pytorch基础操作(七)暂退法(dropout)
1、暂退法
暂退法在前向传播过程中,计算每⼀内部层的同时注⼊噪声,这已经成为训练神经⽹络的常⽤技术。这种⽅法之所以被称为暂退法,因为我们从表⾯上看是在训练过程中丢弃(dropout)⼀些神经元。 在整个训练过程的每⼀次迭代中,标准暂退法包括在计算下⼀层之前将当前层中的⼀些节点置零。
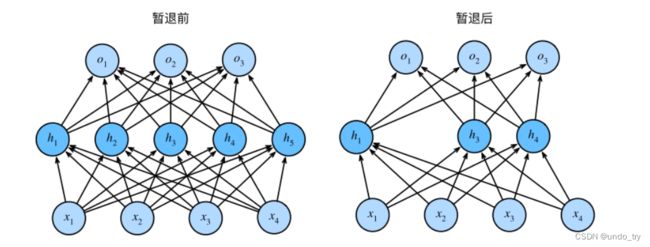
通常,我们在测试时不⽤暂退法。给定⼀个训练好的模型和⼀个新的样本,我们不会丢弃任何节点,因此不需要标准化。
2、实现单层暂退法
import torch
from torch import nn
def dropout_layer(X, dropout):
"""dropout_layer 函数,该函数以dropout的概率丢弃张量输⼊X中的元素,如上所述重新缩放剩余部分:将剩余部分除以1.0-dropout。"""
assert 0 <= dropout <= 1
# 在本情况中,所有元素都被丢弃
if dropout == 1:
return torch.zeros_like(X)
# 在本情况中,所有元素都被保留
if dropout == 0:
return X
mask = (torch.randn(X.shape) > dropout).float()
return mask * X / (1.0 - dropout)
X= torch.arange(16, dtype = torch.float32).reshape((2, 8))
print(X)
print(dropout_layer(X, 0.0))
print(dropout_layer(X, 0.5))
print(dropout_layer(X, 1.0))

1、读取服装分类数据集 Fashion-MNIST
'''
1、读取服装分类数据集 Fashion-MNIST
'''
import torchvision
from torch.utils import data
from torchvision import transforms
def get_dataloader_workers():
"""使⽤4个进程来读取数据"""
return 4
def get_mnist_data(batch_size, resize=None):
trans = [transforms.ToTensor()]
if resize:
# 还接受⼀个可选参数resize,⽤来将图像⼤⼩调整为另⼀种形状
trans.insert(0,transforms.Resize(resize))
trans = transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(
root='../data',train=True,transform=trans,download=False
)
mnist_test = torchvision.datasets.FashionMNIST(
root='../data',train=False,transform=trans,download=False
)
# 数据加载器每次都会读取⼀⼩批量数据,⼤⼩为batch_size。通过内置数据迭代器,我们可以随机打乱了所有样本,从⽽⽆偏⻅地读取⼩批量
# 数据迭代器是获得更⾼性能的关键组件。依靠实现良好的数据迭代器,利⽤⾼性能计算来避免减慢训练过程。
train_iter = data.DataLoader(mnist_train,batch_size=batch_size,shuffle=True,num_workers=get_dataloader_workers())
test_iter = data.DataLoader(mnist_test,batch_size=batch_size,shuffle=True,num_workers=get_dataloader_workers())
return (train_iter,test_iter)
2、定义模型参数
'''
2、定义模型参数
我们定义具有两个隐藏层的多层感知机,每个隐藏层包含256个单元。
'''
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
3、定义模型,搭建网络
'''
3、定义模型,搭建网络
'''
# 我们可以将暂退法应⽤于每个隐藏层的输出(在激活函数之后),并且可以为每⼀层分别设置暂退概率:
# 常⻅的技巧是在靠近输⼊层的地⽅设置较低的暂退概率。
dropout1, dropout2 = 0.2, 0.5
class Net(nn.Module):
def __init__(self,num_inputs, num_outputs, num_hiddens1, num_hiddens2,is_training = True):
super(Net, self).__init__()
self.num_inputs = num_inputs
self.is_training = is_training
self.lin1 = nn.Linear(num_inputs, num_hiddens1)
self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)
self.lin3 = nn.Linear(num_hiddens2, num_outputs)
self.relu = nn.ReLU()
def forward(self, X):
H1 = self.relu(self.lin1(X.reshape((-1, self.num_inputs))))
# 只有在训练模型时才使⽤dropout
if self.is_training == True:
# 在第⼀个全连接层之后添加⼀个dropout层
H1 = dropout_layer(H1, dropout1)
H2 = self.relu(self.lin2(H1))
if self.is_training == True:
# 在第⼆个全连接层之后添加⼀个dropout层
H2 = dropout_layer(H2, dropout2)
out = self.lin3(H2)
return out
net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
4、loss函数
'''
4、loss函数
'''
loss = nn.CrossEntropyLoss(reduction='none')
5、训练
'''
5、训练
'''
# 将迭代周期数设置为10,并将学习率设置为0.1
num_epochs = 10
lr = 0.5
batch_size = 256
# 梯度下降
trainer = torch.optim.SGD(net.parameters(),lr=lr)
# 加载数据
train_iter, test_iter = get_mnist_data(batch_size)
from EpochTrainClass import epoch_train, evaluate_accuracy
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater):
for epoch in range(num_epochs):
print(f"epoch: {epoch + 1}")
train_metrics = epoch_train(net,train_iter,loss,updater)
print(f'训练loss: {train_metrics[0]},训练精确率: {train_metrics[1]}')
test_acc = evaluate_accuracy(net,test_iter)
print(f'测试精确率: {test_acc}')
train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)

6、模型的预测
'''
6、模型的预测
'''
def get_fashion_mnist_labels(labels):
"""返回Fashion-MNIST数据集的⽂本标签"""
text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat',
'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']
return [text_labels[int(i)] for i in labels]
def predict_ch3(net,test_iter, n=8):
for X,y in test_iter:
trues = get_fashion_mnist_labels(y[0:n])
preds = get_fashion_mnist_labels(
net(X).argmax(axis=1)[0:n]
)
print('trues:',trues)
print('preds:',preds)
break
predict_ch3(net,test_iter)

3、暂退法的简洁实现
'''
二、暂退法的简洁实现
'''
from torch.nn import Sequential, Flatten, Linear,ReLU,Dropout
# 搭建神经网络
class Net2(nn.Module):
def __init__(self):
super(Net2, self).__init__()
self.model = Sequential(
Flatten(),
Linear(in_features=784, out_features=256),
ReLU(),
# 在第⼀个全连接层之后添加⼀个dropout层
Dropout(dropout1),
nn.Linear(256, 256),
ReLU(),
# 在第⼆个全连接层之后添加⼀个dropout层
Dropout(dropout2),
Linear(256, 10)
)
def forward(self, X):
X = self.model(X)
return X
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net = Net2()
net.apply(init_weights)
# 梯度下降
trainer = torch.optim.SGD(net.parameters(),lr=lr)
train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)
