2021年大数据面试宝典完整版(含答案解析)
本文转载自微信公众号《大数据私房菜》,原文章链接为:https://mp.weixin.qq.com/s/0mgy07WAMBYNBP6er8_hDA
| 版本 | 更新时间 | 更新内容 |
| v1.0 | 2020-07-01 | 新建 |
| v1.1 | 2020-07-18 | 朋友面试大数据工程师提供的关于架构及数仓方面的题目 |
| v1.2 | 2020-08-08 | 朋友面试数据专家提供的数据驱动,spark及flink方面面试题 |
| v1.3 | 2020-08-22 | 朋友面试数据开发提供的关于hive及数仓方面的题目 |
| v1.4 | 2020-09-06 | 老徐提供面试题(数仓方向)及朋友提供数据开发面试题(离线+实时) |
| v1.5 | 2020-09-13 | 新增kafka面试题及答案 |
| v1.6 | 2020-10-19 | 新增数仓面试题及flink开发面试题 |
| v1.7 | 2020-11-16 | 新增某厂大数据开发岗面试题 |
| v1.8 | 2020-12-27 | 新增数据仓库,大数据开发面试题 |
| v1.9 | 2021-01-01 | 新增数据仓库开发工程师面试题 |
| v2.0 | 2021-03-14 | 新增数据仓库面试题 |
一、数据仓库
1.维表和宽表的考查(主要考察维表的使用及维度退化手法)
维表数据一般根据ods层数据加工生成,在设计宽表的时候,可以适当的用一些维度退化手法,将维度退化到事实表中,减少事实表和维表的关联
2.数仓表命名规范
OneData方法论在XX的实践
3.拉链表的使用场景
你真的了解全量表,增量表及拉链表吗?
4.数据库和数据仓库有什么区别
数据库和数据仓库
5.有什么维表
时间维表,用户维表,医院维表等
6.数据源都有哪些
业务库数据源:mysql,oracle,mongo
日志数据:ng日志,埋点日志
爬虫数据
7.你们最大的表是什么表,数据量多少
ng日志表,三端(app,web,h5)中app端日志量最大,清洗入库后的数据一天大概xxxxW
8.数仓架构体系
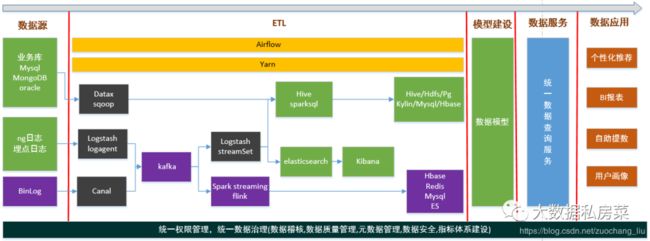
9.数据平台是怎样的,用到了阿里的那一套吗?
没用到阿里那一套,数据平台为自研产品
10.你了解的调度系统有那些?,你们公司用的是哪种调度系统
airflow,azkaban,ooize,我们公司使用的是airflow
11.你们公司数仓底层是怎么抽数据的?
业务数据用的是datax
日志数据用的是logstash
12.为什么datax抽数据要比sqoop 快?
Sqoop or Datax
13.埋点数据你们是怎样接入的
logstash-->kafka-->logstash-->hdfs
14.如果你们业务库的表有更新,你们数仓怎么处理的?
你真的了解全量表,增量表及拉链表吗?
15.能独立搭建数仓吗
可以
16.搭建过CDH 集群吗
搭建过
17.说一下你们公司的大数据平台架构?你有参与吗?
18.介绍一下你自己的项目和所用的技术
19.对目前的流和批处理的认识?就是谈谈自己的感受
目前流处理和批处理共存,主要是看业务需求,批处理相对于流处理来说更稳定一点,但是未来肯定是流批一体的状态
20.你了解那些OLAP 引擎,MPP 知道一些吗?clickHouse 了解一些吗?你自己做过测试性能吗?
关于OLAP引擎-Kylin,你不得不知道的事
21.Kylin 有了解吗?介绍一下原理
关于OLAP引擎-Kylin,你不得不知道的事
22.datax 源码有改造过吗
Datax-数据抽取同步利器
23.你们数仓的APP 层是怎么对外提供服务的?
1.直接存入mysql业务库,业务方直接读取
2.数据存入mysql,以接口的形式提供数据
3.数据存入kylin,需求方通过jdbc读取数据
24.数据接入进来,你们是怎样规划的,有考虑数据的膨胀问题吗
会根据表数据量及后续业务的发展来选择数据抽取方案,会考虑数据膨胀问题,所以一般选用增量抽取的方式
25.简述拉链表,流水表以及快照表的含义和特点
你真的了解全量表,增量表及拉链表吗?
26.全量表(df),增量表(di),追加表(da),拉链表(dz)的区别及使用场景
你真的了解全量表,增量表及拉链表吗?
27.你们公司的数仓分层,每一层是怎么处理数据的
数据仓库分层架构
28.什么是事实表,什么是维表
数据仓库中的维表和事实表
29.星型模型和雪花模型
全方位解读星型模型,雪花模型及星座模型
30.缓慢变化维如何处理,几种方式
缓慢变化维(SCD)常见解决方案
31.datax与sqoop的优缺点
Sqoop or Datax
32.datax抽数碰到emoji表情怎么解决
我记得datax抽取碰到表情是能正常抽过来并展示的,在同步到Mysql的时候需要修改编码
33.工作中碰到什么困难,怎么解决的
从0-1建设数仓遇到什么问题?怎么解决的?
34.如何用数据给公司带来收益
35.需求驱动和业务驱动,数据开发和ETL开发,实战型和博客型
需求驱动还是业务驱动
36.如何用数据实现业务增长?
了解一下增长黑客
37.什么是大数据?千万级别的数据完全可以用传统的关系型数据库集群解决,为什么要用到大数据平台。
大数据(big data),IT行业术语,是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
传统关系型数据库很难做数据治理,而且需要考虑到业务发展带来数据的海量增长,所以需要搭建大数据平台来支撑。
38.数据质量,元数据管理,指标体系建设,数据驱动
数据质量那点事
简述元数据管理
39.什么是数仓,建设数仓时碰到过什么问题
从0-1建设数仓遇到什么问题?怎么解决的?
40.实时数仓技术选型及保证exactly-once
flink+kafka+clickhouse
41.维度建模和范式建模的区别;
全方位解读星型模型,雪花模型及星座模型
42.埋点的码表如何设计;
埋点平台输入,存储在msql,字段页面ID,点位规则唯一ID,点位名称,点位事件,私有参数等
43.集市层和公共层的区别;
公共层与数据集市层的区别
44.缓慢变化维的处理方式
缓慢变化维(SCD)常见解决方案
45.聊聊数据质量
数据质量那点事
46.说说你从0-1搭建数仓都做了什么?你觉得最有挑战的是什么?
从0-1建设数仓遇到什么问题?怎么解决的?
47.数据模型如何构建,星型、雪花、星座的区别和工作中如何使用;
全方位解读星型模型,雪花模型及星座模型
48.如何优化整个数仓的执行时长,比如7点所有任务跑完,如何优化到5点;
如何优化整个数仓的执行时长(比如7点所有任务跑完,如何优化到5点)
49.数据倾斜,遇到哪些倾斜,怎么发现的?怎么处理的?;
Hive调优,数据工程师成神之路
50.如何保证数据质量;
数据质量那点事
51.如何保证指标一致性;
指标体系建设
52.了解onedata吗,说说你的理解;
OneData方法论在XX的实践
53.数据漂移如何解决;
可以看看大数据之路
54.实时场景如何解决的;
实时计算
55.拉链表如何设计,拉链表出现数据回滚的需求怎么解决。
你真的了解全量表,增量表及拉链表吗?
56.平台选型依据
根据业务及需求
57.数仓分层、模型、每层都是做什么的?为什么这么做?
数据仓库分层架构
58.交叉维度的解决方案?
多值维度及交叉维度最佳解决方案
59.数据质量如何保证(DQC)?
数据质量那点事
60.任务延迟如何优化(SLA)?
如何优化整个数仓的执行时长(比如7点所有任务跑完,如何优化到5点)
Hive调优,数据工程师成神之路
61.聊一下数据资产。
OneData方法论在XX的实践
62.如果让你设计实时数仓你会如何设计,为什么?
flink+kafka+clickhouse,jiansflink+kafka+clickhouse
63.指标如何定义?
64.sql问题:连续活跃n天用户的获取;
大厂高频面试题-连续登录问题
65.数据倾斜的sql如何优化;数据量大的sql如何优化?
Hive调优,数据工程师成神之路
66.数据仓库主题的划分
参考Teradata的LDM模型;
67.Kimball和Inmon的相同和不同;
Kimball架构和Inmon架构
68.数据质量管理、数据治理有什么好的方案?知识库管理有什么好的思路?血缘关系图。
简述元数据管理
数据质量那点事
江湖传言:数据玩的溜,牢饭吃的久?
69.元数据管理相关问题,集群存储不够了,需要清理不需要的任务和数据该怎么做?
简述元数据管理
70.业务库2亿数据入仓的策略
全量初始化,之后每次增量;
71.什么场景会出现数据倾斜,怎么解决?比如select user_id,count(1) from table group by user_id,其中某些user_id的访问量很大,查询不出结果该怎么办?
Hive调优,数据工程师成神之路
72.sql里面on和where有区别吗?
left join(on&where)
73.聊一下技术架构,整个项目每个环节用的什么技术这个样子;
74.hive、hbase、spark。。。。这些大数据组件,熟悉哪个或者哪些?我说hive和hbase,对方就问hive和hbase的原理,差异等问题;
一文带你走进HIVE的世界(1.8W字建议收藏)
你要悄悄学会HBase,然后惊艳所有人(1.7万字建议收藏)
75.有没有实时数仓的经验,数据实时入仓思路
canal+kafka+flink+clickhouse+redis
76.你对当前的项目组有没有什么自己的看法、意见或者需要改进的地方,这个改进对你有没有什么影响
根据个人实际情况回答即可
77.ods的增量能否做成通用的?
题目不明确
78.公共层和数据集市层的区别和特点?
公共层与数据集市层的区别
79.从原理上说一下mpp和mr的区别
MPP跑的是SQL,而Hadoop底层处理是MapReduce程序。
MPP虽然是宣称可以横向扩展Scale OUT,但是这种扩展一般是扩展到100左右,而Hadoop一般可以扩展1000+。
MPP数据库有对SQL的完整兼容和一些事务的处理能力,对于用户来说,在实际的使用场景中,如果数据扩展需求不是特别大,需要的处理节点不多,数据都是结构化的数据,习惯使用传统的RDBMS的很多特性的场景,可以考虑MPP,例如Greenplum/Gbase等。
如果有很多非结构化数据,或者数据量巨大,有需要扩展到成百上千个数据节点需求的,这个时候Hadoop是更好的选择。
80.对了中间还有问数仓数据的输出主要是哪些还有数仓的分层;
数据仓库分层架构
81.报表如何展示
自研报表系统
powerBI
tableau
82.数据源,怎么同步,同步时对业务库的性能影响,同步后怎么处理,使用方是谁,怎么使用
datax同步后清洗,分层建模
使用方是各个团队,搜索,运营,分析师等
83.你们数仓怎么分层的以及各层主要做了什么
数据仓库分层架构
84.你们主题是怎么划分的,举个例子
根据实际业务回答
85.如何判断一个模型的好坏
如何判断一个数据模型的好坏
86.你们需求的开发流程是什么样的
一文探究数据仓库体系(2.7万字建议收藏)
87.如何判定一个表是事实表还是维度表?
数据仓库中的维表和事实表
88.数据建模过程说一下?
数据建模知多少?
89.三范式知道吗,说一下?
数据库三范式简单介绍
90.数据仓库模型建设可以使用范式建模吗,你是怎么看的?
可以,但是一般不会使用
91.缓慢变化维处理方式?
缓慢变化维(SCD)常见解决方案
92.大宽表的优点与缺点?
面试官:说一下数仓宽表的优缺点吧
93.拉链表的实现逻辑说一下?
你真的了解全量表,增量表及拉链表吗?
94.你们开发规范是怎样的?
一文探究数据仓库体系(2.7万字建议收藏)
95.你们公司有哪些主题?
用户,财务,订单等
96.日志采集有没做过?
做过
97.流量域一般怎么做?
日志采集,清洗,建模,指标统计
98.路径分析怎么做?
99.如果你的代码运行很慢,你会怎么开始排查?
从服务器资源,数据量,执行引擎,数据倾斜,sql调优,执行计划等去作答
100.你们数据量大概有多大?
根据实际情况回答
101.你们数仓怎么分层的以及各层主要做了什么
数据仓库分层架构
102.你们主题是怎么划分的,举个例子
根据实际情况回答
103.如何判断一个模型的好坏
如何判断一个数据模型的好坏
104.你们需求的开发流程是什么样的
一文探究数据仓库体系(2.7万字建议收藏)
105.ETL过程中,你们数据质量是怎么保证的
数据质量那点事
106.datax源码有没有看过
看过
107.用phenix和es作为hbase二级索引的区别,最新的hbase已经支持二级索引了,你清楚吗?
108.主题域是怎么划分的?
根据公司实际情况作答
109.脏数据怎么处理?
根据公司实际情况作答
110.怎么进行数据建模?
数据建模知多少?
111.实时数据是否有了解,过程是什么
可以说一下实时计算或者实时数仓
112.星型建模和雪花建模的区别
全方位解读星型模型,雪花模型及星座模型
113.如何计算新用户和老用户?
根据设备id和登录id去判断
114.你们这边数据量有多少呢,就是从ods到ads层一共多少数据量?
根据实际情况回答
115.拉链表如果有一天的数据错了,比如说到12月15号,但是发现11月10号拉链的数据错了,导致后续拉链的结果都错了,这个应该怎么修正
116.Parquet和Orc和Rc的比较?
在我们当前的数据集和hive版本环境下,在文件写入方面,ORC相比RC文件的优势不显著,一些场合RC文件还要更优,在查询检索方面,ORC则基本是更优的,性能差距大小取决于具体数据集和检索模式。如果Hive能集成ORC更新的版本,支持LZ4,并修复一些Bug,那应该就没有任何再使用RC的理由了。
至于Parquet,可以考虑在需要支持深度嵌套的数据结构的应用场合中去使用
117.列式存储是什么?行数比较大的情况,比如说上亿,那么列式存储是怎么做的?列式存储是为了解决什么问题?
118.dwd层有多少张表,每张表多少数据量
根据实际情况回答
119.null值怎么打散,打散的伪代码或者sql
Hive调优,数据工程师成神之路
120.如果一张表的某个字段作为join的字段,但是这个字段有倾斜的非常厉害,比如性别这个字段,有男1000万个,女5万,这时候数据倾斜如何解决?
121.一天多少任务,多少表
根据实际情况回答
122.什么技术进行存储
123.内外部表的区别、优缺点
Hive内部表外部表区别及各自使用场景
124.数据存在hdfs上会有压缩吗?有什么优缺点?
125.hdfs为什么会比较厌恶小文件
Hive调优,数据工程师成神之路
126.数据源是来自于哪里
业务库,日志数据
127.数据倾斜问题
Hive调优,数据工程师成神之路
128.二次聚合对uv的话有没有什么问题
对pv没影响,对uv有影响,会重复
129.数仓的搭建
一文探究数据仓库体系(2.7万字建议收藏)
130.分工 角色
根据实际情况回答
131.分层怎么分的
数据仓库分层架构
132.sqoop怎么解决数据变动的问题
133.维度退化具体的内容
部分维度直接加在模型中,减少关联
134.每天的数据量
根据实际情况回答
135.你们有主题的概念吗?
有的,建模就是按照主题划分
136.主题的划分原则
137.7日的留存率怎么求?
138.有一些任务需要回溯,就是比如说历史时间需要重新执行,有遇到这种情况吗?
139.核心指标都有哪些?
140.怎么保证每天能在固定的时间数据产出?
141.数仓建模的方式?
数据建模知多少?
142.模型的选取?
维度建模
143.怎么识别抖音中的大学生用户?用什么数据识别
144.建立数据仓库的一般流程,你的思路是什么
一文探究数据仓库体系(2.7万字建议收藏)
145.数据清洗做过没?
做过
146.离线方面碰到什么困难
技术选型
开发规范
口径统一
...
147.数据倾斜怎么优化
Hive调优,数据工程师成神之路
148.数仓为什么是五层?(简历上写五层)
数据仓库分层架构
149.dwd,dws,dwt之间有什么区别?
数据仓库分层架构
150.dwd的表是全量的吗?为什么?
全量的
151.有一个订单表记录,根据你的数仓结构,说说怎么求出用户最近7天的最后一次下单记录?
152.自我介绍一下
如实介绍
153.你们业务库怎么同步到数仓的
datax
154.增量处理的逻辑说一下
你真的了解全量表,增量表及拉链表吗?
155.如果业务库修改了数据,但是更新时间没用修改,这个数据能抽过来吗?应该怎么处理
抽不过来,需要canal监控binlog日志
156.你们数据模型怎么建设的
kimball维度建模
157.你们数仓分层怎么分的,每层的作用?
数据仓库分层架构
158.你们使用宽表会有什么问题吗
面试官:说一下数仓宽表的优缺点吧
159.说一下最近的一个项目
如实说
160.这个项目你觉得哪里好
从技术架构和对公司的价值来说
161.数据治理这块你有参与吗?
数据质量那点事
简述元数据管理
162.元数据管理怎么做的?
163.数据质量管理你们怎么做的?
数据质量那点事
164.四个by的区别
深入探究order by,sort by,distribute by,cluster by的区别,并用数据征服你
165.hive中几个join的区别
left semi join和left join区别
166.你有什么想问我的吗
问问技术架构
问问工作内容
问问数据量
167.说一下日常工作中负责的一个主题建模过程
168.为什么要分层,每层的作用是什么
数据仓库分层架构
169.数仓分层的每层要注意什么
170.你们分层和阿里有点不一样,你们是怎么考虑的,你觉得阿里为什么那样分层
171.你们数据域怎么划分的
172.你们ads层怎么划分的
173.数仓宽表你怎么看
174.什么情况下回用到拉链表,拉链表的实现逻辑说一下
175.如何判断一个数据模型的好坏
176.判断数仓搭建的好坏,怎么评价
177.你们元数据管理怎么做的
178.元数据你们怎么应用的
179.数据血缘你们怎么做的
180.数据质量管理说一下,你们怎么做的
181.告警平台你们怎么做的,说一下
二、HIVE
1.大表join小表产生的问题,怎么解决?
大表join小表,独钟爱mapjoin
join因为空值导致长尾(key为空值是用随机值代替)
join因为热点值导致长尾,也可以将热点数据和非热点数据分开处理,最后合并
2.udf udaf udtf区别
HIVE之UDF函数开发
3.hive有哪些保存元数据的方式,个有什么特点。
-
内存数据库derby,安装小,但是数据存在内存,不稳定
-
mysql数据库,数据存储模式可以自己设置,持久化好,查看方便。
4.hive内部表和外部表的区别
Hive内部表外部表区别及各自使用场景
5.生产环境中为什么建议使用外部表?
Hive内部表外部表区别及各自使用场景
6.insert into 和 override write区别?
insert into:将数据写到表中
override write:覆盖之前的内容。
7.hive的判断函数有哪些
Hive常用函数
8.简单描述一下HIVE的功能?用hive创建表有几种方式?hive表有几种?
hive主要是做离线分析的
hive建表有三种方式
-
直接建表法
-
查询建表法(通过AS 查询语句完成建表:将子查询的结果存在新表里,有数据,一般用于中间表)
-
like建表法(会创建结构完全相同的表,但是没有数据)
hive表有2种:内部表和外部表
9.线上业务每天产生的业务日志(压缩后>=3G),每天需要加载到hive的log表中,将每天产生的业务日志在压缩之后load到hive的log表时,最好使用的压缩算法是哪个,并说明其原因

选择lzo,因为该压缩算法可切分,压缩率比较高,解压缩速度很快,非常适合日志
10.若在hive中建立分区仍不能优化查询效率,建表时如何优化
可以重新建表为分区分桶表
11.union all和union的区别
union 去重
union all 不去重
12.如何解决hive数据倾斜的问题
Hive调优,数据工程师成神之路
13.hive性能优化常用的方法
Hive调优,数据工程师成神之路
14.简述delete,drop,truncate的区别
delet 删除数据
drop 删除表
truncate 摧毁表结构并重建
15.order by , sort by , distribute by , cluster by的区别
深入探究order by,sort by,distribute by,cluster by的区别,并用数据征服你
16.Hive 里边字段的分隔符用的什么?为什么用\t?有遇到过字段里 边有\t 的情况吗,怎么处理的?为什么不用 Hive 默认的分隔符,默认的分隔符是什么?
hive 默认的字段分隔符为 ascii 码的控制符\001(^A),建表的时候用 fields terminated by '\001'
遇到过字段里边有\t 的情况,自定义 InputFormat,替换为其他分隔符再做后续处理
17.分区分桶的区别,为什么要分区
分区表:原来的一个大表存储的时候分成不同的数据目录进行存储。如果说是单分区表,那么在表的目录下就只有一级子目录,如果说是多分区表,那么在表的目录下有多少分区就有多少级子目录。不管是单分区表,还是多分区表,在表的目录下,和非最终分区目录下是不能直接存储数据文件的
分桶表:原理和hashpartitioner 一样,将hive中的一张表的数据进行归纳分类的时候,归纳分类规则就是hashpartitioner。(需要指定分桶字段,指定分成多少桶)
分区表和分桶的区别除了存储的格式不同外,最主要的是作用:
-
分区表:细化数据管理,缩小mapreduce程序 需要扫描的数据量。
-
分桶表:提高join查询的效率,在一份数据会被经常用来做连接查询的时候建立分桶,分桶字段就是连接字段;提高采样的效率。
有了分区为什么还要分桶?
(1)获得更高的查询处理效率。桶为表加上了额外的结构,Hive在处理有些查询时能利用这个结构。
(2)使取样( sampling)更高效。在处理大规模数据集时,在开发和修改査询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
分桶是相对分区进行更细粒度的划分。分桶将表或者分区的某列值进行hash值进行区分,如要安装name属性分为3个桶,就是对name属性值的hash值对3取摸,按照取模结果对数据分桶。
与分区不同的是,分区依据的不是真实数据表文件中的列,而是我们指定的伪列,但是分桶是依据数据表中真实的列而不是伪列
18.mapjoin的原理
大表join小表,独钟爱mapjoin
19.在hive的row_number中distribute by 和 partition by的区别
row_number() over( partition by 分组的字段 order by 排序的字段) as rank(rank 可随意定义表示排序的标识);
row_number() over( distribute by 分组的字段 sort by 排序的字段) as rank(rank 可随意定义表示排序的标识)
注意:
partition by 只能和order by 组合使用
distribute by 只能和 sort by 使用
20.hive开发中遇到什么问题?
Hive调优,数据工程师成神之路
21.什么时候使用内部表,什么时候使用外部表
Hive内部表外部表区别及各自使用场景
22.hive都有哪些函数,你平常工作中用到哪些
Hive常用函数
23.手写sql,连续活跃用户
大厂高频面试题-连续登录问题
24.left semi join和left join区别
left semi join和left join区别
25.group by为什么要排序
26.说说印象最深的一次优化场景,hive常见的优化思路
Hive调优,数据工程师成神之路
27.聊聊hive的执行引擎,spark和mr的区别?
引擎是mr,基于磁盘进行计算,比较慢
引擎是spark,基于内存进行计算,速度比较快
对于超大数据量的话,hiveOnSpark可能会有内存溢出情况
28.hive的join底层mr是如何实现的?
Hive的join底层mapreduce是如何实现的?
29.sql问题,连续几天活跃的用户?
大厂高频面试题-连续登录问题
30.建好了外部表,用什么语句把数据文件加载到表里
-
从本地导入:load data local inpath /home/liuzc into table ods.test
-
从hdfs导入:load data inpath /user/hive/warehouse/a.txt into ods.test
31.Hive的执行流程?
-
用户提交查询等任务给Driver。
-
编译器获得该用户的任务Plan。
-
编译器Compiler根据用户任务去MetaStore中获取需要的Hive的元数据信息。
-
编译器Compiler得到元数据信息,对任务进行编译,先将HiveQL转换为抽象语法树,然后将抽象语法树转换成查询块,将查询块转化为逻辑的查询计划,重写逻辑查询计划,将逻辑计划转化为物理的计划(MapReduce), 最后选择最佳的策略。
-
将最终的计划提交给Driver。
-
Driver将计划Plan转交给ExecutionEngine去执行,获取元数据信息,提交给JobTracker或者SourceManager执行该任务,任务会直接读取HDFS中文件进行相应的操作。
-
获取执行的结果。
-
取得并返回执行结果。
Hive的join底层mapreduce是如何实现的?
32.hive的元数据信息存储在哪?
-
内存数据库derby,安装小,但是数据存在内存,不稳定
-
mysql数据库,数据存储模式可以自己设置,持久化好,查看方便。
33.sql语句的执行顺序
from-where-group by-having -select-order by -limit
34.on和where的区别
left join(on&where)
35.hive和传统数据库之间的区别
1、写时模式和读时模式
传统数据库是写时模式,在load过程中,提升了査询性能,因为预先解析之后可以对列建立索引,并压缩,但这样也会花费更多的加载时间。
Hive是读时模式,1 oad data非常迅速,因为它不需要读取数据进行解析,仅仅进行文件的复制或者移动。
2、数据格式。Hive中没有定义专门的数据格式,由用户指定,需要指定三个属性:列分隔符,行分隔符,以及读取文件数据的方法。数据库中,存储引擎定义了自己的数据格式。所有数据都会按照一定的组织存储
3、数据更新。Hive的内容是读多写少的,因此,不支持对数据的改写和删除,数据都在加载的时候中确定好的。数据库中的数据通常是需要经常进行修改
4、执行延迟。Hive在查询数据的时候,需要扫描整个表(或分区),因此延迟较高,只有在处理大数据是才有优势。数据库在处理小数据是执行延迟较低。
5、索引。Hive比较弱,不适合实时查询。数据库有。
6、执行。Hive是 Mapreduce,数据库是 Executor
7、可扩展性。Hive高,数据库低
8、数据规模。Hive大,数据库小
36.hive中导入数据的4种方式
-
从本地导入:load data local inpath /home/liuzc into table ods.test
-
从hdfs导入:load data inpath /user/hive/warehouse/a.txt into ods.test
-
查询导入:create table tmp_test as select * from ods.test
-
查询结果导入:insert into table tmp.test select * from ods.test
37 下述sql在hive,sparksql两种执行引擎中,执行流程分别是什么,区别是什么?
select
t1.c,t2.b
from
t1 join t2
on t1.id = t2.id
38.hive的执行计划有看过吗,你一般会关注哪几个点
39.hive底层运行mr或者spark程序的时候语法树说一下
40.Hive优化说一下
Hive调优,数据工程师成神之路
41.你们数仓用的是hive还是spark,你平常怎么选择?
42.订单表,t_order, 字段,user_id,order_id,ctime(10位时间戳),city_id,sale_num,sku_id(商品)
问题:20201201至今每日订单量top10的城市及其订单量(订单量对order_id去重)(在线写)
43.hive开发过程中,你一般会怎么调优
Hive调优,数据工程师成神之路
44.hive的执行计划有看过吗,你一般会关注哪几个点
45.hive底层运行mr或者spark程序的时候语法树说一下
46.有没有用过udf函数,自定义函数分为几种?
HIVE之UDF函数开发
47.怎么从一个字符串中把数字拆出来?
48.给定一个表temp,字段是 user_id,clo1,col2....col12 12各字段代表12个月电费,求最终结果展现:user_id,month,money
49.hive做过哪些参数的优化?
Hive调优,数据工程师成神之路
50.mapjoin有什么缺点?
51.分桶表分区表区别?各自的优点?
52.大表join分桶的原因?
53.join的时候依照哪一个关键字?对字段有没有限制?
54.怎么把表分桶的?join的时候分桶的key不同怎么办?
55.数据倾斜怎么解决?distinct数据倾斜怎么办?
Hive调优,数据工程师成神之路
56.写hive sql题,以及进行hive sql优化的思路;
57.hive去重的几种方法?
58.hive这个组件产生的优点,与其他组件比较
59.hive调优说一下,你们平常怎么处理数据倾斜问题的
60.hive优化说一下
61.分区和分桶的区别
62.如何取样
63.row number, rank, dense rank区别
64.现场写一个sql
65.hivesql的复杂数据类型说一下
66.udf udaf udtf怎么实现
67.处理小文件的参数是什么
68.set hive.groupby.skewindata=true; 实现逻辑
当选项设定为 true,生成的查询计划会有两个MR Job。第一个MR Job中,Map的输出结果会随机分布到Reduce中,每个Reduce做部分聚合操作,并输出结果,这样处理的结果是相同的Group By Key有可能被分发到不同的Reduce中,从而达到负载均衡的目的;第二个MR Job再根据预处理的数据结果按照Group By Key分布到Reduce中(这个过程可以保证相同的Group By Key被分布到同一个Reduce中),最后完成最终的聚合操作。
69.大表join小表怎么优化
大表join小表,独钟爱mapjoin
70.mapjoin实现原理
大表join小表,独钟爱mapjoin
71.什么情况下,只会产生一个reduce任务,而没有maptask
72.空key你们是如何给随机值的
73.有多个热点值的数据group by,你们是怎么处理的,优化逻辑说一下
三、SPARK
1.rdd的属性

-
一组分片(Partition),即数据集的基本组成单位。对于RDD来说,每个分片都会被一个计算任务处理,并决定并行计算的粒度。用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值。默认值就是程序所分配到的CPU Core的数目。
-
一个计算每个分区的函数。Spark中RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。
-
RDD之间的依赖关系。RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。
-
一个Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
-
一个列表,存储存取每个Partition的优先位置(preferred location)。对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。按照“移动数据不如移动计算”的理念,Spark在进行任务调度的时候,会尽可能地将计算任务分配到其所要处理数据块的存储位置。
2.算子分为哪几类(RDD支持哪几种类型的操作)
转换(Transformation) 现有的RDD通过转换生成一个新的RDD。lazy模式,延迟执行。
转换函数包括:map,filter,flatMap,groupByKey,reduceByKey,aggregateByKey,union,join, coalesce 等等。
动作(Action) 在RDD上运行计算,并返回结果给驱动程序(Driver)或写入文件系统。
动作操作包括:reduce,collect,count,first,take,countByKey以及foreach等等。
collect 该方法把数据收集到driver端 Array数组类型
所有的transformation只有遇到action才能被执行。
当触发执行action之后,数据类型不再是rdd了,数据就会存储到指定文件系统中,或者直接打印结 果或者收集起来。
3.创建rdd的几种方式
1.集合并行化创建(有数据)
val arr = Array(1,2,3,4,5)
val rdd = sc.parallelize(arr)
val rdd =sc.makeRDD(arr)
2.读取外部文件系统,如hdfs,或者读取本地文件(最常用的方式)(没数据)
val rdd2 = sc.textFile("hdfs://hdp-01:9000/words.txt")
// 读取本地文件
val rdd2 = sc.textFile(“file:///root/words.txt”)
3.从父RDD转换成新的子RDD
调用Transformation类的方法,生成新的RDD
4.spark运行流程
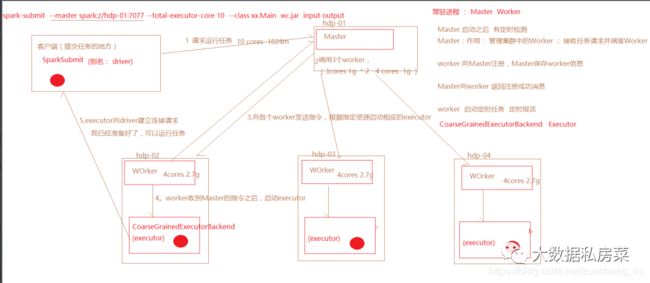
Worker的功能:定时和master通信;调度并管理自身的executor
executor:由Worker启动的,程序最终在executor中运行,(程序运行的一个容器)
spark-submit命令执行时,会根据master地址去向 Master发送请求,
Master接收到Dirver端的任务请求之后,根据任务的请求资源进行调度,(打散的策略),尽可能的 把任务资源平均分配,然后向WOrker发送指令
Worker收到Master的指令之后,就根据相应的资源,启动executor(cores,memory)
executor会向dirver端建立请求,通知driver,任务已经可以运行了
driver运行任务的时候,会把任务发送到executor中去运行。
5.Spark中coalesce与repartition的区别
1)关系:
两者都是用来改变 RDD 的 partition 数量的,repartition 底层调用的就是 coalesce 方法:coalesce(numPartitions, shuffle = true)
2)区别:
repartition 一定会发生 shuffle,coalesce 根据传入的参数来判断是否发生 shuffle
一般情况下增大 rdd 的 partition 数量使用 repartition,减少 partition 数量时使用coalesce
6.sortBy 和 sortByKey的区别
sortBy既可以作用于RDD[K] ,还可以作用于RDD[(k,v)]
sortByKey 只能作用于 RDD[K,V] 类型上。
7.map和mapPartitions的区别

8.数据存入Redis 优先使用map mapPartitions foreach foreachPartions哪个
使用 foreachPartition
* 1,map mapPartition 是转换类的算子, 有返回值
* 2, 写mysql,redis 的连接
foreach * 100万 100万次的连接
foreachPartions * 200 个分区 200次连接 一个分区中的数据,共用一个连接
foreachParititon 每次迭代一个分区,foreach每次迭代一个元素。
该方法没有返回值,或者Unit
主要作用于,没有返回值类型的操作(打印结果,写入到mysql数据库中)
在写入到redis,mysql的时候,优先使用foreachPartititon
9.reduceByKey和groupBykey的区别
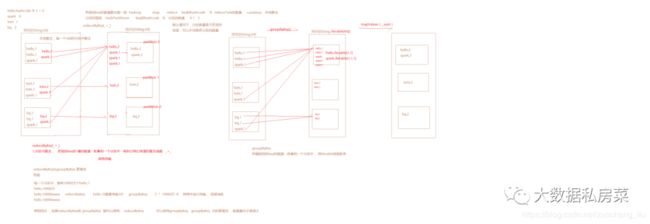
reduceByKey会传一个聚合函数, 相当于 groupByKey + mapValues
reduceByKey 会有一个分区内聚合,而groupByKey没有 最核心的区别
结论:reduceByKey有分区内聚合,更高效,优先选择使用reduceByKey。
10.cache和checkPoint的比较
都是做 RDD 持久化的
1.缓存,是在触发action之后,把数据写入到内存或者磁盘中。不会截断血缘关系
(设置缓存级别为memory_only:内存不足,只会部分缓存或者没有缓存,缓存会丢失,memory_and_disk :内存不足,会使用磁盘)
2.checkpoint 也是在触发action之后,执行任务。单独再启动一个job,负责写入数据到hdfs中。(把rdd中的数据,以二进制文本的方式写入到hdfs中,有几个分区,就有几个二进制文件)
3.某一个RDD被checkpoint之后,他的父依赖关系会被删除,血缘关系被截断,该RDD转换成了CheckPointRDD,以后再对该rdd的所有操作,都是从hdfs中的checkpoint的具体目录来读取数据。缓存之后,rdd的依赖关系还是存在的。
11.spark streaming流式统计单词数量代码
object WordCountAll {// newValues当前批次的出现的单词次数, runningCount表示之前运行的单词出现的结果/* def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {val newCount = newValues.sum + runningCount.getOrElse(0)// 将历史前几个批次的值和当前批次的值进行累加返回当前批次最终的结果Some(newCount)}*//*** String : 单词 hello* Seq[Int] :单词在当前批次出现的次数* Option[Int] :历史结果*/val updateFunc = (iter: Iterator[(String, Seq[Int], Option[Int])]) => {//iter.flatMap(it=>Some(it._2.sum + it._3.getOrElse(0)).map(x=>(it._1,x)))iter.flatMap{case(x,y,z)=>Some(y.sum + z.getOrElse(0)).map(m=>(x, m))}}// 屏蔽日志Logger.getLogger("org.apache").setLevel(Level.ERROR)def main(args: Array[String]) {// 必须要开启2个以上的线程,一个线程用来接收数据,另外一个线程用来计算val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")// 设置sparkjob计算时所采用的序列化方式.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer").set("spark.rdd.compress", "true") // 节约大量的内存内容// 如果你的程序出现垃圾回收时间过程,可以设置一下java的垃圾回收参数// 同时也会创建sparkContext对象// 批次时间 >= 批次处理的总时间 (批次数据量,集群的计算节点数量和配置)val ssc = new StreamingContext(conf, Seconds(5))//做checkpoint 写入共享存储中ssc.checkpoint("c://aaa")// 创建一个将要连接到 hostname:port 的 DStream,如 localhost:9999val lines: ReceiverInputDStream[String] = ssc.socketTextStream("192.168.175.101", 44444)//updateStateByKey结果可以累加但是需要传入一个自定义的累加函数:updateFuncval results = lines.flatMap(_.split(" ")).map((_,1)).updateStateByKey(updateFunc, new HashPartitioner(ssc.sparkContext.defaultParallelism), true)//打印结果到控制台results.print()//开始计算ssc.start()//等待停止ssc.awaitTermination()}}
12.简述map和flatMap的区别和应用场景
map是对每一个元素进行操作,flatmap是对每一个元素操作后并压平
13.计算曝光数和点击数

14.分别列出几个常用的transformation和action算子
转换算子:map,map,filter,reduceByKey,groupByKey,groupBy
行动算子:foreach,foreachpartition,collect,collectAsMap,take,top,first,count,countByKey
15.按照需求使用spark编写以下程序,要求使用scala语言
当前文件a.txt的格式,请统计每个单词出现的次数
A,b,c
B,b,f,e
object WordCount {def main(args: Array[String]): Unit = {val conf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[*]")val sc = new SparkContext(conf)var sData: RDD[String] = sc.textFile("a.txt")val sortData: RDD[(String, Int)] = sData.flatMap(_.split(",")).map((_,1)).reduceByKey(_+_)sortData.foreach(print)}}
16.spark应用程序的执行命令是什么?
/usr/local/spark-current2.3/bin/spark-submit \
--class com.wedoctor.Application \
--master yarn \
--deploy-mode client \
--driver-memory 1g \
--executor-memory 2g \
--queue root.wedw \
--num-executors 200 \
--jars /home/pgxl/liuzc/config-1.3.0.jar,/home/pgxl/liuzc/hadoop-lzo-0.4.20.jar,/home/pgxl/liuzc/elasticsearch-hadoop-hive-2.3.4.jar \
/home/pgxl/liuzc/sen.jar
17.Spark应用执行有哪些模式,其中哪几种是集群模式
-
本地local模式
-
standalone模式
-
spark on yarn模式
-
spark on mesos模式
其中,standalone模式,spark on yarn模式,spark on mesos模式是集群模式
18.请说明spark中广播变量的用途
使用广播变量,每个 Executor 的内存中,只驻留一份变量副本,而不是对 每个 task 都传输一次大变量,省了很多的网络传输, 对性能提升具有很大帮助, 而且会通过高效的广播算法来减少传输代价。
19.以下代码会报错吗?如果会怎么解决 val arr = new ArrayList[String]; arr.foreach(println)
val arr = new ArrayList[String]; 这里会报错,需要改成 val arr: Array[String] = new Array[String](10)
arr.foreach(println)打印不会报空指针
20.写出你用过的spark中的算子,其中哪些会产生shuffle过程
reduceBykey:
groupByKey:
…ByKey:
21.Spark中rdd与partition的区别
22.请写出创建Dateset的几种方式
23.描述一下RDD,DataFrame,DataSet的区别?
1)RDD
优点:
编译时类型安全
编译时就能检查出类型错误
面向对象的编程风格
直接通过类名点的方式来操作数据
缺点:
序列化和反序列化的性能开销
无论是集群间的通信, 还是 IO 操作都需要对对象的结构和数据进行序列化和反序列化。
GC 的性能开销,频繁的创建和销毁对象, 势必会增加 GC
2)DataFrame
DataFrame 引入了 schema 和 off-heap
schema : RDD 每一行的数据, 结构都是一样的,这个结构就存储在 schema 中。Spark 通过 schema 就能够读懂数据, 因此在通信和 IO 时就只需要序列化和反序列化数据, 而结构的部分就可以省略了。
3)DataSet
DataSet 结合了 RDD 和 DataFrame 的优点,并带来的一个新的概念 Encoder。
当序列化数据时,Encoder 产生字节码与 off-heap 进行交互,能够达到按需访问数据的效果,而不用反序列化整个对象。Spark 还没有提供自定义 Encoder 的 API,但是未来会加入。
三者之间的转换:

24.描述一下Spark中stage是如何划分的?描述一下shuffle的概念
25.Spark 在yarn上运行需要做哪些关键的配置工作?如何kill -个Spark在yarn运行中Application
26.通常来说,Spark与MapReduce相比,Spark运行效率更高。请说明效率更高来源于Spark内置的哪些机制?并请列举常见spark的运行模式?
27.RDD中的数据在哪?
RDD中的数据在数据源,RDD只是一个抽象的数据集,我们通过对RDD的操作就相当于对数据进行操作。
28.如果对RDD进行cache操作后,数据在哪里?
数据在第一执行cache算子时会被加载到各个Executor进程的内存中,第二次就会直接从内存中读取而不会区磁盘。
29.Spark中Partition的数量由什么决定
和Mr一样,但是Spark默认最少有两个分区。
30.Scala里面的函数和方法有什么区别
31.SparkStreaming怎么进行监控?
32.Spark判断Shuffle的依据?
父RDD的一个分区中的数据有可能被分配到子RDD的多个分区中
33.Scala有没有多继承?可以实现多继承么?
34.Sparkstreaming和flink做实时处理的区别
35.Sparkcontext的作用
36.Sparkstreaming读取kafka数据为什么选择直连方式
37.离线分析什么时候用sparkcore和sparksq
38.Sparkstreaming实时的数据不丢失的问题
39.简述宽依赖和窄依赖概念,groupByKey,reduceByKey,map,filter,union五种操作哪些会导致宽依赖,哪些会导致窄依赖
40.数据倾斜可能会导致哪些问题,如何监控和排查,在设计之初,要考虑哪些来避免
41.有一千万条短信,有重复,以文本文件的形式保存,一行一条数据,请用五分钟时间,找出重复出现最多的前10条
42.现有一文件,格式如下,请用spark统计每个单词出现的次数
18619304961,18619304064,186193008,186193009
18619304962,18619304065,186193007,186193008
18619304963,18619304066,186193006,186193010
43.共享变量和累加器
累加器(accumulator)是 Spark 中提供的一种分布式的变量机制,其原理类似于mapreduce,即分布式的改变,然后聚合这些改变。累加器的一个常见用途是在调试时对作业执行过程中的事件进行计数。而广播变量用来高效分发较大的对象。
共享变量出现的原因:
通常在向 Spark 传递函数时,比如使用 map() 函数或者用 filter() 传条件时,可以使用驱动器程序中定义的变量,但是集群中运行的每个任务都会得到这些变量的一份新的副本,更新这些副本的值也不会影响驱动器中的对应变量。
Spark 的两个共享变量,累加器与广播变量,分别为结果聚合与广播这两种常见的通信模式突破了这一限制。
44.当 Spark 涉及到数据库的操作时,如何减少 Spark 运行中的数据库连接数?
使用 foreachPartition 代替 foreach,在 foreachPartition 内获取数据库的连接。
45.特别大的数据,怎么发送到excutor中?
46.spark调优都做过哪些方面?
47.spark任务为什么会被yarn kill掉?
48.Spark on Yarn作业执行流程?yarn-client和yarn-cluster有什么区别?
你们公司还在用SparkOnYan吗?
49.Flatmap底层编码实现?
Spark flatMap 源码:
/*** Return a new RDD by first applying a function to all elements of this* RDD, and then flattening the results.*/def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U] = withScope {val cleanF = sc.clean(f)new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.flatMap(cleanF))}
Scala flatMap 源码:
/** Creates a new iterator by applying a function to all values produced by this iterator* and concatenating the results.** @param f the function to apply on each element.* @return the iterator resulting from applying the given iterator-valued function* `f` to each value produced by this iterator and concatenating the results.* @note Reuse: $consumesAndProducesIterator*/def flatMap[B](f: A => GenTraversableOnce[B]): Iterator[B] = new AbstractIterator[B] {private var cur: Iterator[B] = emptyprivate def nextCur() { cur = f(self.next()).toIterator }def hasNext: Boolean = {// Equivalent to cur.hasNext || self.hasNext && { nextCur(); hasNext }// but slightly shorter bytecode (better JVM inlining!)while (!cur.hasNext) {if (!self.hasNext) return falsenextCur()}true}def next(): B = (if (hasNext) cur else empty).next()}
flatMap其实就是将RDD里的每一个元素执行自定义函数f,这时这个元素的结果转换成iterator,最后将这些再拼接成一个
新的RDD,也可以理解成原本的每个元素由横向执行函数f后再变为纵向。画红部分一直在回调,当RDD内没有元素为止。
50.spark_1.X与spark_2.X区别
51.说说spark与flink
52.spark streaming如何保证7*24小时运行机制?
53.spark streaming是Exactly-Once吗?
54.spark的原理和优化
55.spark和mr的区别
56.rdd、ck、cache
57.topn的具体步骤
58.怎么可以实现在一小时topn的固定窗口情况下,0-10、0-20也会有结果的显示
59.stage的划分依据?
60.shuffle什么原因引起的?
61.哪一些算子会引起shuffle?
62.什么RDD可以用repartition?
63.coaldesce shuffle为true
64.sparkstreaming的ck有什么好处?
65.ck、persist、cache分别有什么区别?
66.怎么定义算子是转换算子还是行动算子?(怎么知道这个算子是行动算子?)
67.有状态缓存的算子?
68.怎么实时查看用户访问数?这种实时变动的需求怎么实现?
69.对spark/spark streaming的原理了解,以及优化的思路;
70.spark的数据倾斜
71.小文件优化的原理
72.Spark的源码,例如:框架层面、算子具体实现
73.Spark什么时候用到内存,什么用到磁盘
74.算子collect分为
75.Spark堆内内存和堆外内存的区别,什么时候用到堆内,什么时候用到堆外
76.scala的尾递归知道吗?(一脸懵逼)
四、KAFKA
1.Kafka名词解释和工作方式
-
Producer :消息生产者,就是向kafka broker发消息的客户端。
-
Consumer :消息消费者,向kafka broker取消息的客户端
-
Topic :咋们可以理解为一个队列。
-
Consumer Group (CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个partion只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic。
-
Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
-
Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
-
Offset:kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka
2.Consumer与topic关系
本质上kafka只支持Topic;
每个group中可以有多个consumer,每个consumer属于一个consumer group;
通常情况下,一个group中会包含多个consumer,这样不仅可以提高topic中消息的并发消费能力,而且还能提高"故障容错"性,如果group中的某个consumer失效那么其消费的partitions将会有其他consumer自动接管。
对于Topic中的一条特定的消息,只会被订阅此Topic的每个group中的其中一个consumer消费,此消息不会发送给一个group的多个consumer;
那么一个group中所有的consumer将会交错的消费整个Topic,每个group中consumer消息消费互相独立,我们可以认为一个group是一个"订阅"者。
在kafka中,一个partition中的消息只会被group中的一个consumer消费(同一时刻);
一个Topic中的每个partions,只会被一个"订阅者"中的一个consumer消费,不过一个consumer可以同时消费多个partitions中的消息。
kafka的设计原理决定,对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则将意味着某些consumer将无法得到消息。
kafka只能保证一个partition中的消息被某个consumer消费时是顺序的;事实上,从Topic角度来说,当有多个partitions时,消息仍不是全局有序的。
3.kafka中生产数据的时候,如何保证写入的容错性?
设置发送数据是否需要服务端的反馈,有三个值0,1,-1
0: producer不会等待broker发送ack
1: 当leader接收到消息之后发送ack
-1: 当所有的follower都同步消息成功后发送ack
request.required.acks=0
4.如何保证kafka消费者消费数据是全局有序的
伪命题
每个分区内,每条消息都有一个offset,故只能保证分区内有序。
如果要全局有序的,必须保证生产有序,存储有序,消费有序。
由于生产可以做集群,存储可以分片,消费可以设置为一个consumerGroup,要保证全局有序,就需要保证每个环节都有序。
只有一个可能,就是一个生产者,一个partition,一个消费者。这种场景和大数据应用场景相悖。
5.有两个数据源,一个记录的是广告投放给用户的日志,一个记录用户访问日志,另外还有一个固定的用户基础表记录用户基本信息(比如学历,年龄等等)。现在要分析广告投放对与哪类用户更有效,请采用熟悉的技术描述解决思路。另外如果两个数据源都是实时数据源(比如来自kafka),他们数据在时间上相差5分钟,需要哪些调整来解决实时分析问题?
6.Kafka和SparkStreaing如何集成?
7.列举Kafka的优点,简述Kafka为什么可以做到每秒数十万甚至上百万消息的高效分发?
8.为什么离线分析要用kafka?
Kafka的作用是解耦,如果直接从日志服务器上采集的话,实时离线都要采集,等于要采集两份数据,而使用了kafka的话,只需要从日志服务器上采集一份数据,然后在kafka中使用不同的两个组读取就行了
9.Kafka怎么进行监控?
Kafka Manager
10.Kafka与传统的消息队列服务有很么不同
11.Kafka api low-level与high-level有什么区别,使用low-level需要处理哪些细节
12.Kafka的ISR副本同步队列
ISR(In-Sync Replicas),副本同步队列。ISR中包括Leader和Follower。如果Leader进程挂掉,会在ISR队列中选择一个服务作为新的Leader。有replica.lag.max.messages(延迟条数)和replica.lag.time.max.ms(延迟时间)两个参数决定一台服务是否可以加入ISR副本队列,在0.10版本移除了replica.lag.max.messages参数,防止服务频繁的进去队列。
任意一个维度超过阈值都会把Follower剔除出ISR,存入OSR(Outof-Sync Replicas)列表,新加入的Follower也会先存放在OSR中。
13.Kafka消息数据积压,Kafka消费能力不足怎么处理?
1)如果是Kafka消费能力不足,则可以考虑增加Topic的分区数,并且同时提升消费组的消费者数量,消费者数=分区数。(两者缺一不可)
2)如果是下游的数据处理不及时:提高每批次拉取的数量。批次拉取数据过少(拉取数据/处理时间<生产速度),使处理的数据小于生产的数据,也会造成数据积压。
14.Kafka中的ISR、AR又代表什么?
ISR:in-sync replicas set (ISR),与leader保持同步的follower集合
AR:分区的所有副本
15.Kafka中的HW、LEO等分别代表什么?
LEO:每个副本的最后条消息的offset
HW:一个分区中所有副本最小的offset
16.哪些情景会造成消息漏消费?
先提交offset,后消费,有可能造成数据的重复
17.当你使用kafka-topics.sh创建了一个topic之后,Kafka背后会执行什么逻辑?
1)会在zookeeper中的/brokers/topics节点下创建一个新的topic节点,如:/brokers/topics/first
2)触发Controller的监听程序
3)kafka Controller 负责topic的创建工作,并更新metadata cache
18.topic的分区数可不可以增加?如果可以怎么增加?如果不可以,那又是为什么?
可以增加
bin/kafka-topics.sh --zookeeper localhost:2181/kafka --alter --topic topic-config --partitions 3
19.topic的分区数可不可以减少?如果可以怎么减少?如果不可以,那又是为什么?
不可以减少,被删除的分区数据难以处理。
20.Kafka有内部的topic吗?如果有是什么?有什么所用?
__consumer_offsets,保存消费者offset
21.聊一聊Kafka Controller的作用?
负责管理集群broker的上下线,所有topic的分区副本分配和leader选举等工作。
22.失效副本是指什么?有那些应对措施?
不能及时与leader同步,暂时踢出ISR,等其追上leader之后再重新加入
23.Kafka 都有哪些特点?
-
高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作。
-
可扩展性:kafka集群支持热扩展
-
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
-
容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
-
高并发:支持数千个客户端同时读写
24.请简述下你在哪些场景下会选择 Kafka?
-
日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、HBase、Solr等。
-
消息系统:解耦和生产者和消费者、缓存消息等。
-
用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
-
运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
-
流式处理:比如spark streaming和 Flink
25.Kafka 的设计架构你知道吗?
简单架构如下
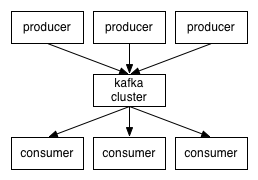
详细如下
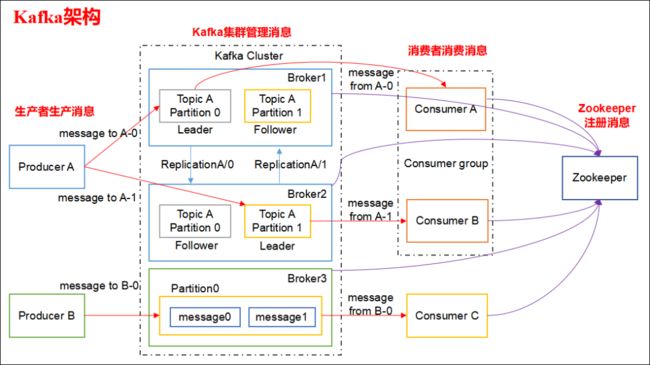
Kafka 架构分为以下几个部分
-
Producer :消息生产者,就是向 kafka broker 发消息的客户端。
-
Consumer :消息消费者,向 kafka broker 取消息的客户端。
-
Topic :可以理解为一个队列,一个 Topic 又分为一个或多个分区。
-
Consumer Group:这是 kafka 用来实现一个 topic 消息的广播(发给所有的 consumer)和单播(发给任意一个 consumer)的手段。一个 topic 可以有多个 Consumer Group。
-
Broker :一台 kafka 服务器就是一个 broker。一个集群由多个 broker 组成。一个 broker 可以容纳多个 topic。
-
Partition:为了实现扩展性,一个非常大的 topic 可以分布到多个 broker上,每个 partition 是一个有序的队列。partition 中的每条消息都会被分配一个有序的id(offset)。将消息发给 consumer,kafka 只保证按一个 partition 中的消息的顺序,不保证一个 topic 的整体(多个 partition 间)的顺序。
-
Offset:kafka 的存储文件都是按照 offset.kafka 来命名,用 offset 做名字的好处是方便查找。例如你想找位于 2049 的位置,只要找到 2048.kafka 的文件即可。当然 the first offset 就是 00000000000.kafka。
26.Kafka 分区的目的?
分区对于 Kafka 集群的好处是:实现负载均衡。分区对于消费者来说,可以提高并发度,提高效率。
27.你知道 Kafka 是如何做到消息的有序性?
kafka 中的每个 partition 中的消息在写入时都是有序的,而且消息带有offset偏移量,消费者按偏移量的顺序从前往后消费,从而保证了消息的顺序性。但是分区之间的消息是不保证有序的。
28.ISR、OSR、AR 是什么?
ISR:In-Sync Replicas 副本同步队列
OSR:Out-of-Sync Replicas
AR:Assigned Replicas 所有副本
ISR是由leader维护,follower从leader同步数据有一些延迟(具体可以参见 图文了解 Kafka 的副本复制机制),超过相应的阈值会把 follower 剔除出 ISR, 存入OSR(Out-of-Sync Replicas )列表,新加入的follower也会先存放在OSR中。AR=ISR+OSR。
29.LEO、HW、LSO、LW等分别代表什么
-
LEO:是 LogEndOffset 的简称,代表当前日志文件中下一条
-
HW:水位或水印(watermark)一词,也可称为高水位(high watermark),通常被用在流式处理领域(比如Apache Flink、Apache Spark等),以表征元素或事件在基于时间层面上的进度。在Kafka中,水位的概念反而与时间无关,而是与位置信息相关。严格来说,它表示的就是位置信息,即位移(offset)。取 partition 对应的 ISR中 最小的 LEO 作为 HW,consumer 最多只能消费到 HW 所在的位置上一条信息。
-
LSO:是 LastStableOffset 的简称,对未完成的事务而言,LSO 的值等于事务中第一条消息的位置(firstUnstableOffset),对已完成的事务而言,它的值同 HW 相同
-
LW:Low Watermark 低水位, 代表 AR 集合中最小的 logStartOffset 值。
30.Kafka 在什么情况下会出现消息丢失?
参考数据可靠性和数据一致性
31.Kafka 的每个分区只能被一个消费者线程,如何做到多个线程同时消费一个分区?
32.数据传输的事务有几种?
数据传输的事务定义通常有以下三种级别:
-
最多一次: 消息不会被重复发送,最多被传输一次,但也有可能一次不传输
-
最少一次: 消息不会被漏发送,最少被传输一次,但也有可能被重复传输.
-
精确的一次(Exactly once): 不会漏传输也不会重复传输,每个消息都传输被
33.Kafka 消费者是否可以消费指定分区消息?
Kafa consumer消费消息时,向broker发出fetch请求去消费特定分区的消息,consumer指定消息在日志中的偏移量(offset),就可以消费从这个位置开始的消息,customer拥有了offset的控制权,可以向后回滚去重新消费之前的消息,这是很有意义的
34.Kafka消息是采用Pull模式,还是Push模式?
Kafka最初考虑的问题是,customer应该从brokes拉取消息还是brokers将消息推送到consumer,也就是pull还push。在这方面,Kafka遵循了一种大部分消息系统共同的传统的设计:producer将消息推送到broker,consumer从broker拉取消息。
一些消息系统比如Scribe和Apache Flume采用了push模式,将消息推送到下游的consumer。这样做有好处也有坏处:由broker决定消息推送的速率,对于不同消费速率的consumer就不太好处理了。消息系统都致力于让consumer以最大的速率最快速的消费消息,但不幸的是,push模式下,当broker推送的速率远大于consumer消费的速率时,consumer恐怕就要崩溃了。最终Kafka还是选取了传统的pull模式。Pull模式的另外一个好处是consumer可以自主决定是否批量的从broker拉取数据。Push模式必须在不知道下游consumer消费能力和消费策略的情况下决定是立即推送每条消息还是缓存之后批量推送。如果为了避免consumer崩溃而采用较低的推送速率,将可能导致一次只推送较少的消息而造成浪费。Pull模式下,consumer就可以根据自己的消费能力去决定这些策略。Pull有个缺点是,如果broker没有可供消费的消息,将导致consumer不断在循环中轮询,直到新消息到t达。为了避免这点,Kafka有个参数可以让consumer阻塞知道新消息到达(当然也可以阻塞知道消息的数量达到某个特定的量这样就可以批量发
35.Kafka 高效文件存储设计特点
-
Kafka把topic中一个parition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。
-
通过索引信息可以快速定位message和确定response的最大大小。
-
通过index元数据全部映射到memory,可以避免segment file的IO磁盘操作。
-
通过索引文件稀疏存储,可以大幅降低index文件元数据占用空间大小
36.Kafka创建Topic时如何将分区放置到不同的Broker中
-
副本因子不能大于 Broker 的个数;
-
第一个分区(编号为0)的第一个副本放置位置是随机从 brokerList 选择的;
-
其他分区的第一个副本放置位置相对于第0个分区依次往后移。也就是如果我们有5个 Broker,5个分区,假设第一个分区放在第四个 Broker 上,那么第二个分区将会放在第五个 Broker 上;第三个分区将会放在第一个 Broker 上;第四个分区将会放在第二个 Broker 上,依次类推;
-
剩余的副本相对于第一个副本放置位置其实是由 nextReplicaShift 决定的,而这个数也是随机产生的;
具体可以参见Kafka创建Topic时如何将分区放置到不同的Broker中。
37.Kafka新建的分区会在哪个目录下创建
我们知道,在启动 Kafka 集群之前,我们需要配置好 log.dirs 参数,其值是 Kafka 数据的存放目录,这个参数可以配置多个目录,目录之间使用逗号分隔,通常这些目录是分布在不同的磁盘上用于提高读写性能。当然我们也可以配置 log.dir 参数,含义一样。只需要设置其中一个即可。
如果 log.dirs 参数只配置了一个目录,那么分配到各个 Broker 上的分区肯定只能在这个目录下创建文件夹用于存放数据。
但是如果 log.dirs 参数配置了多个目录,那么 Kafka 会在哪个文件夹中创建分区目录呢?答案是:Kafka 会在含有分区目录最少的文件夹中创建新的分区目录,分区目录名为 Topic名+分区ID。注意,是分区文件夹总数最少的目录,而不是磁盘使用量最少的目录!也就是说,如果你给 log.dirs 参数新增了一个新的磁盘,新的分区目录肯定是先在这个新的磁盘上创建直到这个新的磁盘目录拥有的分区目录不是最少为止。
38.谈一谈 Kafka 的再均衡
在Kafka中,当有新消费者加入或者订阅的topic数发生变化时,会触发Rebalance(再均衡:在同一个消费者组当中,分区的所有权从一个消费者转移到另外一个消费者)机制,Rebalance顾名思义就是重新均衡消费者消费。Rebalance的过程如下:
第一步:所有成员都向coordinator发送请求,请求入组。一旦所有成员都发送了请求,coordinator会从中选择一个consumer担任leader的角色,并把组成员信息以及订阅信息发给leader。第二步:leader开始分配消费方案,指明具体哪个consumer负责消费哪些topic的哪些partition。一旦完成分配,leader会将这个方案发给coordinator。coordinator接收到分配方案之后会把方案发给各个consumer,这样组内的所有成员就都知道自己应该消费哪些分区了。所以对于Rebalance来说,Coordinator起着至关重要的作用
39.Kafka Producer 是如何动态感知主题分区数变化的?
40.Kafka 是如何实现高吞吐率的?
Kafka是分布式消息系统,需要处理海量的消息,Kafka的设计是把所有的消息都写入速度低容量大的硬盘,以此来换取更强的存储能力,但实际上,使用硬盘并没有带来过多的性能损失。kafka主要使用了以下几个方式实现了超高的吞吐率:
-
顺序读写;
-
零拷贝
-
文件分段
-
批量发送
-
数据压缩。
41.Kafka 监控都有哪些?
比较流行的监控工具有:
KafkaOffsetMonitor
KafkaManager
Kafka Web Console
Kafka Eagle
JMX协议(可以用诸如jdk自带的jconsole来进行连接获取状态信息)
42.如何为Kafka集群选择合适的Topics/Partitions数量
参见《如何为Kafka集群选择合适的Topics/Partitions数量》
43.Kafka 缺点?
-
由于是批量发送,数据并非真正的实时;
-
对于mqtt协议不支持;
-
不支持物联网传感数据直接接入;
-
仅支持统一分区内消息有序,无法实现全局消息有序;
-
监控不完善,需要安装插件;
-
依赖zookeeper进行元数据管理;
44.Kafka 新旧消费者的区别
旧的 Kafka 消费者 API 主要包括:SimpleConsumer(简单消费者) 和 ZookeeperConsumerConnectir(高级消费者)。SimpleConsumer 名字看起来是简单消费者,但是其实用起来很不简单,可以使用它从特定的分区和偏移量开始读取消息。高级消费者和现在新的消费者有点像,有消费者群组,有分区再均衡,不过它使用 ZK 来管理消费者群组,并不具备偏移量和再均衡的可操控性。
现在的消费者同时支持以上两种行为,所以为啥还用旧消费者 API 呢?
45.Kafka 分区数可以增加或减少吗?为什么?
我们可以使用 bin/kafka-topics.sh 命令对 Kafka 增加 Kafka 的分区数据,但是 Kafka 不支持减少分区数。Kafka 分区数据不支持减少是由很多原因的,比如减少的分区其数据放到哪里去?是删除,还是保留?删除的话,那么这些没消费的消息不就丢了。如果保留这些消息如何放到其他分区里面?追加到其他分区后面的话那么就破坏了 Kafka 单个分区的有序性。如果要保证删除分区数据插入到其他分区保证有序性,那么实现起来逻辑就会非常复杂。
46.kafka消息的存储机制
kafka通过 topic来分主题存放数据,主题内有分区,分区可以有多个副本,分区的内部还细分为若干个 segment。都是持久化到磁盘,采用零拷贝技术。
1、高效检索
分区下面,会进行分段操作,每个分段都会有对应的素引,这样就可以根据 offset二分查找定位到消息在哪一段,根据段的索引文件,定位具体的 mle ssage
2、分区副本可用性(1 eader选举,zk来协调
如果1eader宕机,选出了新的1eader,而新的 leader并不能保证已经完全同步了之前1eader的所有数据,只能保证HW(高水位设置)之前的数据是同步过的,此时所有的 follower都要将数据截断到W的位置,再和新的 leader同步数据,来保证数据一致。
当宕机的 leader恢复,发现新的1eader中的数据和自己持有的数据不一致,此时宕机的1 eader会将自己的数据截断到宕机之前的hw位置,然后同步新1 eader的数据。宕机的1eader活过来也像 follower一样同步数据,来保证数据的一致性。
47.相比较于传统消息队列,kafka的区别
1、分区性:存储不会受单一服务器存储空间的限制
2、高可用性:副本1 eader选举
3、消息有序性:一个分区内是有序的。
4、负载均衡性:分区内的一条消息,只会被消费组中的一个消费者消费,主题中的消息,会均衡的发送给消费者组中的所有消费者进行消费。
48.消息丢失和消息重复
同步:这个生产者写一条消息的时候,它就立马发送到某个分区去。
异步:这个生产者写一条消息的时候,先是写到某个缓冲区,这个缓冲区里的数据还没写到 broker集群里的某个分区的时候,它就返回到 client去了
针对消息丢失:同步模式下,确认机制设置为-1,即让消息写入 Leader和 Fol lower之后再确认消息发送成功:
异步模式下,为防止缓冲区满,可以在配置文件设置不限制阻塞超时时间,当缓冲区满时让生产者一直处于阻塞状态
针对消息重复,将消息的唯一标识保存到外部介质中,每次消费时判断是否处理过即可
49.对kafka有一定了解吗?
50.能大致说一下kafka的写流程吗?
51.ack的情况
52.kafka的最终文件夹存储方式是什么样子的?
53.kafka为什么可以快速根据分区和offset找到我们的数据记录?
54.索引文件中是怎么记录这些消息的?
55.消费者组的概念怎么理解?
56.kafka的选举机制?
57.Kafka读数据的原理(二分法的那个
58.kafka分区数和Flink的并行度关系,这方面的源码你看过吗?
五、HBASE
1.Hbase调优
HBase应该如何优化?
2.hbase的rowkey怎么创建好?列族怎么创建比较好?
HBase-Rowkey设计
一个列族在数据底层是一个文件,所以将经常一起查询的列放到一个列族中,列族尽量少,减少文件的寻址时间。
3.hbase过滤器实现用途
简单讲讲布隆过滤器及其在HBase中的应用
4.HBase宕机如何处理
答:宕机分为HMaster宕机和HRegisoner宕机,如果是HRegisoner宕机,HMaster会将其所管理的region重新分布到其他活动的RegionServer上,由于数据和日志都持久在HDFS中,该操作不会导致数据丢失。所以数据的一致性和安全性是有保障的。
如果是HMaster宕机,HMaster没有单点问题,HBase中可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master运行。即ZooKeeper会保证总会有一个HMaster在对外提供服务。
5.hive跟hbase的区别是?
Hive与HBase的区别及应用场景
6.hbase写流程

1/ 客户端要连接zookeeper, 从zk的/hbase节点找到hbase:meta表所在的regionserver(host:port);
2/ regionserver扫描hbase:meta中的每个region的起始行健,对比r000001这条数据在那个region的范围内;
3/ 从对应的 info:server key中存储了region是有哪个regionserver(host:port)在负责的;
4/ 客户端直接请求对应的regionserver;
5/ regionserver接收到客户端发来的请求之后,就会将数据写入到region中
7.hbase读流程
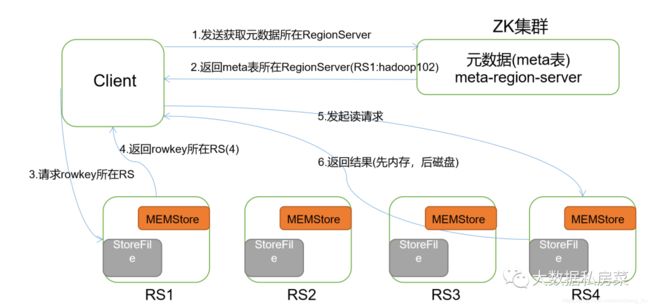
1/ 首先Client连接zookeeper, 找到hbase:meta表所在的regionserver;
2/ 请求对应的regionserver,扫描hbase:meta表,根据namespace、表名和rowkey在meta表中找到r00001所在的region是由那个regionserver负责的;
3/找到这个region对应的regionserver
4/ regionserver收到了请求之后,扫描对应的region返回数据到Client
(先从MemStore找数据,如果没有,再到BlockCache里面读;BlockCache还没有,再到StoreFile上读(为了读取的效率);
如果是从StoreFile里面读取的数据,不是直接返回给客户端,而是先写入BlockCache,再返回给客户端。)
8.hbase数据flush过程
1)当MemStore数据达到阈值(默认是128M,老版本是64M),将数据刷到硬盘,将内存中的数据删除,同时删除HLog中的历史数据;
2)并将数据存储到HDFS中;
3)在HLog中做标记点。
9.数据合并过程
-
当数据块达到4块,hmaster将数据块加载到本地,进行合并
-
当合并的数据超过256M,进行拆分,将拆分后的region分配给不同的hregionserver管理
-
当hregionser宕机后,将hregionserver上的hlog拆分,然后分配给不同的hregionserver加载,修改.META.
-
注意:hlog会同步到hdfs
10.Hmaster和Hgionserver职责
Hmaster
1、管理用户对Table的增、删、改、查操作;
2、记录region在哪台Hregion server上
3、在Region Split后,负责新Region的分配;
4、新机器加入时,管理HRegion Server的负载均衡,调整Region分布
5、在HRegion Server宕机后,负责失效HRegion Server 上的Regions迁移。
Hgionserver
HRegion Server主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBASE中最核心的模块。
HRegion Server管理了很多table的分区,也就是region。
11.HBase列族和region的关系?
HBase有多个RegionServer,每个RegionServer里有多个Region,一个Region中存放着若干行的行键以及所对应的数据,一个列族是一个文件夹,如果经常要搜索整个一条数据,列族越少越好,如果只有一部分的数据需要经常被搜索,那么将经常搜索的建立一个列族,其他不常搜索的建立列族检索较快。
12.请简述Hbase的物理模型是什么
13.请问如果使用Hbase做即席查询,如何设计二级索引
HBase二级索引设计思想
14.如何避免读、写HBaes时访问热点问题?
HBase-Rowkey设计
15.布隆过滤器在HBASE中的应用
简单讲讲布隆过滤器及其在HBase中的应用
16.Hbase是用来干嘛的?什么样的数据会放到hbase
Hive与HBase的区别及应用场景
17.Hbase在建表时的设计原则(注意事项)
HBase应该如何优化?
18.Hbase中的region server发生故障后的处理方法(zk-->WAL)
Hbase检测宕机是通过 Zookeeper实现的,正常情况下 Regionserver会周期性向 Zookeeper发送心跳,一旦发生宕机,心跳就会停止,超过一定时间( Sessi ontimeout) Zookeeper就会认为 Regionserver宕机离线,并将该消息通知给 Master0一台 Regionserver只有一个Hog文件,然后,将og按照
Region进行分组,切分到每个 regionserver中,因此在回放之前首先需要将og按照 Region进行分组,每个 Region的日志数据放在一起,方便后面按照 Region进行回放。这个分组的过程就称为HLog切分。然后再对 region重新分配,并对其中的Hog进行回放将数据写入 memstore刷写到磁盘,完成最终数据恢复。
19.用phenix和es作为hbase二级索引的区别,最新的hbase已经支持二级索引了,你清楚吗?
20.rowkey一般如何设计,你项目中是如何设计的
HBase-Rowkey设计
21.hbase有了解吗,原理是什么。hbase的优化怎么做
HBase应该如何优化?
22.HBase的Rowkey优化
HBase-Rowkey设计
六、HADOOP
1.hdfs写流程
HDFS读写流程
2.hdfs读流程
HDFS读写流程
3.hdfs的体系结构
hdfs有namenode、secondraynamenode、datanode组成。为n+1模式
-
NameNode负责管理和记录整个文件系统的元数据
-
DataNode 负责管理用户的文件数据块,文件会按照固定的大小(blocksize)切成若干块后分布式存储在若干台datanode上,每一个文件块可以有多个副本,并存放在不同的datanode上,Datanode会定期向Namenode汇报自身所保存的文件block信息,而namenode则会负责保持文件的副本数量
-
HDFS的内部工作机制对客户端保持透明,客户端请求访问HDFS都是通过向namenode申请来进行
-
secondraynamenode负责合并日志
4.一个datanode 宕机,怎么一个流程恢复
Datanode宕机了后,如果是短暂的宕机,可以实现写好脚本监控,将它启动起来。如果是长时间宕机了,那么datanode上的数据应该已经被备份到其他机器了,那这台datanode就是一台新的datanode了,删除他的所有数据文件和状态文件,重新启动。
5.hadoop 的 namenode 宕机,怎么解决
先分析宕机后的损失,宕机后直接导致client无法访问,内存中的元数据丢失,但是硬盘中的元数据应该还存在,如果只是节点挂了,重启即可,如果是机器挂了,重启机器后看节点是否能重启,不能重启就要找到原因修复了。但是最终的解决方案应该是在设计集群的初期就考虑到这个问题,做namenode的HA。
6.namenode对元数据的管理
namenode对数据的管理采用了三种存储形式:
-
内存元数据(NameSystem)
-
磁盘元数据镜像文件(fsimage镜像)
-
数据操作日志文件(可通过日志运算出元数据)(edit日志文件)
7.元数据的checkpoint
每隔一段时间,会由secondary namenode将namenode上积累的所有edits和一个最新的fsimage下载到本地,并加载到内存进行merge(这个过程称为checkpoint)
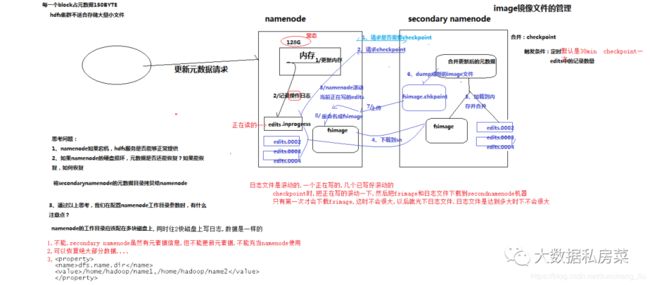
namenode和secondary namenode的工作目录存储结构完全相同,所以,当namenode故障退出需要重新恢复时,可以从secondary namenode的工作目录中将fsimage拷贝到namenode的工作目录,以恢复namenode的元数据
8.yarn资源调度流程
Yarn的资源调度流程
9.hadoop中combiner和partition的作用
-
combiner是发生在map的最后一个阶段,父类就是Reducer,意义就是对每一个maptask的输出进行局部汇总,以减小网络传输量,缓解网络传输瓶颈,提高reducer的执行效率。
-
partition的主要作用将map阶段产生的所有kv对分配给不同的reducer task处理,可以将reduce阶段的处理负载进行分摊
10.用mapreduce怎么处理数据倾斜问题?
数据倾斜:map /reduce程序执行时,reduce节点大部分执行完毕,但是有一个或者几个reduce节点运行很慢,导致整个程序的处理时间很长,这是因为某一个key的条数比其他key多很多(有时是百倍或者千倍之多),这条key所在的reduce节点所处理的数据量比其他节点就大很多,从而导致某几个节点迟迟运行不完,此称之为数据倾斜。
(1)局部聚合加全局聚合。
第一次在 map 阶段对那些导致了数据倾斜的 key 加上 1 到 n 的随机前缀,这样本来相
同的 key 也会被分到多个 Reducer 中进行局部聚合,数量就会大大降低。
第二次 mapreduce,去掉 key 的随机前缀,进行全局聚合。
思想:二次 mr,第一次将 key 随机散列到不同 reducer 进行处理达到负载均衡目的。第
二次再根据去掉 key 的随机前缀,按原 key 进行 reduce 处理。
这个方法进行两次 mapreduce,性能稍差。
(2)增加 Reducer,提升并行度
JobConf.setNumReduceTasks(int)
(3)实现自定义分区
根据数据分布情况,自定义散列函数,将 key 均匀分配到不同 Reducer
11.shuffle 阶段,你怎么理解的
详解MapReduce执行流程
12.Mapreduce 的 map 数量 和 reduce 数量是由什么决定的 ,怎么配置
map的数量由输入切片的数量决定,128M切分一个切片,只要是文件也分为一个切片,有多少个切片就有多少个map Task。
reduce数量自己配置。
13.MapReduce优化经验
-
设置合理的map和reduce的个数。合理设置blocksize
-
避免出现数据倾斜
-
combine函数
-
对数据进行压缩
-
小文件处理优化:事先合并成大文件,combineTextInputformat,在hdfs上用mapreduce将小文件合并成SequenceFile大文件(key:文件名,value:文件内容)
-
参数优化
14.分别举例什么情况要使用 combiner,什么情况不使用?
求平均数的时候就不需要用combiner,因为不会减少reduce执行数量。在其他的时候,可以依据情况,使用combiner,来减少map的输出数量,减少拷贝到reduce的文件,从而减轻reduce的压力,节省网络开销,提升执行效率
15.MR运行流程解析
详解MapReduce执行流程
16.简单描述一下HDFS的系统架构,怎么保证数据安全?
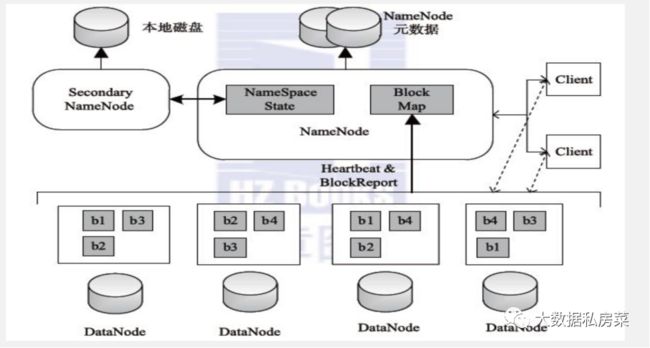
HDFS数据安全性如何保证?
-
存储在HDFS系统上的文件,会分割成128M大小的block存储在不同的节点上,block的副本数默认3份,也可配置成更多份;
-
第一个副本一般放置在与client(客户端)所在的同一节点上(若客户端无datanode,则随机放),第二个副本放置到与第一个副本同一机架的不同节点,第三个副本放到不同机架的datanode节点,当取用时遵循就近原则;
-
datanode已block为单位,每3s报告心跳状态,做10min内不报告心跳状态则namenode认为block已死掉,namonode会把其上面的数据备份到其他一个datanode节点上,保证数据的副本数量;
-
datanode会默认每小时把自己节点上的所有块状态信息报告给namenode;
-
采用safemode模式:datanode会周期性的报告block信息。Namenode会计算block的损坏率,当阀值<0.999f时系统会进入安全模式,HDFS只读不写。HDFS元数据采用secondaryname备份或者HA备份
17.在通过客户端向hdfs中写数据的时候,如果某一台机器宕机了,会怎么处理
在写入的时候不会重新重新分配datanode。如果写入时,一个datanode挂掉,会将已经写入的数据放置到queue的顶部,并将挂掉的datanode移出pipline,将数据写入到剩余的datanode,在写入结束后, namenode会收集datanode的信息,发现此文件的replication没有达到配置的要求(default=3),然后寻找一个datanode保存副本。
18.Hadoop优化有哪些方面
0)HDFS 小文件影响
(1)影响 NameNode 的寿命,因为文件元数据存储在 NameNode 的内存中
(2)影响计算引擎的任务数量,比如每个小的文件都会生成一个 Map 任务
1)数据输入小文件处理:
(1)合并小文件:对小文件进行归档(Har)、自定义 Inputformat 将小文件存储成SequenceFile 文件。
(2)采用 ConbinFileInputFormat 来作为输入,解决输入端大量小文件场景。
(3)对于大量小文件 Job,可以开启 JVM 重用。
2)Map 阶段
(1)增大环形缓冲区大小。由 100m 扩大到 200m
(2)增大环形缓冲区溢写的比例。由 80%扩大到 90%
(3)减少对溢写文件的 merge 次数。(10 个文件,一次 20 个 merge)
(4)不影响实际业务的前提下,采用 Combiner 提前合并,减少 I/O。
3)Reduce 阶段
(1)合理设置 Map 和 Reduce 数:两个都不能设置太少,也不能设置太多。太少,会导致 Task 等待,延长处理时间;太多,会导致 Map、Reduce 任务间竞争资源,造成处理超时等错误。
(2)设置 Map、Reduce 共存:调整 slowstart.completedmaps 参数,使 Map 运行到一定程度后,Reduce 也开始运行,减少 Reduce 的等待时间。
(3)规避使用 Reduce,因为 Reduce 在用于连接数据集的时候将会产生大量的网络消耗。
(4)增加每个 Reduce 去 Map 中拿数据的并行数
(5)集群性能可以的前提下,增大 Reduce 端存储数据内存的大小。
4)IO 传输
(1)采用数据压缩的方式,减少网络 IO 的的时间。安装 Snappy 和 LZOP 压缩编码器。
(2)使用 SequenceFile 二进制文件
5)整体
(1)MapTask 默认内存大小为 1G,可以增加 MapTask 内存大小为 4-5g
(2)ReduceTask 默认内存大小为 1G,可以增加 ReduceTask 内存大小为 4-5g
(3)可以增加 MapTask 的 cpu 核数,增加 ReduceTask 的 CPU 核数
(4)增加每个 Container 的 CPU 核数和内存大小
(5)调整每个 Map Task 和 Reduce Task 最大重试次数
19.大量数据求topN(写出mapreduce的实现思路)
20.列出正常工作的hadoop集群中hadoop都分别启动哪些进程以及他们的作用
1.NameNode它是hadoop中的主服务器,管理文件系统名称空间和对集群中存储的文件的访问,保存有metadate。
2.SecondaryNameNode它不是namenode的冗余守护进程,而是提供周期检查点和清理任务。帮助NN合并editslog,减少NN启动时间。
3.DataNode它负责管理连接到节点的存储(一个集群中可以有多个节点)。每个存储数据的节点运行一个datanode守护进程。
4.ResourceManager(JobTracker)JobTracker负责调度DataNode上的工作。每个DataNode有一个TaskTracker,它们执行实际工作。
5.NodeManager(TaskTracker)执行任务
6.DFSZKFailoverController高可用时它负责监控NN的状态,并及时的把状态信息写入ZK。它通过一个独立线程周期性的调用NN上的一个特定接口来获取NN的健康状态。FC也有选择谁作为Active NN的权利,因为最多只有两个节点,目前选择策略还比较简单(先到先得,轮换)。
7.JournalNode 高可用情况下存放namenode的editlog文件.
21.Hadoop总job和Tasks之间的区别是什么?
Job是我们对一个完整的mapreduce程序的抽象封装
Task是job运行时,每一个处理阶段的具体实例,如map task,reduce task,maptask和reduce task都会有多个并发运行的实例
22.Hadoop高可用HA模式
HDFS高可用原理:
Hadoop HA(High Available)通过同时配置两个处于Active/Passive模式的Namenode来解决上述问题,状态分别是Active和Standby. Standby Namenode作为热备份,从而允许在机器发生故障时能够快速进行故障转移,同时在日常维护的时候使用优雅的方式进行Namenode切换。Namenode只能配置一主一备,不能多于两个Namenode。
主Namenode处理所有的操作请求(读写),而Standby只是作为slave,维护尽可能同步的状态,使得故障时能够快速切换到Standby。为了使Standby Namenode与Active Namenode数据保持同步,两个Namenode都与一组Journal Node进行通信。当主Namenode进行任务的namespace操作时,都会确保持久会修改日志到Journal Node节点中。Standby Namenode持续监控这些edit,当监测到变化时,将这些修改同步到自己的namespace。
当进行故障转移时,Standby在成为Active Namenode之前,会确保自己已经读取了Journal Node中的所有edit日志,从而保持数据状态与故障发生前一致。
为了确保故障转移能够快速完成,Standby Namenode需要维护最新的Block位置信息,即每个Block副本存放在集群中的哪些节点上。为了达到这一点,Datanode同时配置主备两个Namenode,并同时发送Block报告和心跳到两台Namenode。
确保任何时刻只有一个Namenode处于Active状态非常重要,否则可能出现数据丢失或者数据损坏。当两台Namenode都认为自己的Active Namenode时,会同时尝试写入数据(不会再去检测和同步数据)。为了防止这种脑裂现象,Journal Nodes只允许一个Namenode写入数据,内部通过维护epoch数来控制,从而安全地进行故障转移。
23.简要描述安装配置一个hadoop集群的步骤
-
使用root账户登录。
-
修改IP。
-
修改Host主机名。
-
配置SSH免密码登录。
-
关闭防火墙。
-
安装JDK。
-
上传解压Hadoop安装包。
-
配置Hadoop的核心配置文件hadoop-evn.sh,core-site.xml,mapred-site.xml,hdfs-site.xml,yarn-site.xml
-
配置hadoop环境变量
-
格式化hdfs # bin/hadoop namenode -format
-
启动节点start-all.sh
24.fsimage和edit的区别
fsimage:filesystem image 的简写,文件镜像。
客户端修改文件时候,先更新内存中的metadata信息,只有当对文件操作成功的时候,才会写到editlog。
fsimage是文件meta信息的持久化的检查点。secondary namenode会定期的将fsimage和editlog合并dump成新的fsimage
25.yarn的三大调度策略
FIFO Scheduler把应用按提交的顺序排成一个队列,这是一个先进先出队列,在进行资源分配的时候,先给队列中最头上的应用进行分配资源,待最头上的应用需求满足后再给下一个分配,以此类推。
Capacity(容量)调度器,有一个专门的队列用来运行小任务,但是为小任务专门设置一个队列会预先占用一定的集群资源,这就导致大任务的执行时间会落后于使用FIFO调度器时的时间。
在Fair(公平)调度器中,我们不需要预先占用一定的系统资源,Fair调度器会为所有运行的job动态的调整系统资源。当第一个大job提交时,只有这一个job在运行,此时它获得了所有集群资源;当第二个小任务提交后,Fair调度器会分配一半资源给这个小任务,让这两个任务公平的共享集群资源。
需要注意的是,在下图Fair调度器中,从第二个任务提交到获得资源会有一定的延迟,因为它需要等待第一个任务释放占用的Container。小任务执行完成之后也会释放自己占用的资源,大任务又获得了全部的系统资源。最终的效果就是Fair调度器即得到了高的资源利用率又能保证小任务及时完成。
26.hadoop的shell命令用的多吗?,说出一些常用的
-ls
-put
-get
-getmerge
-mkdir
-rm
27.用mr实现用户pv的top10?
map输入数据,将数据转换成(用户,访问次数)的键值对,然后reduce端实现聚合,并且将结果写入用户、访问次数的实体类,并且实现排序,最后的结果做一个top10的筛选
28.一个文件只有一行,但是这行有100G大小,mr会不会切分,我们应该怎么解决
重写inputformat
29.hdfs HA机制,一台namenode宕机了,joualnode,namenode,edit.log fsimage的变化
HDFS HA机制 及 Secondary NameNode详解
30.Mapreduce执行流程说一下?
详解MapReduce执行流程
31.Shulffle过程瓶颈在哪里,你会怎么解决?
详解MapReduce执行流程
32.你刚说到会有小文件和数据倾斜,这个怎么处理?
Hive调优,数据工程师成神之路
33.空值key加随机数是一种数据倾斜解决方案,如果有单个key是热点值呢?又如果有多个key是热点值呢?用参数和代码分别怎么解决?
Hive调优,数据工程师成神之路
34.mr中join操作的具体原理
Hive的join底层mapreduce是如何实现的?
35.数据倾斜的处理方式
Hive调优,数据工程师成神之路
36.一个SQL在MR中经过哪些过程,比如说
select a.id, b.id
from a
join b
on a.id = b.id
在MR中是怎么join的,left join在MR中是怎么实现的?
Hive的join底层mapreduce是如何实现的?
37.HDFS中datanode之间怎么保证备份数量的同步?
38.2NN的作用?高可用中的standby namenode的作用?
HDFS HA机制 及 Secondary NameNode详解
39.怎么进行故障转移的?
HDFS HA机制 及 Secondary NameNode详解
40.hadoop的组件,各自的作用,SecondNode的作用
HDFS HA机制 及 Secondary NameNode详解
41.Yarn的源码和参数配置相关的源码细节你知道吗?
Yarn的资源调度流程
七、FLINK
1.Flink实时计算时落磁盘吗
2.日活DAU的统计需要注意什么
3.Flink调优
4.Flink的容错是怎么做的
定期checkpoint存储oprator state及keyedstate到stateBackend
5.Parquet格式的好处?什么时候读的快什么时候读的慢
6.flink中checkPoint为什么状态有保存在内存中这样的机制?为什么要开启checkPoint?
开启checkpoint可以容错,程序自动重启的时候可以从checkpoint中恢复数据
7.flink保证Exactly_Once的原理?
1.开启checkpoint
2.source支持数据重发
3.sink支持事务,可以分2次提交,如kafka;或者sink支持幂等,可以覆盖之前写入的数据,如redis
满足以上三点,可以保证Exactly_Once
8.flink的时间形式和窗口形式有几种?有什么区别,你们用在什么场景下的?
9.flink的背压说下?
10.flink的watermark机制说下,以及怎么解决数据乱序的问题?
11.flink on yarn执行流程

Flink任务提交后,Client向HDFS上传Flink的Jar包和配置,之后向Yarn ResourceManager提交任务,ResourceManager分配Container资源并通知对应的NodeManager启动ApplicationMaster,ApplicationMaster启动后加载Flink的Jar包和配置构建环境,然后启动JobManager,之后ApplicationMaster向ResourceManager申请资源启动TaskManager,ResourceManager分配Container资源后,由ApplicationMaster通知资源所在节点的NodeManager启动TaskManager,NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager,TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务。
12.说一说spark 和flink 的区别
13.flink双流join
14.flink任务提交方式
15.slot资源分配规划
16.flink消费kafka发生partition数变更,flink底层是不是reblance
17.checkpoint原理
18.checkpoint barrier对齐原理,非对齐checkpoint原理
19.checkpoint失败的场景
20.flink两段提交原理
21.flink背压的底层原理
22.onTimer同state并发操作的安全问题
23.flink kafkaConsumer源码
24.看过哪些flink源码
25.Flink savepoint和checkpoint?
26.Flink算子记得哪些?
27.Flink map和flatmap比较?
28.flink双流join说一下?
29.flink两段提交原理说一下?
30.flink的ck了解吗?可以说一下大致流程吗?
31.如果有多个barrier对齐时,有一两个一直没到该怎么处理?有没有情况下不进行等待对齐?
32.窗口和wm的关系
33.窗口的状态数据什么时候清楚?
34.Flink有哪些窗口,介绍一下区别?会话窗口关闭是什么控制得(我不会,他说是nameSpace,源码里展示了的)
35.flink的提交方式?(一脸懵逼,我说的是打jar包上传,打jar包之后给运维上线,然后用指令进行提交,
36.他给我分享的是丰巢已经做了自己的Flink提交平台,虽然还不完善,但是一些基本的功能都能实现了,比如说提交,我直呼贵公司nb)
37.Flink的编程模型
38.Flink的状态有了解吗?有哪些?
39.Flink的join相关的源码你看过吗?
40.CheckPoint源码和算法有了解过吗?
41.Flink On Yarn 之后 Yarn 会发生什么变化,源码里面的细节你知道吗?
42.Flink中状态相关的源码你知道吗?比如可以修改状态大小,取出状态的值进行修改,再放回去,等其他状态相关的操作?
43.Flink的为算子提供的状态的源码你看过吗?
44.为什么要升级成Flink?(简历上写的)
45.为什么Flink可以处理乱序,给了个关注和取消的场景,问你如何实现最终一致性问题!
46.说说SparkStreaming和Flink的区别?
47.说说Flink的精准一次性!
八、JAVA
1.hashMap底层源码,数据结构
2.写出你用过的设计模式,并举例说明解决的实际问题
3.Java创建线程的几种方式
-
继承Thread类,重写run方法
-
实现Runnable接口,实现run方法
-
通过线程池获取线程
-
实现Callable接口并实现call方法,创建该类的实例,使用FutureTask类包装Callable对象,使用FutureTask对象作为Thread对象的target创建并启用新线程
4.请简述操作系统的线程和进程的区别
5.Java程序出现OutOfMemoryError:unable to create new native thread 的原因可能有哪些?如何分析和解决?
6.采用java或自己熟悉的任何语言分别实现简单版本的线性表和链表,只需实现add,remove方法即可
7.ArrayList和LinkedList的区别
8.JVM 内存分哪几个区,每个区的作用是什么?
9.Java中迭代器和集合的区别?
集合是将所有数据加载到内存,然后通过集合的方法去内存中获取,而迭代器是一个对象,实现了Iterator接口,实现了接口的hasNext和Next方法。
10.HashMap 和 HashTable 区别
1) 线程安全性不同
HashMap 是线程不安全的,HashTable 是线程安全的,其中的方法是 Synchronize 的,
在多线程并发的情况下,可以直接使用 HashTabl,但是使用 HashMap 时必须自己增加同步
处理。
2) 是否提供 contains 方法
HashMap 只有 containsValue 和 containsKey 方法;HashTable 有 contains、containsKey
和 containsValue 三个方法,其中 contains 和 containsValue 方法功能相同。
3) key 和 value 是否允许 null 值
Hashtable 中,key 和 value 都不允许出现 null 值。HashMap 中,null 可以作为键,这
样的键只有一个;可以有一个或多个键所对应的值为 null。
4) 数组初始化和扩容机制
HashTable 在不指定容量的情况下的默认容量为 11,而 HashMap 为 16,Hashtable 不
要求底层数组的容量一定要为 2 的整数次幂,而 HashMap 则要求一定为 2 的整数次幂。
Hashtable 扩容时,将容量变为原来的 2 倍加 1,而 HashMap 扩容时,将容量变为原
来的 2 倍。
11.线程池使用注意哪些方面?
线程池分为单线程线程池,固定大小线程池,可缓冲的线程池
12.HashMap和TreeMap的区别?TreeMap排序规则?
TreeMap会自动进行排序,根据key的Compare方法进行排序
13.用java实现单例模式
14.使用递归算法求n的阶乘:n! ,语言不限
15.HashMap和Hashtable的区别是什么
16.TreeSet 和 HashSet 区别
HashSet 是采用 hash 表来实现的。其中的元素没有按顺序排列,add()、remove()以及
contains()等方法都是复杂度为 O(1)的方法。
TreeSet 是采用树结构实现(红黑树算法)。元素是按顺序进行排列,但是 add()、
remove()以及 contains()等方法都是复杂度为 O(log (n))的方法。它还提供了一些方法来处理
排序的 set,如 first(),last(),headSet(),tailSet()等等。
17.Stringbuffer 和 Stringbuild 区别
1、StringBuffer 与 StringBuilder 中的方法和功能完全是等价的。
2、只是 StringBuffer 中的方法大都采用了 synchronized 关键字进行修饰,因此是线程
安全的,而 StringBuilder 没有这个修饰,可以被认为是线程不安全的。
3、在单线程程序下,StringBuilder 效率更快,因为它不需要加锁,不具备多线程安全
而 StringBuffer 则每次都需要判断锁,效率相对更低
18.Final、Finally、Finalize
final:修饰符(关键字)有三种用法:修饰类、变量和方法。修饰类时,意味着它不
能再派生出新的子类,即不能被继承,因此它和 abstract 是反义词。修饰变量时,该变量
使用中不被改变,必须在声明时给定初值,在引用中只能读取不可修改,即为常量。修饰
方法时,也同样只能使用,不能在子类中被重写。
finally:通常放在 try…catch 的后面构造最终执行代码块,这就意味着程序无论正常执
行还是发生异常,这里的代码只要 JVM 不关闭都能执行,可以将释放外部资源的代码写在
finally 块中。
finalize:Object 类中定义的方法,Java 中允许使用 finalize() 方法在垃圾收集器将对象
从内存中清除出去之前做必要的清理工作。这个方法是由垃圾收集器在销毁对象时调用
的,通过重写 finalize() 方法可以整理系统资源或者执行其他清理工作。
19..==和 Equals 区别
== : 如果比较的是基本数据类型,那么比较的是变量的值
如果比较的是引用数据类型,那么比较的是地址值(两个对象是否指向同一块内
存)
equals:如果没重写 equals 方法比较的是两个对象的地址值。
如果重写了 equals 方法后我们往往比较的是对象中的属性的内容
equals 方法是从 Object 类中继承的,默认的实现就是使用==

20.比较ArrayList,LinkedList的存储特性和读写性能
21.Java 类加载过程
Java类加载需要经历一下几个过程:
-
加载
加载时类加载的第一个过程,在这个阶段,将完成一下三件事情:
-
通过一个类的全限定名获取该类的二进制流。
-
将该二进制流中的静态存储结构转化为方法去运行时数据结构。
-
在内存中生成该类的Class对象,作为该类的数据访问入口。
-
验证
验证的目的是为了确保Class文件的字节流中的信息不回危害到虚拟机.在该阶段主要完成以下四钟验证:
-
文件格式验证:验证字节流是否符合Class文件的规范,如主次版本号是否在当前虚拟机范围内,常量池中的常量是否有不被支持的类型.
-
元数据验证:对字节码描述的信息进行语义分析,如这个类是否有父类,是否集成了不被继承的类等。
-
字节码验证:是整个验证过程中最复杂的一个阶段,通过验证数据流和控制流的分析,确定程序语义是否正确,主要针对方法体的验证。如:方法中的类型转换是否正确,跳转指令是否正确等。
-
符号引用验证:这个动作在后面的解析过程中发生,主要是为了确保解析动作能正确执行。
-
准备
准备阶段是为类的静态变量分配内存并将其初始化为默认值,这些内存都将在方法区中进行分配。准备阶段不分配类中的实例变量的内存,实例变量将会在对象实例化时随着对象一起分配在Java堆中。
-
解析
该阶段主要完成符号引用到直接引用的转换动作。解析动作并不一定在初始化动作完成之前,也有可能在初始化之后。
-
初始化
初始化时类加载的最后一步,前面的类加载过程,除了在加载阶段用户应用程序可以通过自定义类加载器参与之外,其余动作完全由虚拟机主导和控制。到了初始化阶段,才真正开始执行类中定义的Java程序代码。
22.java中垃圾收集的方法有哪些?
23.如何判断一个对象是否存活?(或者GC对象的判定方法)
判断一个对象是否存活有两种方法:
-
引用计数法
-
可达性算法(引用链法)
24.jvm、堆栈
25.java基本数据类型
26.spring AOP应用场景
27.分布式锁的几种实现方式
28.两个数 a=3,b=5,如何不使用中间变量不使用函数情况下调换他们
29.java的快排算法实现
30.JVM原理,GC回收机制,hashMap底层原理
九、ELASTICSEARCH
1.为什么要用es?存进es的数据是什么格式的,怎么查询
十、FLUME
1.什么是flume
a.Flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。
b.Flume可以采集文件,socket数据包等各种形式源数据,又可以将采集到的数据输出到HDFS、hbase、hive、kafka等众多外部存储系统中
c.一般的采集需求,通过对flume的简单配置即可实现
d.ume针对特殊场景也具备良好的自定义扩展能力,因此,flume可以适用于大部分的日常数据采集场景
2.flume运行机制
-
Source:采集源,用于跟数据源对接,以获取数据
-
Sink:下沉地,采集数据的传送目的,用于往下一级agent传递数据或者往最终存储系统传递数据
-
Channel:angent内部的数据传输通道,用于从source将数据传递到sink
-
Flume分布式系统中最核心的角色是agent,flume采集系统就是由一个个agent所连接起来形成
-
每一个agent相当于一个数据传递员,内部有三个组件:
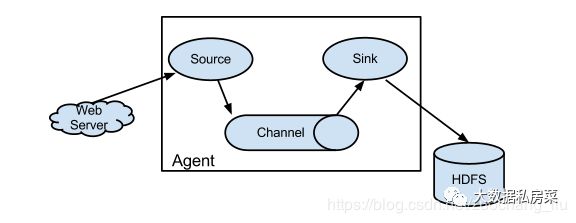
3.Flume采集数据到Kafka中丢数据怎么办
4.Flume怎么进行监控?
5.Flume的三层架构,collector、agent、storage
6.flume断点续传多久保留一次offset
7.整个flume有使用高可用吗?怎么配置高可用?
8.flume会不会丢数据
十一、SQOOP
1.Sqoop底层运行的任务是什么
只有Map阶段,没有Reduce阶段的任务。
2.sqoop的迁移数据的原理
3.Sqoop参数
/opt/module/sqoop/bin/sqoop import \
--connect \
--username \
--password \
--target-dir \
--delete-target-dir \
--num-mappers \
--fields-terminated-by \
--query "$2" ' and $CONDITIONS;'
4.Sqoop导入导出Null存储一致性问题
Hive中的Null在底层是以“\N”来存储,而MySQL中的Null在底层就是Null,为了保证数据两端的一致性。在导出数据时采用--input-null-string和--input-null-non-string两个参数。导入数据时采用--null-string和--null-non-string。
5.Sqoop数据导出一致性问题
1)场景1:如Sqoop在导出到Mysql时,使用4个Map任务,过程中有2个任务失败,那此时MySQL中存储了另外两个Map任务导入的数据,此时老板正好看到了这个报表数据。而开发工程师发现任务失败后,会调试问题并最终将全部数据正确的导入MySQL,那后面老板再次看报表数据,发现本次看到的数据与之前的不一致,这在生产环境是不允许的。
2)场景2:设置map数量为1个(不推荐,面试官想要的答案不只这个)
多个Map任务时,采用–staging-table方式,仍然可以解决数据一致性问题。
6.通过sqoop把数据加载到mysql中,如何设置主键?
十二、REDIS
1.缓存穿透、缓存雪崩、缓存击穿
1)缓存穿透是指查询一个一定不存在的数据。由于缓存命不中时会去查询数据库,查不到
数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,造成缓存穿
透。
解决方案:
① 是将空对象也缓存起来,并给它设置一个很短的过期时间,最长不超过 5 分钟
② 采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定
不存在的数据会被这个 bitmap 拦截掉,从而避免了对底层存储系统的查询压力
2)如果缓存集中在一段时间内失效,发生大量的缓存穿透,所有的查询都落在数据库上,
就会造成缓存雪崩。
解决方案:
尽量让失效的时间点不分布在同一个时间点
3)缓存击穿,是指一个 key 非常热点,在不停的扛着大并发,当这个 key 在失效的瞬间,
持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
可以设置 key 永不过期
2.数据类型

3.持久化
1)RDB 持久化:
① 在指定的时间间隔内持久化
② 服务 shutdown 会自动持久化
③ 输入 bgsave 也会持久化
2)AOF : 以日志形式记录每个更新操作
Redis 重新启动时读取这个文件,重新执行新建、修改数据的命令恢复数据。
保存策略:
推荐(并且也是默认)的措施为每秒持久化一次,这种策略可以兼顾速度和安全性。
缺点:
1 比起 RDB 占用更多的磁盘空间
2 恢复备份速度要慢
3 每次读写都同步的话,有一定的性能压力
4 存在个别 Bug,造成恢复不能
选择策略:
官方推荐:
string
字符串
list
可以重复的集合
set
不可以重复的集合
hash
类似于 Map
zset(sorted set)
带分数的 set
如果对数据不敏感,可以选单独用 RDB;不建议单独用 AOF,因为可能出现 Bug;如果只是做纯内存缓存,可以都不用
4.悲观锁和乐观锁
悲观锁:执行操作前假设当前的操作肯定(或有很大几率)会被打断(悲观)。基于这个假设,我们在做操作前就会把相关资源锁定,不允许自己执行期间有其他操作干扰。
乐观锁:执行操作前假设当前操作不会被打断(乐观)。基于这个假设,我们在做操作前不会锁定资源,万一发生了其他操作的干扰,那么本次操作将被放弃。Redis 使用的就是乐观锁。
5.redis 是单线程的,为什么那么快
1)完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。
2)数据结构简单,对数据操作也简单,Redis 中的数据结构是专门进行设计的
3)采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗
4)使用多路 I/O 复用模型,非阻塞 IO
5)使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,
Redis 直接自己构建了 VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求
6.redis的热键问题?怎么解决?
十三、MYSQL
1.请写出mysql登录命令,用户名user,密码123456,地址192.168.1.130
mysql -h 192.168.1.130 -uuser -p123456 -P3306 -Dwemeta_test
2.为什么MySQL的索引要使用B+树而不是其它树形结构?比如B树?
B树
B树不管叶子节点还是非叶子节点,都会保存数据,这样导致在非叶子节点中能保存的指针数量变少(有些资料也称为扇出)
指针少的情况下要保存大量数据,只能增加树的高度,导致IO操作变多,查询性能变低;
B+树
1.单一节点存储更多的元素,使得查询的IO次数更少。
2.所有查询都要查找到叶子节点,查询性能稳定。
3.所有叶子节点形成有序链表,便于范围查询,远远高于B-树
3.mysql中B树和B+树的原理和区别
4.mysql事务锁有几种,分别是什么
十四、数据结构与算法
1.二分查找
package com.wedoctor.search;public class Binarysearch {public static int bsearchWithoutRecursion(int arr[], int key) {int low = 0;int high = arr.length - 1;while (low <= high) {int mid = low + (high - low) / 2;if (arr[mid] > key)high = mid - 1;else if (arr[mid] < key)low = mid + 1;elsereturn mid;}return -1;}public static void main(String[] args) {int arr[] = {1,3,5,6,8,9,11,14,23};int num = bsearchWithoutRecursion(arr, 9);System.out.println(num);}}
2.快排
3.归并排序
4.冒泡排序
package com.wedoctor.sort;import java.util.Arrays;public class BubbleSort {public static void main(String[] args) {int[] arr = new int[] { 2, 8, 7, 9, 4, 1, 5, 0 };bubbleSort(arr);}public static void bubbleSort(int[] arr) {//控制多少轮for (int i = 1; i < arr.length; i++) {//控制每一轮的次数for (int j = 0; j <= arr.length -1 - i; j++) {if (arr[j] > arr[j + 1]) {int temp;temp = arr[j];arr[j] = arr[j + 1];arr[j + 1] = temp;}}}System.out.println(Arrays.toString(arr));}}
5.字符串反转
package com.wedoctor.str;public class StrReverse {public static String getNewStr(String str){StringBuffer sb = new StringBuffer(str);String newStr = sb.reverse().toString();return newStr;}public static void main(String[] args) {System.out.println(getNewStr("thjymhr"));}}
6.Btree简单讲一下
B树(B-树)是一种适合外查找的搜索树,是一种平衡的多叉树
B树的每个结点包含着结点的值和结点所处的位置
7.动态规划 最大连续子序列和
package com.wedoctor;import java.util.Arrays;public class MaxSum {public static int findMax(int arr[]){if (arr.length == 1){return arr[0];}int mid = (arr.length) / 2;int[] leftArr = Arrays.copyOfRange(arr, 0, mid);int[] rightArr = Arrays.copyOfRange(arr, mid, arr.length);int lenLeft = findMax(leftArr);int lenRight = findMax(rightArr);int lenMid = maxInMid(leftArr, rightArr);int max = Math.max(Math.max(lenLeft,lenRight),lenMid);return max;}public static int maxInMid(int left[],int right[]){int maxLeft = 0;int maxRight = 0;int tmpLeft = 0;int tmpRight = 0;for (int i = 0;i< left.length;i++){tmpLeft = tmpLeft + left[left.length - 1 - i];maxLeft = Math.max(tmpLeft,maxLeft);}for (int i = 0;i< right.length;i++){tmpRight = tmpRight + right[i];maxRight = Math.max(tmpRight,maxRight);}return maxRight + maxLeft;}public static void main(String[] args) {int arr[] = {3,-1,10};System.out.println(findMax(arr));}}
8.二叉树概念,特点及代码实现
二叉树是n(n>=0)个结点的有限集合,该集合或者为空集(称为空二叉树),或者由一个根结点和两棵互不相交的、分别称为根结点的左子树和右子树组成。
特点:
-
每个结点最多有两颗子树,所以二叉树中不存在度大于2的结点。
-
左子树和右子树是有顺序的,次序不能任意颠倒。
-
即使树中某结点只有一棵子树,也要区分它是左子树还是右子树。
实现:
package com.wedoctor;public class BinaryTreeNode {int data;BinaryTreeNode left;BinaryTreeNode right;BinaryTreeNode (int x) {data= x;}public BinaryTreeNode(int data, BinaryTreeNode left, BinaryTreeNode right) {this.data = data;this.left = left;this.right = right;}public int getData() {return data;}public void setData(int data) {this.data = data;}public BinaryTreeNode getLeft() {return left;}public void setLeft(BinaryTreeNode left) {this.left = left;}public BinaryTreeNode getRight() {return right;}public void setRight(BinaryTreeNode right) {this.right = right;}}
9.链表
10.算法题:两数之和
11.用你最熟悉的编程语言(java,python,scala)写一个二分查找(牛客网在线写)
12.两个数 a=3,b=5,如何不使用中间变量不使用函数的情况下调换他们
13.将字符串进行编码,如aabbcc编码成a_2_b_2_c_2;b. 将输入的UNIX路径格式化,如/a/b/./../c,格式化为/a/c
十五、LINUX
1.怎么查看用户组
2.怎么修改文件权限
3.常用的命令有哪些
4.怎么修改文本文件第一行字符
5.查看内存
top
6.查看磁盘存储情况
df -h
7.查看磁盘IO读写(yum install iotop安装)
iotop
8.直接查看比较高的磁盘读写程序
iotop -o
9.查看端口占用情况
netstat -tunlp | grep 端口号
10.查看报告系统运行时长及平均负载
uptime
11.查看进程
ps aux
十六、KYLIN
1.Kylin调优?
Cube调优
l剪枝优化(衍生维度,聚合组,强制维度,层级维度,联合维度)
l并发粒度优化
lRowkeys优化(编码,按维度分片,调整维度顺序)
l降低度量精度
l及时清理无用的segment
Rowkey调优
lKylin rowkey的编码和压缩选择
l维度在rowkey中顺序的调整,
l将过滤频率较高的列放置在过滤频率较低的列之前,
l将基数高的列放置在基数低的列之前。
l在查询中被用作过滤条件的维度有可能放在其他维度的前面。
充分利用过滤条件来缩小在HBase中扫描的范围, 从而提高查询的效率。
2.Kylin的优点和缺点?
优点:预计算,界面可视化
缺点:依赖较多,属于重量级方案,运维成本很高
不适合做即席查询
预计算量大,非常消耗资源
3.Kylin的rowkey如何设计?
Kylin rowkey的编码和压缩选择
维度在rowkey中顺序的调整,
将过滤频率较高的列放置在过滤频率较低的列之前,
将基数高的列放置在基数低的列之前。
在查询中被用作过滤条件的维度有可能放在其他维度的前面。
充分利用过滤条件来缩小在HBase中扫描的范围, 从而提高查询的效率。
4.Kylin的cuboid,cube和segment的关系?
Cube是所有cubiod的组合,一个cube包含一个或者多个cuboid
Cuboid 在 Kylin 中特指在某一种维度组合下所计算的数据。
Cube Segment 是指针对源数据中的某一片段,全量构建的cube只存在唯一的segment,该segment没有分割时间的概念,增量构建的cube,不同时间的数据分布在不同的segment中
5.一张hive宽表有5个维度,kylin构建cube的时候我选了4个维度,我select *的时候会有几个维度字段?
所以只能查询出4个字段
6.其他olap工具有了解过吗?
了解过,kylin,druid
7.kylin熟吗?kylin你一般怎么调优
Cube调优
l剪枝优化(衍生维度,聚合组,强制维度,层级维度,联合维度)
l并发粒度优化
lRowkeys优化(编码,按维度分片,调整维度顺序)
l降低度量精度
l及时清理无用的segment
Rowkey调优
lKylin rowkey的编码和压缩选择
l维度在rowkey中顺序的调整,
l将过滤频率较高的列放置在过滤频率较低的列之前,
l将基数高的列放置在基数低的列之前。
l在查询中被用作过滤条件的维度有可能放在其他维度的前面。
充分利用过滤条件来缩小在HBase中扫描的范围, 从而提高查询的效率。
8.kylin的原理和优化。
Cube调优
l剪枝优化(衍生维度,聚合组,强制维度,层级维度,联合维度)
l并发粒度优化
lRowkeys优化(编码,按维度分片,调整维度顺序)
l降低度量精度
l及时清理无用的segment
Rowkey调优
lKylin rowkey的编码和压缩选择
l维度在rowkey中顺序的调整,
l将过滤频率较高的列放置在过滤频率较低的列之前,
l将基数高的列放置在基数低的列之前。
l在查询中被用作过滤条件的维度有可能放在其他维度的前面。
充分利用过滤条件来缩小在HBase中扫描的范围, 从而提高查询的效率。
9.为什么kylin的维度不建议过多
Cube 的最大物理维度数量 (不包括衍生维度) 是 63,但是不推荐使用大于 30 个维度的 Cube,会引起维度灾难。
10.Kylin的构建过程是怎么样的
-
选择model
-
选择维度
-
选择指标
-
cube设计(包括维度和rowkeys)
-
构建cube(mr程序,hbase存储元数据信息及计算好的数据信息)
11.Kylin维度优化有几种类型
-
衍生维度
-
聚合组
-
强制维度
-
层级维度
-
联合维度
12.Kylin的构建算法
快速构建算法(inmem)
也被称作“逐段”(By Segment) 或“逐块”(By Split) 算法,从1.5.x开始引入该算法,利用Mapper端计算先完成大部分聚合,再将聚合后的结果交给Reducer,从而降低对网络瓶颈的压力。该算法的主要思想是,对Mapper所分配的数据块,将它计算成一个完整的小Cube 段(包含所有Cuboid);每个Mapper将计算完的Cube段输出给Reducer做合并,生成大Cube,也就是最终结果;如图所示解释了此流程。
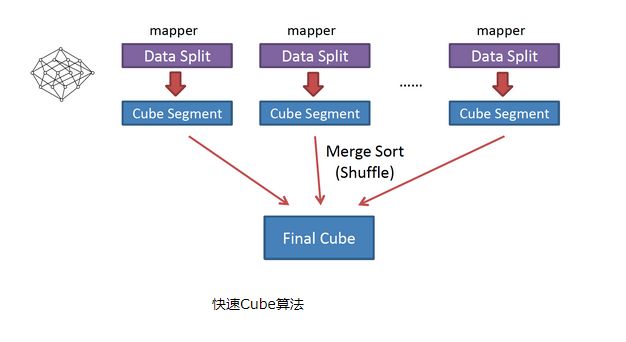
与旧算法相比,快速算法主要有两点不同:
-
Mapper会利用内存做预聚合,算出所有组合;Mapper输出的每个Key都是不同的,这样会减少输出到Hadoop MapReduce的数据量,Combiner也不再需要;
-
一轮MapReduce便会完成所有层次的计算,减少Hadoop任务的调配。

一文探究数据仓库体系(2.7万字建议收藏)
一文探究Hadoop(3万字长文,建议收藏)
一文带你走进HIVE的世界(1.8W字建议收藏)
一文带你全方位了解Flink(3.2W字建议收藏)
你要悄悄学会HBase,然后惊艳所有人(1.7万字建议收藏)
一文带你深入了解kafka并提供52道企业常见面试题(1.8W字建议收藏)
非常全面的DolphinScheduler(海豚调度)安装使用文档
Hive调优,数据工程师成神之路
数据质量那点事
简述元数据管理
简单聊一聊大数据学习之路