这些特征是对人脸和非人脸图像进行最佳分类的特征。
每个内核的所有可能大小和位置都用于计算大量特征。
OpenCV 中的 HAAR 级联检测
OpenCV 提供训练器和检测器。级联图像分类器有两种主要状态,一种是训练,另一种是检测。
OpenCV 提供了两个应用程序来训练级联分类器 opencv_haartraining 和 opencv_traincascade。 这两个应用程序以不同的文件格式存储分类器。
对于训练,我们需要一组样本。有两种类型的样本:
- 负样本:与非目标图像有关。
- 正样本:与检测对象相关的图像。
一组负样本必须手动准备,而正样本集合是使用 opencv_createsamples 实用程序创建的。
负样本
负样本取自任意图像。 负样本添加到文本文件中。文件的每一行都包含一个负样本的图像文件名(相对于描述文件的目录)。该文件必须手动创建。定义的图像可能具有不同的大小。
正样本
正样本由 opencv_createsamples 实用程序创建。 这些样本可以从带有对象的单个图像或早期集合中创建。 重要的是要记住,在将其提供给上述实用程序之前,我们需要大量正样本数据集,因为它仅应用透视变换。
这里我们将讨论人脸检测。OpenCV 已经包含各种针对面部、眼睛、微笑等的预训练分类器。这些 XML 文件存储在 opencv/data/haarcascades/ 文件夹中。让我们了解以下步骤:
- 步骤 - 1
首先,我们需要加载必要的 XML 分类器并以灰度模式加载输入图像(或视频)。
- 步骤 - 2
将图像转换为灰度后,我们可以进行图像处理,如果需要,可以调整图像大小、裁剪、模糊和锐化。下一步是图像分割;识别单个图像中的多个物体,因此分类器可以快速检测出图片中的物体和人脸。
- 步骤 - 3
haar-Like 特征算法用于寻找人脸在帧或图像中的位置。所有的人脸都有一些共同的人脸特性,比如眼睛区域比它的邻居像素更暗,鼻子区域比眼睛区域更亮。
- 步骤 - 4
在这一步中,我们借助边缘检测、线检测和中心检测从图像中提取特征。然后提供x、y、w、h的坐标,就在图片中形成一个矩形框来表示人脸的位置。它可以在检测到人脸的所需区域中制作一个矩形框。
使用 OpenCV 进行人脸识别
人脸识别对人类来说是一项简单的任务。成功的人脸识别往往是对内在特征(眼睛、鼻子、嘴巴)或外在特征(头、脸、发际线)的有效识别。这里的问题是:人类大脑如何编码它?
David Hubel 和 Torsten Wiesel 表明,我们的大脑具有专门的神经细胞,可以对场景的独特局部特征(例如线条、边缘角度或运动)做出反应。我们的大脑将不同的信息来源组合成有用的模式;我们不认为视觉是分散的。如果我们用简单的词来定义人脸识别,“自动人脸识别就是从图像中取出那些有意义的特征并将它们放入有用的表示中,然后对它们进行一些分类”。
人脸识别的基本思想是基于人脸的几何特征。这是人脸识别最可行、最直观的方法。第一个自动人脸识别系统是在眼睛、耳朵、鼻子的位置进行描述的。这些定位点称为特征向量(点之间的距离)。
人脸识别是通过计算探针和参考图像的特征向量之间的欧几里德距离来实现的。这种方法本质上在光照变化方面是有效的,但它有一个相当大的缺点。正确注册非常困难。
人脸识别系统基本上可以在两种模式下运行:
- 面部图像的认证或验证-
它将输入的面部图像与用户相关的面部图像进行比较,这需要进行身份验证。 这是一个 1x1 的比较。
- 身份识别或面部识别
它基本上比较来自数据集的输入面部图像,以找到与该输入面部匹配的用户。 这是一个 1xN 的比较。
有多种类型的人脸识别算法,例如:
- 特征脸(Eigenfaces )
- 局部二元模式直方图(Local Binary Patterns Histograms,LBPH)
- Fisherfaces
- Scale Invariant Feature Transform (SIFT)
- 加速鲁棒特征(Speed Up Robust Features ,SURF)
每种算法都遵循不同的方法来提取图像信息并与输入图像进行匹配。 在这里,我们将讨论局部二进制模式直方图 (LBPH) 算法,它是最古老和流行的算法之一。
LBPH介绍
局部二进制模式直方图算法是一种简单的方法,它标记图像的像素,并对每个像素的邻域进行阈值处理。 换句话说,LBPH 通过将每个像素与其相邻像素进行比较来总结图像中的局部结构,并将结果转换为二进制数。 它于 1994 年 (LBP) 首次定义,从那时起它被发现是一种强大的纹理分类算法。
该算法通常侧重于从图像中提取局部特征。 基本思想不是将整个图像视为一个高维向量; 它只关注对象的局部特征。
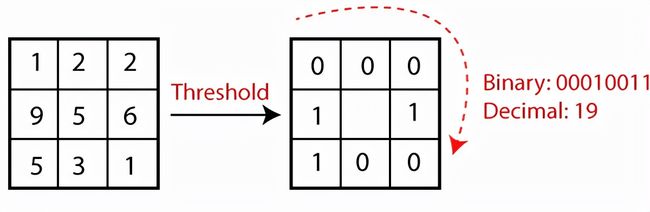
在上图中,以像素为中心并对其邻居设置阈值。 如果中心像素的强度大于等于它的邻居,则用 1 表示它,否则用 0 表示它。
我们来了解一下算法的步骤:
1. 选择参数:LBPH 接受四个参数:
- 半径:表示围绕中心像素的半径。 它通常设置为 1。它用于构建圆形局部二进制模式。
- Neighbors:构建圆形二进制模式的样本点数。
- Grid X:水平方向的单元格数。 细胞越多,网格越细,得到的特征向量的维数就越高。
- Grid Y:垂直方向的单元格数。 细胞越多,网格越细,得到的特征向量的维数就越高。
2. 训练算法:第一步是训练算法。 它需要一个包含我们想要识别的人的面部图像的数据集。 每个图像都应该提供一个唯一的 ID(它可能是一个人的号码或姓名)。然后算法使用此信息来识别输入图像并为您提供输出。 特定人物的图像必须具有相同的 ID。让我们了解下一步中的 LBPH 计算。
3. 使用LBP操作:在这一步中,LBP计算用于创建中间图像,通过突出面部特征以特定方式描述原始图像。 参数半径和邻居用于滑动窗口的概念。

为了更具体的理解,让我们把它分成几个小步骤:
- 假设输入的面部图像是灰度的。
- 我们可以得到这个图像的一部分,作为一个 3x3 像素的窗口。
- 我们可以使用包含每个像素(0-255)强度的 3x3 矩阵。
- 然后,我们需要取矩阵的中心值作为阈值。
- 该值将用于定义来自 8 个邻居的新值。
- 对于中心值(阈值)的每个邻居,我们设置一个新的二进制值。值 1 设置为等于或高于阈值,0 设置为低于阈值的值。
- 现在矩阵将只包含二进制值(跳过中心值)。我们需要将矩阵中每个位置的每个二进制值逐行处理成新的二进制值 (10001101)。还有其他方法可以连接二进制值(顺时针方向),但最终结果将相同。
- 我们将此二进制值转换为十进制值并将其设置为矩阵的中心值,即原始图像中的一个像素。
- 在完成 LBP 过程后,我们得到了新图像,它代表了原始图像更好的特征。

4.从图像中提取直方图:图像是在最后一步生成的,我们可以使用Grid X和Grid Y参数将图像划分为多个网格,让我们考虑下图:

- 我们有一个灰度图像; 每个直方图(来自每个网格)将只包含 256 个位置,代表每个像素强度的出现。
- 需要通过连接每个直方图来创建一个新的更大的直方图。
5. 执行人脸识别:现在,算法训练有素。 提取的直方图用于表示训练数据集中的每个图像。 对于新图像,我们再次执行步骤并创建新的直方图。要找到与给定图像匹配的图像,我们只需要匹配两个直方图并返回具有最接近直方图的图像。
- 比较直方图的方法有很多种(计算两个直方图之间的距离),例如:欧氏距离、卡方、绝对值等,我们可以使用基于以下公式的欧氏距离:

- 该算法将返回 ID 作为具有最接近直方图的图像的输出。该算法还应返回计算出的距离,这可以称为置信度测量。 如果置信度低于阈值,则表示算法已成功识别人脸。
在本文中,我们已经讨论了关于人脸检测和人脸识别的工作原理,这里总结下:
- haar类级联算法用于人脸检测。
- 人脸识别的算法有很多种,其中LBPH是一种简单而流行的算法。
- 它通常关注图像中的局部特征。
拓展阅读
我们TSINGSEE青犀视频的研发人员近期也在积极开发人脸检测、人脸识别、人流量统计、安全帽检测等AI技术,并积极融入到现有的视频平台中。典型的示例如EasyCVR视频融合云服务,具有AI人脸识别、车牌识别、语音对讲、云台控制、声光告警、监控视频分析与数据汇总的能力,广泛应用在小区、楼宇的智能门禁,周界可疑人员徘徊检测、景区人流量统计等场景中。