通俗理解卷积神经网络----深度学习小白入门随笔
原文地址:https://blog.csdn.net/kanghe2000/article/details/70940491(原文有小瑕疵,池化过程是没有参数加权,加偏置的以及激活函数的概念的,本文有作修改)
前言
卷积神经网络(convolutional neural network,CNN),一种专门用于处理具有类似网络结构数据的神经网络,部分层使用卷积运算替代一般矩阵乘法运算的神经网络。
下图简单地表示神经元:

卷积神经网络沿用了普通的神经元网络即多层感知器的结构,是一个前馈网络。以应用于图像领域的CNN为例,大体结构如图:
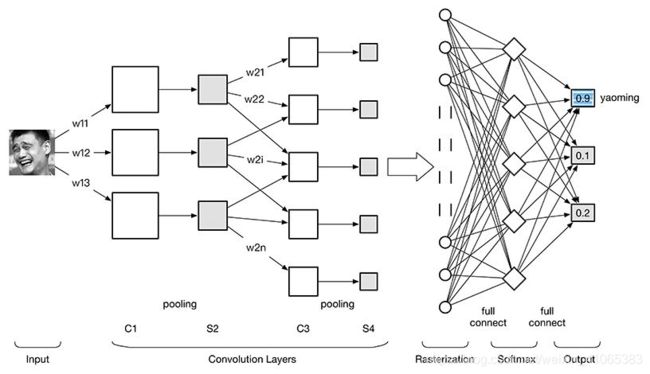
根据上图 卷积神经网络 ConvNet 可以分为下面几个层:
(1)图像输入Image Input:为了减小后续BP算法处理的复杂度,一般建议使用灰度图像。也可以使用RGB彩色图像,此时输入图像原始图像的RGB三通道。对于输入的图像像素分量为 [0, 255],为了计算方便一般需要归一化(图像的预处理),如果使用sigmoid激活函数,则归一化到[0, 1],如果使用tanh激活函数,则归一化到[-1, 1];
(2)卷积层(Convolution Layer),有时候也被称为过滤器(filter),核(kernel),被照过的区域被称为感受野(receptive field):将上一层的输出图像与本层卷积核(权重参数w)加权值,加偏置;过滤器同样也是一个数组(其中的数字被称作权重或参数),重点在于过滤器的深度必须与输入内容的深度相同,当筛选值在图像上滑动(卷积运算)时,过滤器中的值会与图像中的原始像素值相乘(又称为计算点积)。这些乘积被加在一起,向右往下滑动窗口,在输入内容上的每一位置重复该过程,滑过所有位置后将得到一个张量;
(3)池化层(Pooling Layers):使用某一位置的相邻矩阵区域输出的总体统计特征来替代网络在该位置的输出,征映射具有位移不变性;
(4)光栅化(Rasterization),全连接层(Fully Connected Layers):为了与传统的多层感知器MLP全连接,把上一层的所有Feature Map的每个像素依次展开,排成一列;
(5)多层感知器(MLP),输出层(Output Layers):最后一层为分类器,一般使用Softmax,如果是二分类,当然也可以使用线性回归Logistic Regression,SVM,RBM。
1.卷积
卷积层是卷积核在上一级输入层上通过逐一滑动窗口计算而得,卷积核中的每一个参数都相当于传统神经网络中的权值参数,与对应的局部像素相连接,将卷积核的各个参数与对应的局部像素值相乘之和,(通常还要再加上一个偏置参数),得到卷积层上的结果:

2.CNN的三大重要思想
2.1 局部感知(local field),稀疏交互(sparse interactions)
普通的多层感知器中,隐层节点会全连接到一个图像的每个像素点上,而在卷积神经网络中,每个隐层节点只连接到图像某个足够小局部的像素点上,使核的大小远小于输入的大小,从而大大减少需要训练的权值参数。
如下图所示,左边是每个像素的全连接,右边是每行隔两个像素作为局部连接,因此在数量上,少了很多权值参数数量

下面我们来详细看一下到底局部感知如何使全连接变成局部连接,按照人工神经网络的方法,把输入图像的像素一字排开之后,每一个像素值就是一个神经元输入,需要对隐层或者输出层做全连接,如上图左侧所示。卷积神经网络引入卷积概念后,卷积核通过原图像,然后卷积核对原图像上符合卷积核大小的像素进行加权求和,每一次只是对符合卷积核的图像像素做卷积,这就是局部感知的概念,使全连接变成局部连接。
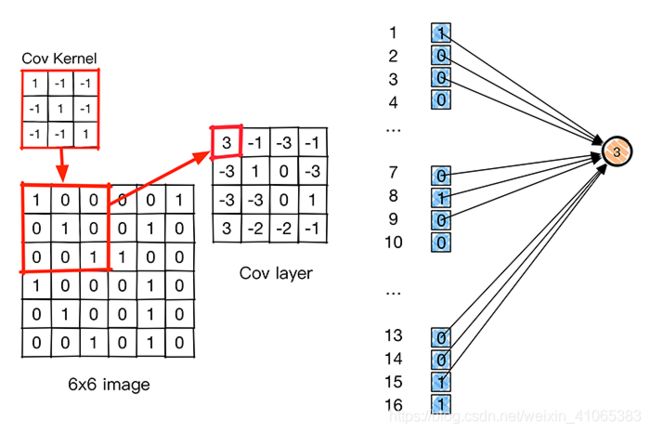
2.2 参数共享(parameter sharing)
不同的图像或者同一张图像共用一个卷积核,减少重复的卷积核。同一张图像当中可能会出现相同的特征,共享卷积核能够进一步减少权值参数。
如下图所示,为了找到鸟嘴,一个激活函数A需要检测图像左侧有没有鸟嘴,另外一个激活函数B需要检测另外一张图像中间有没有类似的鸟嘴。其实,鸟嘴都可能具有同样的特征,只需要一个激活函数C就可以了,这个时候,就可以共享同样的权值参数(也就是卷积核)。

如果使用了权值共享(共同使用一个卷积核),那么将可以大大减少卷积核的数量,加快运算速度。

举个栗子,在局部连接中隐藏层的每一个神经元连接的是一个 10∗10 的局部图像,因此有 10∗10 个权值参数,将这 10∗10 个权值参数共享给剩下的神经元,也就是说隐藏层中 106 个神经元的权值参数相同,那么此时不管隐藏层神经元的数目是多少,需要训练的参数就是这 10∗10 个权值参数(也就是卷积核(也称滤波器)的大小。
尽管只有这么少的参数,依旧有出色的性能。但是,这样仅提取了图像的一种特征,如果要多提取出一些特征,需要增加多个卷积核,不同的卷积核能够得到图像的不同映射下的特征,称之为 Feature Map。如果有100个卷积核,最终的权值参数也仅为 100∗100=104 个而已。另外,偏置参数b也是共享的,同一种滤波器共享一个。
2.3 池化(pooling)
在卷积神经网络中,没有必要一定就要对原图像做处理,而是可以使用某种“压缩”方法,这就是池化,也就是每次将原图像卷积后,都通过一个下采样的过程,来减小图像的规模。
pooling的优点:
1.这些统计特征能够有更低的维度,减少计算量。
2.不容易过拟合,当参数过多的时候很容易造成过度拟合。
3.缩小图像的规模,提升计算速度。
如下图所示,原图是一张500∗500 的图像,经过subsampling之后哦,变成了一张 250∗250 的图像。这样操作的好处非常明显,虽然经过权值共享和局部连接后的图像权值参数已经大大减少,但是对于计算量来说,还是非常巨大,需要消费很大的计算时间,于是为了进一步减少计算量,于是加入了subsampling这个概念,不仅仅使图像像素减少了, 同时也减少计算时间。

Pooling算法的种类
最大池化(Max Pooling):取指定矩形区域内点的最大值。这是最常用的池化方法。
均值池化(Mean Pooling)。取指定矩形区域内点的均值。
可训练池化:训练函数 f ,取指定矩形区域内点为输入,出入1个点。
由于特征图的变长不一定是2的倍数,所以在边缘处理上也有两种方案:
保留边缘(padding):将特征图的变长用0填充为2的倍数,然后再池化。
忽略边缘:将多出来的边缘直接省去。
3.CNN 物理意义
为了从原始图像得到C层,需要把原始图像中的每一个像素值作为神经网络当中一个神经元,那么这里把原始输入图像一字排开,作为输入层。通过BP反向传播算法计算好的权值参数(卷积核)去计算C层对应的的每一个像素的值。
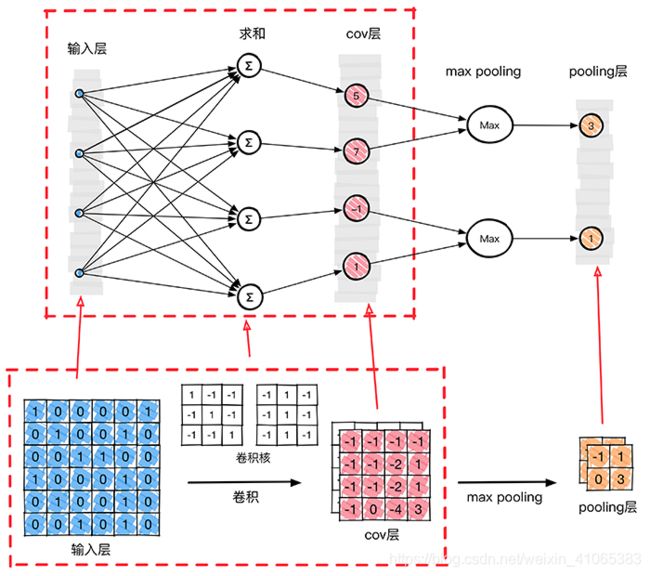
从上图我们得到了C层,也就是提取特征后得到特征层,需要对特征层处理减少特征数量,进一步抽取高层特性,因此需要进步特征映射层(S层)。下图的pooling层(S层)使用了max pooling算法,pooling核为2x2,没有重叠部分,取每4个像素中最大的一个像素值作为新的像素值。

那么在这个模型当中,我们已经确定了激活函数φ(∗),输入x1,x2,…,xn 是确定的,未知量就剩下神经元k的突触权值k1,wk2,…,wkn ,bk 偏置。**反向传播算法(back propagation)**就是为了求整个神经网络当中的两种未知变量:权值 w 和偏置 b。在上图这个模型当中,卷积核大小为3∗3,也就是有9个权值w组成,因此反向传播的时候就是要求这两个卷积核的权值w,使用大量的图片作为输入就是为了使用BP算法求得卷积核的值,当求得卷积核的值之后,分类的时候输入一张未知的图片,然后通过整个网络,直接就可以得到最终的分类结果,因为权值和偏置已经通过训练求出来了,整个网络没有未知量。
4.卷积,池化的输入输出计算方法
![]()
卷积层向上取整,池化层向下取整
5.卷积神经网络图解

回顾一下开篇的CNN网络结构,输入图像通过和三个可训练的滤波器和可加偏置进行卷积。
1.滤波过程如图,卷积后在C1层进行加权求和,加偏置产生三个特征映射图;
2.然后特征映射图中每组的矩形范围内四个像素再进行下采样,通过一个激活函数得到三个S2层的特征映射图。
3.这些映射图再进过滤波得到C3层。这个层级结构再和S2一样产生S4,特征映射图中每组的像素再进行下采样,通过一个激活函数得到多个freture map(S4)的特征映射图。
4.最终,这些像素值被光栅化,并连接成一个向量输入到传统的神经网络进行分类判别,得到输出。
小结
卷积神经网络CNN的核心思想是:局部感知(local field),权值共享(Shared Weights)以及下采样(subsampling)这三种思想结合起来,获得了某种程度的位移、尺度、形变不变性,提高了运算速度和精度。
多层网络可以根据其输入引出高阶统计特性, 即使网络为局部连接,由于格外的突触连接和额外的神经交互作用,也可以使网络在不十分严格的意义下获得一个全局关系。这也就是CNN使用局部连接之后还获得很好的效果的原因。