bug日记|bug解决思路|几个常见报错|解决方法
bug日记|bug解决思路|几个常见报错|解决方法
大家好,这里是【来一块葱花饼】,这次带来了一篇bug日记,记录之前遇到的几个常见bug,也方便自己以后回忆。欢迎关注,与你分享~
文章目录
- bug日记|bug解决思路|几个常见报错|解决方法
-
- debug解决问题的思路和流程
- ModuleNotFoundError: No module named
- 看日志报错
- FileExistsError: [Errno 17] File exists: './work_dirs/.eval_hook'
- 问题描述
-
- 猜测两个原因
- 解决方法
- bug日记--报错--died with Signals.SIGKILL: 9>
-
- 1.错误描述
- 2.网上资料
- 3.错误定位
- 4.解决方法总结
- bug日记--更新环境配置
-
- 报错
- 问题分析
- 问题解决
- 问题总结
- bug日记—学习率太大,导致loss=nan
- bug日记:debug连接失败和服务器反应过慢
-
- debug连接失败
- 服务器反应过慢
- 问题原因
- 解决方法
debug解决问题的思路和流程
debug查看问题:
1.先看报错。
2.debug、ipython定位。
3.打印输出,再去看正确的输出,对比二者的异同,这样基本就知道出了什么问题了。
4.去思考产生问题的原因,从根本上去解决问题。
看代码:
1.有报错,再具体看看函数的操作是什么
2.看正确的应该是什么,看自己的问题是什么,分析错误从哪里来
3.看问题要深入
ModuleNotFoundError: No module named
经典报错:ModuleNotFoundError: No module named XXX

但是通过conda list可以查到相关的第三方包
所以就是路径不对
方法一:

#在python文件中加入以下语句,直接导入:
import sys
sys.path.append('/anaconda3/envs/mmdetectionNew/lib/python3.6/site-packages/addict')
方法二:
查看终端的执行语句

发现使用的并不是虚拟环境的python路径,那当然会报错,毕竟第三方包安装在虚拟环境里
改过来就好了:
/anaconda3/envs/mmdetectionNew/bin/python /mmdetection/demo/firstdemo.py
方法三:
直接通过export设置全局变量,使用指定的python解释器
export PYTHONPATH=/anaconda3/envs/mmself/lib/python3.6/site-packages:$PYTHONPATH
注意:如果只是在终端直接输入这个语句,下次重启系统就会失效:如果是写入.bashrc文件,那就会永久有效
看日志报错

第一台机器的log看不出问题,可以看看别的机器,只要有一个失败了所有机器就会stop:

FileExistsError: [Errno 17] File exists: ‘./work_dirs/.eval_hook’
问题描述
mmcls正常train过程中,进行多个机器的分布式训练,运行多个epoch之后,会报错:
FileExistsError: [Errno 17] File exists: './work_dirs/.eval_hook'
这个.eval_hook应该是中间文件,训练结束后,会自动生成
由于我是多个机器训练,所以怀疑是每个机器训练之后都想生成这个文件,所以产生冲突,导致训练失败
但是之前就没有遇到过这个情况,同样的代码换了数据集和batchsize就会报错这个
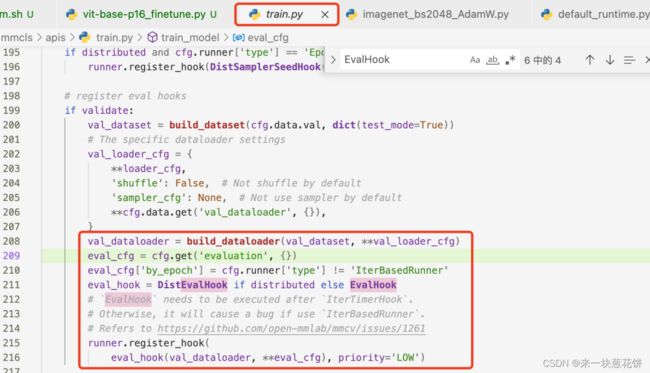
猜测两个原因
1.由于平台多机器进行分布式训练,每个机器都想生成这部分文件,所以报错:文件已存在
2.mmcls对于多机器训练,在一些设置下,是有bug的
解决方法
重新进行断点训练
有时候不报错,有时候报错
报错了之后,重新进行断点训练
bug日记–报错–died with Signals.SIGKILL: 9>
1.错误描述
使用pytorch训练模型,毫无征兆的kill掉进程:
2.网上资料
died with

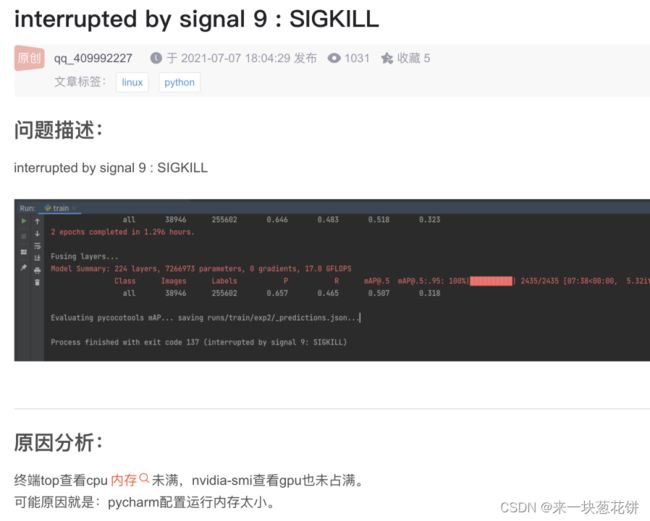
但是使用top指令发现并没过多使用cpu内存。
3.错误定位
进入这个launch.py文件进行查看:
进入main函数后,定位到这里

这里表示产生一个sigkill信号,即sigkill_handler(signal.SIGTERM, None)
这是因为process.returncode != 0
进一步定位:
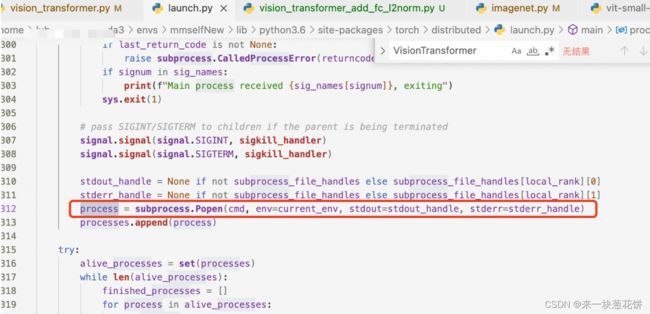

错误确实来自于这里,进一步定位,看前一个错误来自于哪里
查看该函数所在部分,刚好是一个for循环,输出for循环开头的信息,看是否正确
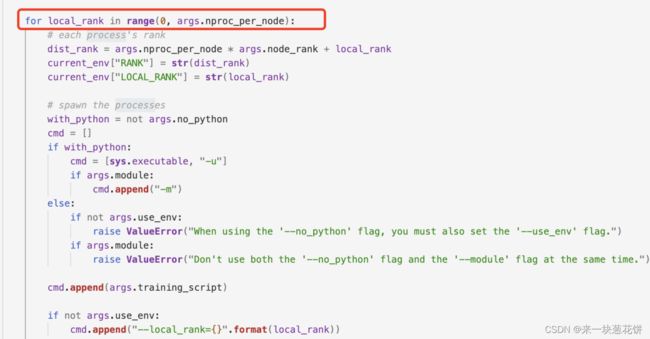
print一下:
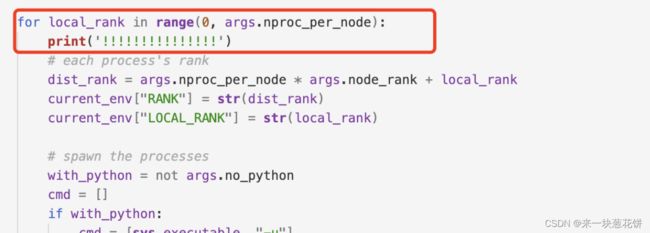

发现执行了8次,也就是说args.nproc_per_node=8
nproc_per_node表示gpu卡的数目,说明使用了8张卡!!
错误找到!说明错误设置了gpu的数目,本地此时只有一张卡。
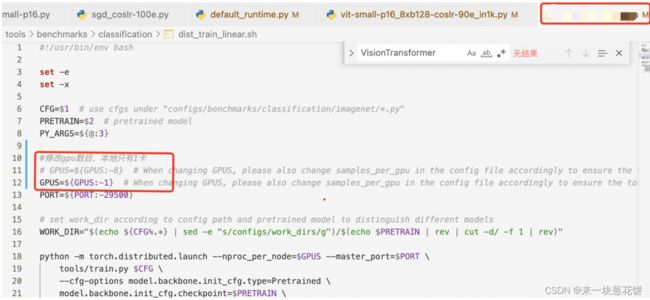
修改正确!跑通:
4.解决方法总结
解决思路:
1.看报错,看具体的报错原因和位置
2.查资料,查看相关代码的含义和问题
3.debug定位,逐层定位错误,从报错的地方不断往回推,可以print相关结果,查看错误
4.找到错误,进行改正
bug日记–更新环境配置
跑现成的代码和框架,绝大部分报错都是因为环境没配好、版本没装对
报错
mmselfsup更新工程后,
File "/anaconda3/envs/mmselfNew/lib/python3.6/site-packages/mmcv/utils/registry.py", line 55, in build_from_cfg
raise type(e)(f'{obj_cls.__name__}: {e}')
AttributeError: Classification: MIMVisionTransformer: 'MIMVisionTransformer' object has no attribute 'patch_resolution'
Killing subprocess 4237

问题分析
一方面,在模型各个部分会有相关模块的注册,最后在mmcv的registry.py函数中调用。可能是因为前面部分的注册部分出了错,才在最后报错。这里刚好就是cls部分出错(一般为分类头),所以应该看mmcls
另一方面,由于报错的是第三包里的问题,我也没有做相关修改,所以大概率是mmcls需要升级。
而且,我是由于升级了mmselfsup工程才报错的,所以基本可以确定是由于环境中的mmcls没有对应的升级
问题解决
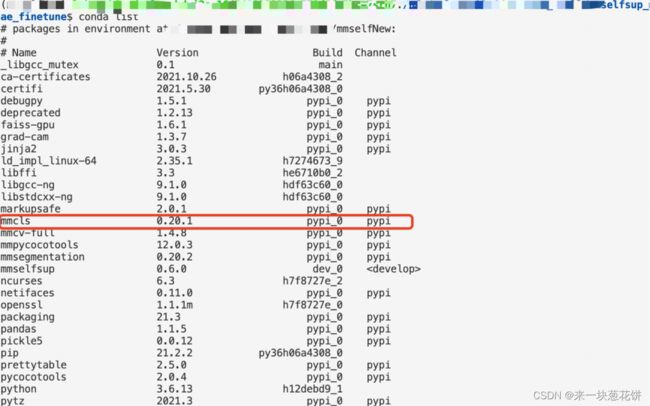
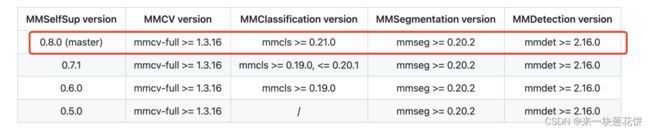
所以需要更新:
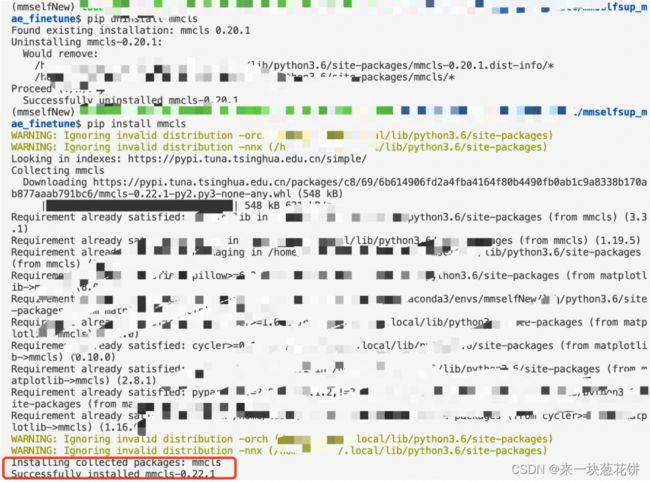
成功:
问题总结
遇到环境报错,要么是包的版本不对、没装好,要么是路径不对
升级/更新mm框架的工程后,要升级对应环境中的包。一般分为下面几步:
git clone https://github.com/open-mmlab/mmselfsup.git
cd mmselfsup
# 这样对应工程就不是python环境中的预装包了,在工程中修改代码,会直接生效
pip install -v -e .
#安装或者升级第三方包
pip install mmsegmentation mmdet
bug日记—学习率太大,导致loss=nan
总结:
1.NaN 属性代表一个“不是数字”的值。这个特殊的值是因为运算不能执行而导致的,不能执行的原因要么是因为其中的运算对象之一非数字(例如, "abc" / 4),要么是因为运算的结果非数字(例如,除数为零)。
2.NaN是一个特殊的数,比如一个数被0除、对-1开平方,结果是一个非法的数
3.math.isnan() 函数,测试一个数字是否等于 NaN,运算时含有NaN时,结果也必定是NaN。
4.如果一个数被0除,你可以理解为该数接近于无穷大,但是NaN不是无穷大,NaN表示一个错误的数

NaN是一个特殊的数,比如一个数被0除,结果是一个非法的数
深度学习中:
由于学习率太大,容易出现学到错误信息的情况(梯度计算的过程中,跳过正确的答案,进入错误的路线),有时候会错的离谱,就会出现NaN这种结果。所以可以通过修改NaN来解决。
bug日记:debug连接失败和服务器反应过慢
debug连接失败
用vscode进行debug的时候,使用launch.json,一直报错:
File "./.vscode-server/extensions/ms-python.python-2022.0.18.../pythonFiles/lib/python/debugpy/launcher/../../debugpy/launcher/__init__.py", line 34, in connect
sock.connect((host, port))
ConnectionRefusedError: [Errno 111] Connection refused
其中一个参考的解决方法:
https://gitlab.tails.boum.org/tails/tails/-/issues/18724
但是无效。。。
服务器反应过慢
第二天登陆服务器。每一步终端操作都很慢,新建个bash终端,都要等很久。
这个操作,平常只需要两分钟。已经等了十分钟了。
问题原因
更同事交流后,发现使用这个volume存储空间的操作都很慢(所以,关于机器的问题,不是自己代码和操作的原因,就要去问工作人员,而不是去一直浪费自己时间)
由于使用的配置是:服务器的隔离环境+公共使用的存储空间。
检查发现,有人将数据集存在volume存储空间上,在训练的时候反复读取数据,占用了大量的io资源,导致vscode进行debug连接失败、没有socker接口,以及volume操作极其缓慢。
解决方法
让同事把训练停止,就好很多了。
另一种解决方法:
把代码都复制到隔离环境里,原先的环境也在隔离环境里,一下子就变得很快了,这是运行最快的方式了!
以后就将代码复制到隔离环境,在隔离环境进行debug和开发:
1.快捷、反应快。2.安全,轻易不会删除隔离环境。3.隔段时间将代码备份到volume下,防止丢失信息
码字不易,都看到这里了不如点个赞哦~
这里是【来一块葱花饼】,你的点赞+收藏+关注,就是我坚持下去的最大动力~
