IPv4的三种寻址方式(分类寻址,子网寻址到最新的CIDR寻址)
目录
- 前言
- IPv4地址相关定义
- 分类寻址
-
- 分类寻址的定义
- 分类寻址的缺点
- 子网寻址
-
- 子网寻址的定义
- 子网寻址的好处
- 子网寻址的额外开销(子网掩码)
-
- 子网掩码的定义
- 用子网掩码计算子网的起始地址,最后地址,子网地址个数
- 变长子网掩码 (IP Variable Length Subnet Masking, VLSM)
- 无分类编址CIDR
-
- CIDR诞生的原因
- CIDR的定义
- CIDR的聚合
- CIDR最长前缀匹配
- CIDR的三个限制条件
- CIDR和子网寻址的对比
前言
IPv4地址我初学时觉得非常困难,乍一看是一个很简单的概念,可是每本专业书都花了相当大的笔墨去讲解,而且每本书都没讲全。
后来我把4个计算机网络的专业书放到一起来看,终于明白了。
其实是因为IPv4地址的概念从诞生初期的分类寻址到如今的CIDR寻址,经历了3个大的阶段的变化。每个阶段都修修补补,逐步完善了前一代的缺点。
有的书是直接讲解最新的CIDR寻址,有的书却讲了以前的分类寻址和子网寻址。这才导致很多人看起来云里雾里。
我认为最好是从分类寻址一步步学过来,体会每个阶段为什么要这样做,下一个阶段是怎么在上一个阶段的过程中完善的。
很多概念自然而然就可以理解了。
所以,我自己写了一篇博文,完整的讲述了IPv4地址的三种寻址方式。
IPv4地址相关定义
IPv4地址定义:就是给互联网上的每一台主机(或路由器)的每一个接口分配一个在全世界范围内唯一且通用的32位的标识符。
补充:接口的定义:主机与物理链路之间的边界叫做接口。
IP地址的作用就是帮助逻辑寻址,完成路由的工作。由于路由器有多个接口(至少也有2个接口,输入接口和输出接口),所以每个接口都需要一个IP地址,IP地址是和接口相关联的。
IP地址必须满足唯一性和通用性,因为所有的主机必须依靠唯一通用的IP地址,才可以被因特网上的其他设备区别开来。
IPv4长度:32位。
IPv4最大地址个数: 2 32 2^{32} 232,十进制为4,294,967,296。最大地址个数也被称为地址空间。
IPv4地址标记法:二进制标记法和点分十进制标记法。
二进制标记法:用01字符串表示IP地址,每个字节间隔一个空格。
举例:01110101 10010101 00011101 00000010
点分十进制标记法:把每个字节的二进制数转换为十进制数字,也就需要4个十进制数字表示IP地址,数字之间用.隔开。
举例:192.168.1.3
分类寻址
分类寻址的定义
分类寻址是已经被淘汰的体系结构,但学习它有助于理解其他的体系结构。
IP地址最开始的体系结构是分类寻址,分类寻址把地址空间划分为5类:A、B、C、D、E五类。
每类地址的区别在于第一个字节,如下图所示:
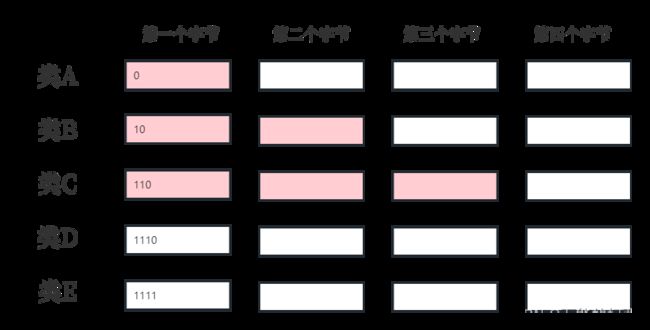
A类的第一个字节范围是:0~127(这些十进制数字对应二进制数字第一位是0)
B类的第一个字节范围是:128~191
C类的第一个字节范围是:192~223
D类的第一个字节范围是:224~239
E类的第一个字节范围是:240~255
每一类地址都有不同的应用场景:
A类地址是为那些具有大量的主机或路由器的大型组织机构所设计的。
B类地址是为可能具有数万台主机或路由器的中型组织机构所设计的。
C类地址是为那些具有少量主机或者路由器的小型组织机构设计的。
A、B、C类地址都是单播地址(很少一部分地址会在特殊情况下使用)。
D类地址为多播使用。
E类地址为保留地址。
A、B、C类的每个IP地址都由两个固定长度的字段组成(D类和E类则不是),第一个字段称为网络号,网络号标识主机和路由器所在的网络,第二个字节称为主机号,主机号标识某个特定网络下的某个接口。
A类地址的网络号是1个字节,第一个字节的第一位固定为0,是类别位。剩下7位可供使用,一共有 2 7 − 2 2^{7} - 2 27−2 = 126(128 - 2)个可用的网络号。因为00000000和01111111这2个特殊数字被用作特殊用途。也就是,只能给最多126个大型组织机构分配A类地址。
A类地址的主机号是3个字节,每个被分配A类地址的大型组织机构,可以分配 2 24 2^{24} 224 - 2 = 16,777,214个A类单播IP地址。主机号为全0或者全1的地址被用作特殊用途,所以要-2。
B类地址的网络号是2个字节,第一个字节的前两位固定为10,是类别位。剩下14位可供使用,一共有 2 14 − 1 2^{14} - 1 214−1 = 16,383个可用的B类网络号。B类地址的网络号其实不存在全0或者全1的说法(因为开头固定为10),但是10000000 00000000也就是128.0这个网络号一般是不指派的,所以需要减1。
B类地址的主机号是2个字节,可以分配 2 16 2^{16} 216 - 2 = 65,534个B类单播IP地址,主机号为全0或者全1被用作特殊用途。
C类地址的网络号是3个字节,第一个字节的前3位固定为110,是类别位。剩下21位可供使用,一共有 2 21 − 1 2^{21} - 1 221−1 = 2,097,151个可用的C类网络号。192.0.0这个网络号一般不使用,所以需要减1。
C类地址的主机号是1个字节,可以分配 2 8 2^{8} 28 - 2 = 254个C类单播IP地址,主机号为全0或者全1被用作特殊用途。
IP地址的有效指派范围如下表格:
| 网络类别 | 最大可指派的网络数 | 第一个可指派的网络号 | 最后一个可指派的网络号 | 每个网络中的最大主机数 |
|---|---|---|---|---|
| A | 126 | 1 | 126 | 16,777,214 |
| B | 16,383 | 128.1 | 191.255 | 65,534 |
| C | 2,097,151 | 192.0.1 | 223.255.255 | 254 |
分类寻址的缺点
分类寻址有3个主要的缺点。
1.IP地址空间的利用率很低。
A类地址有超过一千万个可分配地址,这几乎比所有的组织机构的需要都要大。
B类地址也有超过六万个地址,远超过大部分中型组织的需求。
而C类地址只有254个可分配地址,大部分小型组织的需求都可能超过这个数量。
这就导致A和B类网络提供的地址都过多了,C类又过少了。
D类地址是为多播而设计的,因特网管理机构错误地预测需要268,435,456组( 2 28 2^{28} 228),这里浪费了太多的地址。
E类地址也仅有少数几个被使用,这也引起了地址的浪费。
看上表可以得知,A类网络只有126个,B类也只有16,383个,A类和B类地址很快就被用完了,而对于大部分中型企业,C类地址又不够用。
所以,有人想出了一个暂时能解决问题的办法:超网化(supernetting)。超网是将几个C类地址构成更大范围的地址空间给一个组织使用,比如一个需要1000个地址的组织机构可以申请4个C类地址块。
2.路由表的负荷太大,从而使整个互联网的性能下降。
即使我们IP地址的资源足够给每一个物理网络分配一个网络号,但是路由器的路由表项目数量也会过多,比如C类地址太多,很多中小公司利用超网,一个公司会用很多个C类地址,每个C类地址都需要在路由器拥有一个表项,或者在分配B类网络的公司内部路由器,主机过多,需要的表项也很多。这样查找路由会耗费过多的时间,路由器定期交换路由信息需要更多开销,从而使得整个互联网的性能下降。
3.两级IP地址不够灵活。
要想让一个新的单位连接上互联网,就必须向互联网管理机构ICANN组织申请新的网络号。假如一个单位需要去新的地点立刻开通新的网络,就必须提前去申请新的IP地址,这样做是非常不方便的。
子网寻址
子网寻址的定义
子网寻址是为了解决上面分类寻址第二点和第三点的缺点,诞生的一种新的技术。
其实很简单,就是将主机号进行进一步划分,分成子网号+主机号。
比如对于一个B类网络,前2个字节还是网络号,但原来后2个字节的主机号可以被分为子网号+主机号。比如,分配1个字节为子网号,1个字节为主机号。那么这个B类网络一共有256个子网,每个子网可以有254个主机号。

对于某个网络的外部,子网的具体划分是不可见的,外部只能看到网络号,认为它们是一个网络。
但是,对于网络的内部,可以根据不同的子网号,划分成不同的子网,每个子网都有一定数量的主机号。
子网寻址的好处
这样做有很多好处:
1.某个网络内部可以随时根据具体情况,重新进行子网的划分,网络外部对这些都是不可见的,不需要和外部的网络协调。
2.网络内部更加贴近真实的网络物理结构,可以让子网对应的主机号数量更加接近真实所需的接口数量。
3.路由表的表项数量大幅度减少。对于某个网络外部的路由器,只需要管理网络号即可。对于网络内部的路由器,可以根据子网配置路由器表项,这比直接根据主机配置表项要大大减少表项的开销。
4.当一个已经分配B类网络的公司需要去新地点连接互联网时,不需要再向ICANN组织申请新的网络地址空间,只需要增加一个子网给新地点即可。
子网寻址的额外开销(子网掩码)
子网掩码的定义
之前分类寻址是靠第一个字节的前几位类别位,来区分某个IP地址到底是哪一类网络,再根据是A、B或者C类网络,确定网络号和主机号的长度。但并没有办法确定某个网络如何进行了子网的划分。
所以,路由器要识别子网需要额外的开销,也就是子网掩码。
子网掩码是由一串1和跟随的一串0组成。0的长度为主机号的个数,1的长度是网络号+子网号的个数。
比如:11111111 11111111 11111111 00000000(255.255.255.0)
要确定原本的主机号到底用了几位作为子网号,只需要让IP地址和子网掩码逐位做逻辑与的操作。
逻辑与会让IP地址的主机号部分变为0,留下网络号+子网号,这样就可以确定该IP地址到底属于哪一个子网。
为了方便表示,我们可以在IP地址后加 “/n” 来表示一串1的长度,这个n就是网络号+子网号的长度。
用子网掩码计算子网的起始地址,最后地址,子网地址个数
子网掩码+某个子网其中任意一个地址,就可以计算出整个子网的起始地址,最后地址,子网地址个数。
公式很简单,也很好理解。
计算子网的起始地址:子网掩码和任意地址逻辑与(and)
因为子网掩码的1的个数 = 网络号+子网号的长度,而同一个子网的地址,网络号和子网号部分都是一致的。
通过逻辑与的操作,就可以把网络号和子网号部分提取出来,而主机号部分会全部变成0。
而子网的起始地址就是主机号全为0的地址,所以,逻辑与就把它计算出来了。
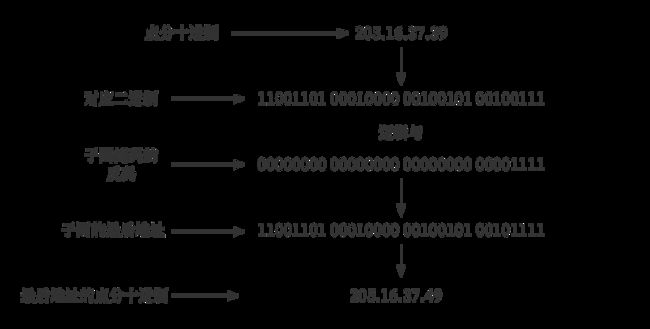
举例:某个子网的某个地址为205.16.37.39,子网掩码为/28。
计算起始地址方法如图:

计算子网的最后地址:子网掩码的反码和任意地址逻辑或
子网掩码的反码是,网络号+子网号的个数是一串0的个数,主机号的个数是一串1的个数。
子网掩码的反码和任意地址进行逻辑或后,网络号和子网号部分保留,主机号部分全部变为1。
举例:某个子网的某个地址为205.16.37.39,子网掩码为/28。
计算最后地址方法如图:
计算子网的地址个数:只需要将子网掩码的反码取反再+1
比如子网掩码是/28,取反后为00000000 00000000 00000000 00001111 = 15,加1就是16 = 2 4 2^{4} 24个。
变长子网掩码 (IP Variable Length Subnet Masking, VLSM)
子网划分有一个潜在问题,子网号的长度是固定的,所以每个子网能分配的接口个数是固定长度。
但是,很多公司不同部门需要的接口数量是不同的,每个部门都用定长的子网就会造成浪费。
比如某公司有3个部门,部门1需要100个IP地址,部门2需要50个IP地址,部门3需要25个IP地址。
如果分配一个C类地址给该公司(一共256个可用IP地址(先忽略全0和全1的特殊地址),足够整个公司使用),但是子网的划分却成了难题。因为部门1需要100个IP地址,所以应该划分一个有128个地址的子网给它,但是接下来只剩下1个有128个地址的子网,给部门2后,造成了很多浪费,而且没有其他子网给部门三了。
要解决上述问题,就需要变长子网掩码VLSM的概念。
简单概括,VLSM就是在子网的基础上继续划分子网。
比如,整个公司的子网掩码是/24,部门1的子网掩码是/25(/25有128个IP地址,足够部门1使用),也就是把公司的网络划分为2个子网,其中一个给部门1使用。
现在还剩余一个/25的子网,再在这个子网的基础上划分2个更小的子网/26,部门2使用其中一个/26的子网(/26可以分配64个IP地址,足够部门2使用)。
之后,你甚至可以把剩余一个/26的子网再划分为2个/27的子网,其中一个给部门3使用(/27的子网有32个地址,足够部门3使用)。
这样,还剩下一个/27的子网,可以留给之后扩展的新部门使用。
假设整个公司的C类地址范围是:193.20.20.0 ~ 193.20.20.255
那么部门1的子网地址范围是: 193.20.20.0 ~ 193.20.20.127
部门2的子网地址范围是: 193.20.20.128 ~ 193.20.20.191
部门3的子网地址范围是: 193.20.20.192 ~ 193.20.20.223
无分类编址CIDR
CIDR诞生的原因
CIDR的诞生是因为分类子网划分的2个局限性:
1.B类地址在1992年已经分配了近一半,预计很快将分配完毕。
2.互联网主干网上的路由表的项目数急剧增长(应该是C类和B类太多了)。
这2个问题都是因为分类编址的粒度过低(就A、B、C三类)导致的。
所以,IETF推出了无分类编址CIDR来解决这2个问题。
其实还有第三个问题:
3.互联网主机的高速增长,IPv4迟早会被消耗殆尽。
但这个问题CIDR也解决不了(毕竟最多只有 2 32 2^{32} 232位,再怎么优化分配,也不可能变出更多)。
这个问题是通过IPv6协议来解决的。
CIDR的定义
CIDR(Classless Inter_Domain Routing,CIDR的读音是"sider")的正式学名是无分类域间路由选择:它是在变长子网掩码VLSM的基础上,完全去除了分类和划分子网的概念,让分配的地址空间的粒度更细,可以完全根据实际的需要,分配最贴近大小的地址空间给相应的公司和组织。
CIDR把32位的IP地址划分为前后2个部分,前面部分称为“网络前缀”(network-prefix)(简称前缀),后面部分则叫后缀,用来表示主机。
其实和分类寻址的网络号和主机号的概念差不多,但是网络前缀的大小是不固定的,完全可以根据需要决定。
前缀的长度是通过CIDR掩码决定的,CIDR掩码的作用和子网寻址的子网掩码差不多,也是一串1和一串0组成。CIDR推出了一种“斜线记法“,称为CIDR记法(其实我前面在子网掩码中,已经在使用斜线记法了,但这个记法刚开始诞生应该是在CIDR产生时)。
斜线记法就是在IP地址后面加上“/",然后在/后写上网络前缀所占的位数(虽然CIDR已经去掉了子网的概念,但是很多厂商还是把CIDR掩码称为子网掩码,沿用了以前的叫法)。
同一个网络中,它们的网络前缀的长度和值都是一样的,主机部分(也就是后缀)是连续的IP地址,这些地址就组成了一个CIDR地址块。
和子网寻址差不多,只要知道任意一个带CIDR掩码的地址,就可以计算出整个地址块的起始地址,最后地址,以及地址块的地址个数。
可以参考子网掩码的计算公式(按位与,反码按位或,反码+1)。
我们一般用起始地址+CIDR掩码来标记一个地址块。
比如:128.20.64.0/20
CIDR的聚合
CIDR是标准的树结构,地址块实际是层层细分的,每一层都可以分配到合适的地址块个数。
因特网名称和编号分配组织(ICANN)先将很大的CIDR地址块分配给国家ISP,国家ISP再将已给与的大块地址划分为较小的地址块,分配给区域级的ISP,区域级的ISP再将得到的地址块分配成更小的地址块给本地ISP,本地ISP再将这些地址块进一步划分,分配给不同的组织机构,最后这些组织机构再根据实际情况,划分更小的块构成多个子网给不同的部门使用。这非常类似变长子网掩码VLSM的思路。
反过来,相邻的网络可以合并IP前缀,变成一个短前缀(称为一次聚合),合并后的网络称为一个超网 (supernet),这也是 CIDR 也称为超网的原因,相邻的超网再聚合,最后聚合成全球网络,使得全球网络形成一个多层次的树状结构。
比如有4个相邻网络:190.154.27.0/26 和 190.1 54.27.64/26 和 190.154.27.128/26 和 190.154.27.192/26
190.1 54.27.0/26 和 190.154.27.64/26 聚合成190.154.27.0/25
190.154.27.128/26 和 190.154.27.192/26 聚合成190.154.27.128/25
然后190.154.27.0/25 和 190.154.27.128/25 聚合成 190.154.27.0/24
这个思路不仅让每个组织都得到了合适大小的CIDR地址块,比如需要5000个IP地址的组织,以前申请B类地址觉得浪费,申请C类地址需要申请多个,现在用CIDR,只需要申请 2 13 2^{13} 213 = 8,192个地址个数的CIDR地址块。
而且,解决了路由器表项过长的问题。
只有到某个网络内部的路由器,才会看到更具体的CIDR地址块,在某个网络外部,是看不到更进一步细分的地址块,所有被细分的地址块被聚合成一个超网,外部网络要访问某个超网,只需要一个记录超网的表项就可以完成路由。
CIDR最长前缀匹配
这种按树状结构逐级分层的思路可能会让路由器某次路由时,出现多个匹配的结果。
这是很正常的情况,比如某个路由器连接一个网络,整个网络的CIDR地址块为:200.23.16.0/20,但是,整个网络被分成了8个子网,从200.23.16.0/23到200.23.30.0/23,如果子网一20.23.16/0/23想发送数据报给子网二20.23.18.0/23的某个目的地址200.23.18.100/23,当数据报传递到路由器时,会有2个表项都匹配:200.23.16.0/20和200.23.18.0/23,这时候按照最长前缀匹配,路由器会选择发送到200.23.18.0/23的子网中,而不是错误的发送到路由器指向的外部网络接口中。
最长前缀匹配很好理解,当有多个结果匹配时,选择网络前缀更长的匹配结果即可。
CIDR的三个限制条件
为了简化处理,因特网管理机构对CIDR强加了3个限制条件:
- 块中的地址必须是连续分配的。
- 一个块中的地址个数是2的整数次幂(1,2,4,8,……),分配50个这种是不行的。
- 块的起始地址必须能被块的个数整除。比如起始地址是205.16.37.32,最多分配32个地址个数的地址块,不能一下子分配64个地址的地址块,这样会很乱。
CIDR和子网寻址的对比
其实CIDR和子网的思路非常接近,只是完全去除了分类寻址的概念。
网络按照树的结构分成了很多层,越是在树的下层的网络就越小。
上层的网络要通信,只需要找到对应上层的较大的网络,再层层细分,找到最底层的特定网络。
子网寻址虽然也有变长子网掩码的概念,但是对于某个组织,还是必须从A、B和C类地址中选一个,这部分的粒度太粗了,导致网络地址的利用率还是很低,主干路由器还是需要记录大量的B类和C类地址的相关表项,所以开销还是很大。
其实可以这样理解,子网寻址在选择了某一类的地址之后,就完全和CIDR等同了。而CIDR是在一开始就按照子网寻址的思路层层下分。
子网寻址和分类寻址的很多概念其实都保留下来了,比如子网掩码编程了CIDR掩码。
很多特殊地址都是一样的规定。
比如:
255.255.255.255/32 是本地网络的广播地址
10.0.0.0/8 和 192.168.0.0/16 和 172.16.0.0/12 是内网地址,不用于公网中。
还有很多就不一一列举了。