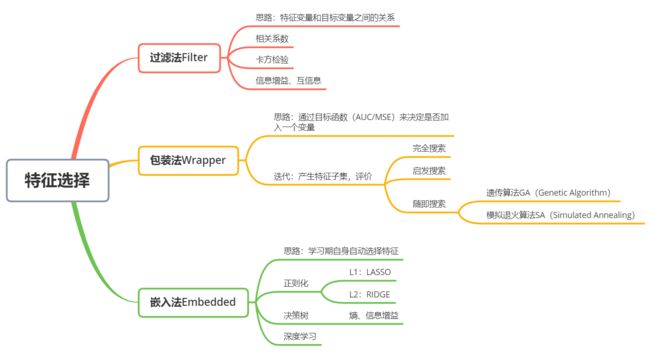
特征选择方法
特征选择的目标
- 特征是否发散:如果特征不发散,基本没有差异,对样本的区分没有作用
- 特征与目标的相关性:与目标相关性高的特征应当优先选择
特征选择的方法有过滤法、包装法、嵌入法
- 过滤法:按照发散性或者相关性对各个特征进行评分,通过设定阈值或者待选择阈值的个数来选择特征
- 包装法:根据目标函数(通常是预测效果评分)每次选择若干特征,或者排除若干特征
- 嵌入法:使用机器学习的某些算法或模型进行训练,得到各个特征的权值系数,并根据系数从达到小选择特征
特征选择在python中的具体实现
| 类 | 所属方法 | 具体方法 |
|---|---|---|
| varianceThreshold | Filter | 方差选择法 |
| SelectKBest | Filter | 将可选相关系数、卡方检验或最大信息系数作为得分计算的方法 |
| RFE | Wrapper | 递归消除特征法 |
| SelectFromModel | Embedded | 基于模型的特征选择法 |
过滤法:相关系数、卡方检验、信息增益、互信息
包装法:完全搜索、启发搜索、随机搜索(遗传算法、模拟退火算法)
嵌入法:决策树
- VarianceThreshold
方差选择法,计算各个特征的方差,然后根据阈值选择方差大于阈值的特征。
from sklearn.feature_selection import VarianceThreshold
from sklearn.datasets import load_iris
iris = load_iris()
VarianceThreshold(threshold=3).fit_transform(iris.data)
- SelectKBest
(1)相关系数法
计算各个特征对目标值的相关系数及相关系数的P值,然后根据阈值筛选特征。
import numpy as np
from sklearn.datasets import load_iris
iris = load_iris()
from array import array
from sklearn.feature_selection import SelectKBest
from scipy.stats import pearsonr
SelectKBest(
lambda X,Y: np.array(list(map(lambda x: pearsonr(x,Y), X.T))).T[0],k=2).fit_transform(iris.data, iris.target)
(2)卡方检验
经典的卡方检验是检验定性自变量与定性因变量的相关性。假定自变量有N种取值,因变量有M种取值,考虑自变量等于i且因变量等于j的样本频数的观察值与期望之间的差距,构建统计量:
x 2 = ∑ ( A − E ) 2 / E x^2=∑(A-E)^2/E x2=∑(A−E)2/E
from sklearn.datasets import load_iris
iris = load_iris()
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
SelectKBest(chi2, k=2).fit_transform(iris.data, iris.target)
(3)最大信息系数法
经典的互信息是评价定性自变量与定性因变量相关性的方法,互信息计算公式如下:
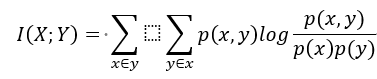
import numpy as np
from sklearn.feature_selection import SelectKBest
from minepy import MINE
def mic(x, y):
m = MINE()
m.compute_score(x, y)
retrun (m.mic(), 0.5)
SelectKBest(lambda X,Y: np.array(list(map(lambda x: pearsonr(x,Y), X.T))).T[0],k=2).fit_transform(iris.data, iris.target)
- 递归消除特征法RFE
递归特征消除法使用一个基模型进行多轮训练,每轮训练后,消除若干权值系数的特征,再基于新的特征集进行下一轮训练。
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
RFE(estimator=LogisticRegression(multi_class='auto',solver='lbfgs',max_iter=500),n_features_to_select=2).fit_transform(iris.data,iris.target)
- SelectFromModel
采用基于模型的特征选择法,有基于惩罚项的特征选择法和基于树模型的特征选择法
(1)基于惩罚项的特征选择法
使用带惩罚项的基模型,除了能筛选特征,也能进行降维
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import LogisticRegression
SelectFromModel(LogisticRegression(penalty='l2',C=0.1,solver='lbfgs',multi_class='auto')).fit_transform(iris.data,iris.target)
(2)基于树模型的特征选择法
在树模型中,GBDT梯度提升迭代决策树可以作为基模型进行特征选择
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import GradientBoostingClassifier
# SelectFromModel(GradientBoostingClassifier()).fit_transform(iris.data, iris.target)
SelectFromModel(GradientBoostingClassifier()).fit_transform(gas_data,gas_target)