【TCP/IP 笔记】IPv4-01 | 分类寻址 (Classful IP Addressing)、子网 (Subnet) 、无类寻址 (Classless IP Addressing)
参考
http://tcpipguide.com
文章目录
-
- IP 寻址的概念和问题
-
- IP 地址概述和基础
- IP 地址记法和大小
- IP 基本地址结构
- 三种主要的 IP 寻址方案
- 原始的分类寻址 (Classful IP Addressing)
-
- 概述
- 类别确定算法
- 特殊含义的 IP 地址
- 分类寻址的问题
- 子网 (Subnet)
-
- 子网掩码 (Subnet Masks)
- 变长子网掩码 (IP Variable Length Subnet Masking, VLSM)
- 无类寻址 (Classless IP Addressing)
-
- 概述
- 无类寻址与分类寻址相同点
IP 寻址的概念和问题
IP 地址概述和基础
-
IP 地址的功能:标识 (Identification) 和路由 (Routing)
- 网络接口标识 (Network Interface Identification):IP 地址给设备和网络之间的接口提供唯一的标识。这才能保证数据被传递到了正确的地方。
- 路由:当数据包的起源和终点不在同一个网络,数据包就必须通过中间系统间接 (Indirectly) 地传递,这个过程叫路由 (Routing)。
-
设备的 IP 地址数量
任何设备若要在网络层 (Network Layer) 传输数据就至少有一个 IP 地址,一个网络接口一个 IP 地址。一般的主机通常有一个 IP 地址,而路由器 (Routers) 则有多个 IP 地址。一些特殊的主机,如多宿 (Multihomed) 主机也会有多个 IP 地址。
多宿:一个主机拥有超过一个 IP 网络接口那么它就是多宿的,一个多宿设备可能有多个接口连着同一个网络也可能连着不同的网络。如果一个主机连着多个网络,那么它可以被配置成一个路由器 (Router)。
比网络层低层的设备如:中继器 (Repeaters)、桥 (Bridges) 和交换机 (Switches) 是不需要 IP 地址,因为它们是基于数据链路层 (Data Link Layer) 地址进行通信的。
-
IP 地址的网络特定性
当 IP 地址代表网络接口并用于路由时,这个 IP 地址是它所连接的网络特定的,如果设备移动到了一个新的网络,这个 IP 地址通常也需要改变,这个问题也催生了移动 IP (Mobile IP)。
IP 地址记法和大小
IP 地址仅是 32 位二进制数。一般分为四个字节,每个字节转换成十进制数,用点分开来表示。
| 二进制 | 11100011 | 01010010 | 10011101 | 10110001 |
|---|---|---|---|---|
| 十六进制 | E3 | 52 | 9D | B1 |
| 十进制 | 227 | 82 | 157 | 177 |
因为 IP 地址有 32-bit 长,所以总共有 2^32 即 4,294,967,296 个地址。
IP 基本地址结构
为了方便寻址,IP 地址被结构化成两部分:网络号 (Network ID) 和主机号 (Host ID)。
网络号:从 IP 地址最左端起的部分 bits,标识主机或其他网络接口所在的网络。也叫 Network prefix 或 prefix
主机号:除去网络号后剩余的 bits,标识网络上的主机。
将网络号包含进 IP 地址中,对寻址起到很大的帮助,因为可以通过比对数据包的目的地址的网络号和自身的网络号是否相同判断出目的地址在内网还是外网,从而快速确定路由。将 IP 地址分为网络号和主机号,还产生了一些有特殊含义的地址,如主机号全为 1 的广播地址。
网络号和主机号的分割点不是固定的,而是取决于各种因素的,并且可以在 32-bit 地址的任何地方,包括十进制八位字节的中间。

三种主要的 IP 寻址方案
- 分类寻址 (Classful Addressing):将 IP 地址分为 ABCDE 五类,三个主要类为 ABC 三类,区别在于网络号和主机号的长度,网络号和主机号的划分线在八位字节边界,如 C 类地址前 24 bits 为网络号,后 8 bits 为主机号。
- 子网分类寻址 (Subnetted Classful Addressing):在子网寻址系统中,通过从主机号中拿取前端部分 bits 作为子网号,用于识别子网,这将原本的两层划分系统(网络号/主机号)被改为三层划分系统(网络号/子网号/主机号)。
- 无类寻址 (Classless Addressing):将原始的分类寻址抛开,网络号和主机号可以在任意点划分,不需要像分类寻之中那样划分在八位字节边界。这种方案更加灵活有弹性。
原始的分类寻址 (Classful IP Addressing)
概述
在分类寻址中,IP 地址被分为 ABCDE 五类地址
| IP 地址类别 | 在 IP 地址中的占比 | 网络号数 | 主机号数 | 用于 |
|---|---|---|---|---|
| A 类地址 | 1/2 | 8 | 24 | 为需要上千万台主机连入网络的大型组织提供单播地址,最多提供 16,277,214 个地址 |
| B 类地址 | 1/4 | 16 | 16 | 为需要上千台主机连入网络的中型组织提供单播地址,最多提供 65,534 个地址 |
| C 类地址 | 1/8 | 24 | 8 | 为需要上百台主机连入网络的小型组织提供单播地址,最多提供 254 个地址 |
| D 类地址 | 1/16 | - | - | 多播地址 |
| E 类地址 | 1/16 | - | - | 为实验保留 |
其中 ABC 类占 7/8,用作单播地址。
尽管分类寻址对如今的网络来说缺点众多,以至于我们用无类寻址 (Classless IP Addressing) 代替了它,但要知道这是在十几年前开发出来的寻址系统,对于那时的网络环境,那时的计算机性能,分类寻址也有着许多的优点:
- 合理的灵活性:三种等级“粒度”的地址,分别对应大、中、小三种大小的组织,提供了足够的容量来处理当时对网络增长的预期。
- 易于路由:因为地址的类别信息包含在地址中,且只有五种类型,这使路由器可以很轻松的知道地址的哪部分为网络号,哪部分为地址号,而不需要如掩码的附加信息。
类别确定算法
TCP/IP 刚被创造的时候,计算机的性能比起现在要弱得多,路由器要快速地决定数据包的去处,就必须快速的确定地址的类别并获得目的地址的网络号,当时大家也想象不到网络发展到今天会如此巨大,那时只需要一套简单高效的寻址机制即可,所以分类寻址就这么被发明并使用相当一段时间,也随之诞生了类别确认算法。
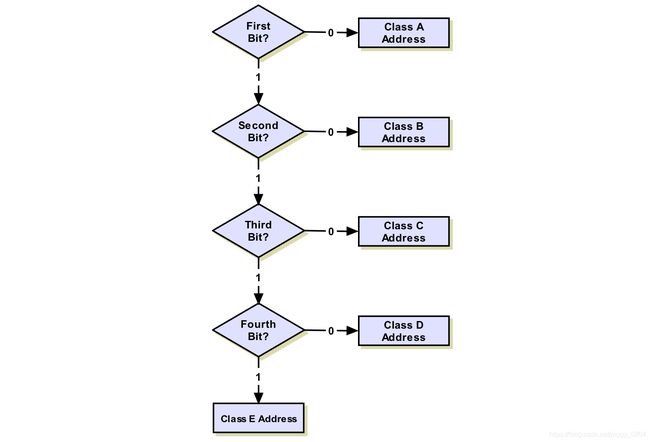
算法流程
- 如果地址第一位为 0,则为 A 类地址;如果为 1 则进行下一步。(这也是为什么 A 类地址占 IP 地址的一半)
- 如果地址第二位为 0,则为 B 类地址;如果为 1 则进行下一步。
- 如果地址第三位为 0,则为 C 类地址;如果为 1 则进行下一步。
- 如果地址第四位为 0,则为 D 类地址;如果为 1 则为 E 类地址。
特殊含义的 IP 地址
| 网络号 | 主机号 | A 类地址例子 | B 类地址例子 | C 类地址例子 | 特殊含义 |
|---|---|---|---|---|---|
| 网络号 | 全为 0 | 77.0.0.0 | 154.3.0.0 | 227.82.157.0 | 指整个网络。 |
| 全为 0 | 主机号 | 0.91.215.5 | 0.0.99.6 | 0.0.0.160 | 指当前网络或默认网络中的一个主机。 |
| 全为 0 | 全为 0 | 0.0.0.0 | 指自身,当设备不知道自己的 IP 地址时使用,常用于设备用主机配置协议(如 DHCP)确定自身地址。 | ||
| 网络号 | 全为 1 | 77.255.255.255 | 154.3.255.255 | 227.82.157.255 | 指某网络中的所有主机,即本地广播地址。 |
| 全为 1 | 全为 1 | 255.255.255.255 | 指网络中的所有主机,即全局广播地址,广播给所有直接连接的网络中的主机。 | ||
保留地址、环回地址和私人地址:
| 分类地址 | 无类地址 | 描述 |
|---|---|---|
| A 类 0.x.x.x | 0/8 | 保留 |
| A 类 10.x.x.x | 10/8 | A 类私人地址 |
| A 类 127.x.x.x | 127/8 | 环回地址 |
| B 类 128.0.x.x | 128.0/16 | 保留 |
| B 类 169.254.x.x | 169.254/16 | B 类私人地址,用于自动私人地址分配,详见 DHCP |
| B 类 172.16.x.x ~ 172.31.x.x | 172.16/12 | B 类私人地址 |
| B 类 191.255.x.x | 191.255/16 | 保留 |
| C 类 192.0.0.x | 192.0.0/24 | 保留 |
| C 类 192.168.0.x ~ 192.168.255.x | 192.168/16 | C 类私人地址 |
| C 类 223.255.255.x | 223.255.255/24 | 保留 |
多播地址:
| 起始地址 | 终止地址 | 描述 | ||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 224.0.0.0 | 224.0.0.255 | 保留众所周知的多播地址。
|
||||||||||||||||||||||
| 224.0.1.0 | 238.255.255.255 | 全球范围的多播地址 | ||||||||||||||||||||||
| 239.0.0.0 | 239.255.255.255 | 管理权限范围(本地)的多播地址 |
分类寻址的问题
分类寻址的主要问题是能供使用的单播地址只有 ABC 三类,而且三类网络地址块的地址数跨度太大。假如你的公司有 5000 台设备需要接入网络,C 类网络地址数最大为 254,B 类网络地址数最大为 65,534 。此时有两种选择,选择一个 B 类地址,可是这将浪费全球 60,534 个地址,而且需要不必要的开销;另一个选择是选择 20 个 C 类地址,这看似没有什么问题,但实际上,这导致在外部网络路由器的路由表上增加了不必要的路由信息,理想状况下,一个组织应只占据一个或少许几个路由表项。如果这样规模的公司有很多,且都选择了第一种解决方案,那么全球将会有一大部分的 IP 地址是被浪费的;而如果都选择了第二种方案,则路由表会变得非常的大,路由负担将会大大加重,网络速度也将大幅下降。
总结下来,分类寻址存在三大问题:
- 缺少内部地址灵活性:一个大的组织分配了一个大的地址块后,因为分类寻址的地址为两层结构:网络号+主机号,所以组织内部的地址是没有结构的,无法匹配内部实际的物理网络结构。
- 地址空间的低效使用:如上如果选用 B 类地址则造成 90% 地址的浪费。
- 路由表的爆炸增长:如上如果选用 20 个 C 类地址,则要为这个公司添加 20 个路由表表项,这使得路由表爆炸增长,路由器决定路由的速度减慢,将拖累网络的传输速度。
于是人们用子网寻址解决了第一个问题,用无类寻址替代了分类寻址从而解决了第二第三个问题。
子网 (Subnet)
子网简单的来说就是在原有的分类寻址上加的一个分层等级,使得 IP 地址变成了三层结构:一个网络含有若干个子网,一个子网含有若干台主机。这一改变带来的优势:
- 网络内部更贴近物理网络结构:主机可以组成子网来反映显示中的物理网络结构。
- 灵活:子网数和每个子网的主机数都是可以自定义的。
- 对公共网络不可见:子网仅在组织内部进行划分,仅内部可见,对于外部网络,这只是一个网络,内部进行的任何更改外部都是不可得知的。
- 路由表表项不会剧增:因为子网结构仅存在组织内部,对外只需要一个或少许几个路由表项,只要内网的路由器知道到各子网的路由即可。
噢对了,子网号是通过从主机号划分一部分得来的,将主机号前面的一部分划作子网号,剩余的部分作为主机号。
子网掩码 (Subnet Masks)
既然子网的数量和每个子网的主机数都是可以自定义的,也就是说子网号和主机号的长度是可以自定义的,那么问题又来了,要怎么让路由器知道那部分是子网号,那部分是主机号呢?我们需要额外的信息来告诉路由器,采取的方法是利用一个和 IP 地址等长 (32-bit) 的掩码 (Masks)。与网络号和子网号对应的位置为 1,主机号对应的位置为 0。这样的话,只要将子网掩码和 IP 地址进行 AND 操作就可以清除主机号,迅速获得网络号和子网号用于确定路由。为了方便表示,我们一般在地址后面加 “/n” 来表示网络号和子网号的长度,n 为网络号和子网号的长度。例:IP 地址 119.29.192.194 子网掩码为 255.255.248.0 那么我们可以表示为 119.29.192.194/21。
划分子网的一些基础:
- 每增加一位子网号,子网的数量翻倍,每个子网的主机数大概减一半(因为每个子网要减两个特殊地址,主机号全为 1 和全为 0)。
- 每减少一位子网号则反之。
例如我们有一个 B 类地址,B 类地址有 16 位主机号,如果我们需要搭建 10 个子网,因为 23=8,24=16,所以我们需要从 16 位主机号中取 4 位作为子网号,那么我们还剩下 12 位主机号,也就是说每个子网最多有 2^12-2=4094 台主机。
变长子网掩码 (IP Variable Length Subnet Masking, VLSM)
hmmm,又出问题了,从上面的例子相信大家也会发现,子网号的长度是固定的,也就是说一个网络被等分成若干分,而现实中的应用,不会这么凑巧。和上面一样,如果我们需要 10 个子网,但需要其中一个很大,需要有 30,000 台主机,剩下的 9 个子网都只需要 1000 台主机,那么就出问题了,如果要 10 个子网,那么每个子网就只能最多有 4094 台主机。这个方案可以满足 9 个小的子网,但却因为需要一个大的子网而无法投入使用,那问题就大了,网管可能需要为了那一个大的子网再去申请一个 B 类地址,这样就把剩下的地址给浪费了。我们需要一个可以将网络根据需求划分成不同大小子网的机制。
顺应大家的需求,VLSM 就诞生了。简单的说 VLSM 就是允许将子网内部再划分子网的规则。
例如有一个 B 类地址 154.71.0.0,要满足上面所说的要求:
取一位子网号分成两个子网,分别为:154.71.0.0 和 154.71.128.0,每个子网最多可以有 32,766 台主机。
取子网 154.71.128.0,再取四位主机号作为子网号,将这个子网再划分成 16 个子网,每个子网最多可以有 2046 台主机。
| 154.71.0.0/16 | |||||||||||||||||||||||||||||||||||||||||||||||||||
|
这样网管就可以尽可能地匹配需求了。
无类寻址 (Classless IP Addressing)
概述
子网寻址有着两个主要的优势:匹配现实物理网络结构和对外部网络不可见。但这里的子网寻址是在分类寻址的基础上的。所以还是没有解决分类寻址的一些问题。分类寻址的主要问题是地址块的“粒度”过低,只有 ABC 三类地址,且三类地址的大小跨度很大,难以匹配现实需求,从而造成地址空间的低效利用或路由表表项的增加。
为了解决分类寻址的主要问题,诞生了无类寻址 (Classless Inter-Domain Routing, CIDR)。
CIDR 的理论是不使用类对 IP 地址进行划分地址块,而是将全球网络进行子网划分,匹配各个组织的需求。各个网络聚合成一个超网 (supernet),这也是 CIDR 也称为超网的原因,超网再聚合,最后聚合成全球网络,使得全球网络形成一个多层次的结构,像一棵树。
CIDR 的优势:
- 有效的利用地址空间:因为 CIDR 消除了地址类,所以可以分配任何二进制倍数大小的地址块,所以像之前说的需要 5000 台设备连入网络的公司可以分配一个 8,190 大小的地址块而不是一个 65,534 大小的地址块,即每个组织都可以分配一个匹配的网络地址块,大大减少了地址空间的浪费。
- 消除不同类地址的不平衡:因为 CIDR 消除了地址类,所以不存在某一类地址广泛使用而其他的地址不被使用的情况。
- 高效的路由表项:因为 CIDR 中,网络是一个多层次的结构,每个超网的内部网络结构对外是不可见的,也就是说可以用一个路由表项去代替超网内的所有网络的路由表项,大大减少了路由表的大小,提高了路由的速度,就像树的查找速度比线性表更快。
分类寻址之所以存在是因为对于当时的网络环境和计算机性能有着一个重要的优势:简单。路由器可以通过前四个 bits 快速的判断出地址的类别,从而知道网络号和主机号。而无类寻址的缺点便是复杂,路由器不能通过前几个 bits 来确定网络号和主机号,这要求路由器的配置要小心和正确。
你肯定觉得 CIDR 和 LVSM 没什么区别,是的,我也觉得没什么区别。
无类寻址与分类寻址相同点
下面是一些从分类寻址机制中保留下来的东西:
- 私人地址块:分类寻址中的私人地址块依旧保留,这些地址在互联网中不被直接路由,但可以结合 NAT (Network Address Translation) 使得主机不用公共地址去连接网络。
- 特殊含义地址:特殊含义地址和分类寻址中一样,所以我们依旧每个网络要减去两个特殊地址。
- 环回地址:环回地址仍被保留,在 CIDR 中记作 127.0.0.0/8。