(一)Normal Predictor、Baseline Only以及经典Apriori
推荐库surprise的安装

1、Normal Predictor
NormalPredictor是一种假定用户对物品的评分数据是服从正态分布的。从而基于正态分布的期望u和标准差随机的给出当前用户对其他物品的评分。

import os
from surprise import Dataset,Reader
from surprise import NormalPredictor
from surprise.model_selection import train_test_split
from surprise import accuracy
'''
一、Normal Predictor推荐算法
NormalPredictor是一种假定用户对物品的评分数据是服从正态分布的。从而基于正态分布的期望u和标准差随机的给出当前用户对其他物品的评分。
'''
# 方式一:加载指定的数据集
# Accepted values are 'ml-100k', 'ml-1m', and 'jester'. Default is 'ml-100k'.
data = Dataset.load_builtin('ml-100k')
data
# 方式二、加载指定的数据集
# 直接读取文件
file_path = os.path.expanduser('./data/ml-1m/ratings.dat')
reader = Reader(line_format='user item rating timestamp', sep='::')
# 加载数据
data = Dataset.load_from_file(file_path, reader=reader)
# 2、对数据进行划分
# trainset = data.build_full_trainset()
trainset, testset = train_test_split(data, test_size=0.25)
# 3、模型对象构建
algo = NormalPredictor()
# 4、训练
'NormalPredictor核心思想是认为用户对于物品的评价是服从高斯分布的一个随机过程'
'进行模型训练的时候,必须对训练数据进行构建(其实,就是将Movieline格式数据转换为稀疏矩阵)'
'在这个转换的过程中,会做一个id的转换,就是将外部的id转换为内部的id'
algo.fit(trainset)
# 5、预测
y_ = algo.predict('196', '242', 3.0)
print(y_)
print("预测评分:{}".format(y_.est))

# 6、评估
predictions = algo.test(testset)
print(predictions[:1])
accuracy.rmse(predictions)
accuracy.mse(predictions)
accuracy.fcp(predictions)

二、Baseline Only
Baseline Only是一种基于统计数据的基线评分预测算法,原理是认为每个用户对于每个商品的评分是有三部分构成的,即所有评分的均值u、当前用户的评分基线b1,当前物品的评分基线b2
假定现在需要使用Baseline Only算法给出gerry对于《缩小人生》这部电影的评分;比如我们现在计算出所有电影的评分均值为3.7分,此外《缩小人生》这部电影由于属于喜剧科幻类型的电影,所以它的平均评分比其它电影评分低0.3分,在另一方面,gerry用户是一个要求比较宽松的用户,通常会比别人多给0.8个评分。因此我们最终就可以计算出gerry用户对于《缩小人生》这部电影的评分为:3.7-0.3+0.8=4.2分
Baseline Only:算法的思想是认为用户u对于物品的评分,是相对于平均评分y的一个偏移,而这个偏移体现在两个方面:
1.用户的差异性
2.物品的差异性
from surprise import BaselineOnly
_bsl_options = {
'method':'sgd',# 计算方法,默认als
'n_epochs':10, # 迭代次数
'reg':0.02, # 正则化系数
'learning_rate':0.01 # 学习率,一般选一个比较小的值
}
algo = BaselineOnly(bsl_options=_bsl_options)
# 训练
algo.fit(trainset)
# 预测
y_ = algo.predict('196', '242', 3.0)
print(y_)
print("预测评分:{}".format(y_.est))

三、Apriori算法



1、手动实现整体流程
# 加载数据集
def load_data_set():
data = [
[1,3,4],
[2,3,5],
[1,2,3,5],
[2,5]
]
return data
# 得到频繁一项集
def get_c1(data_set):
c1 = []
for transaction in data_set:
for item in transaction:
if not [item] in c1:
c1.append([item])
c1.sort()
return list(map(frozenset,c1))
# 扫描一项集、二项集。。。。。。
def scan_data(data_set, ck, min_support):
ss_cnt = {} # 一项集出现的次数,......
for tid in data_set:
for can in ck:
if can.issubset(tid):
if not can in ss_cnt:
ss_cnt[can] = 1
else:
ss_cnt[can] += 1
# 总的记录数
num_items = float(len(data_set))
ret_list = []
support_data = {}
# 求每一项的支持度
for key in ss_cnt:
support = ss_cnt[key] / num_items
if support >= min_support:
ret_list.insert(0, key)
support_data[key] = support
return ret_list,support_data
# 拼接二项集、三项集。。。。。。
def apriori_gen(lk, k):
ret_list = []
len_lk = len(lk)
for i in range(len_lk):
for j in range(i+1, len_lk):
l1 = list(lk[i])[:k-2]
l2 = list(lk[j])[:k-2]
if l1 == l2:
ret_list.append(lk[i]|lk[j])
return ret_list
def apriori(data_set, min_support=0.5):
c1 = get_c1(data_set)
L1,support_data = scan_data(data_set, c1, min_support)
L = [L1]
k = 2
while(len(L[k - 2]) > 0 ):
ck = apriori_gen(L[k-2], k)
Lk,sup_data = scan_data(data_set, ck, min_support)
support_data.update(sup_data)
L.append(Lk)
k += 1
return L,support_data
def cal_conf(f_set, H, support_data, rule_list, min_confidence):
prunedh = []
for conseq in H:
conf = support_data[f_set] / support_data[f_set - conseq]
if conf >= min_confidence:
print(f_set-conseq,'==>',conseq,' conf:',conf)
rule_list.append(
(f_set-conseq,conseq,conf)
)
prunedh.append(conseq)
return prunedh
def rules_from_conseq(f_set, H, support_data, rule_list, min_confidence):
m = len(H[0])
while(len(f_set) > m):
H = cal_conf(f_set, H, support_data, rule_list, min_confidence)
if (len(H) > 1 ):
apriori_gen(H, m + 1)
m += 1
else:
break
def generate_rules(L, support_data, min_confidence=0.6):
rule_list = []
for i in range(1, len(L)):
for f_set in L[i]: #[[2,3],[2,5]...]
H1 = [frozenset([item]) for item in f_set]
rules_from_conseq(f_set, H1, support_data, rule_list, min_confidence)
return rule_list
if __name__ == '__main__':
data_set = load_data_set()
L, support_data = apriori(data_set, min_support=0.5)
i = 0
for f in L:
print("项数:{},结果:{}".format((i + 1), f))
i += 1
rules = generate_rules(L, support_data,min_confidence=0.5)
print(rules)

2、电影分类的关联分析
# pip install mlxtend
import pandas as pd
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
# 1、加载电影数据
# 数据下载地址 https://files.grouplens.org/datasets/movielens/
movies = pd.read_csv('./data/ml-1m/movies.dat',sep='::',encoding="unicode_escape",header=None, names=['movieId','title','genres'])
movies.head()

# 2、one-hot编码
# 将genres进行one-hot编码(离散特征有多少取值,就用多少维来表示这个特征)
movies_hot_encoded = movies.drop('genres',1).join(movies.genres.str.get_dummies(sep='|'))
movies_hot_encoded.head()

movies_hot_encoded.set_index(['movieId','title'], inplace=True)
print(movies_hot_encoded.shape)
movies_hot_encoded.head()

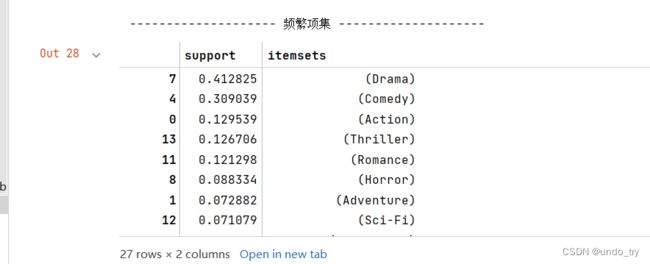
# 3、挖掘频繁项集,最小支持度为0.02
itemsets = apriori(movies_hot_encoded,use_colnames=True, min_support=0.02)
# 按照支持度从大到小
itemsets = itemsets.sort_values(by="support" , ascending=False)
print('-'*20, '频繁项集', '-'*20)
itemsets
rule_movies = association_rules(itemsets, metric='lift')
rule_movies

rule_movies[(rule_movies.lift > 4)].sort_values(by=['lift'], ascending=False)
