机器学习中的模型选择和评估
机器学习中的模型选择和评估
- 1. 介绍
- 2. 模型拟合效果
-
- 2.1欠拟合与过拟合表现方式
- 2.2 避免欠拟合与过拟合的方法
- 3.实例分析
-
- 3.1鸢尾花数据集
- 3.2 对鸢尾花数据进行聚类
1. 介绍
在机器学习系统中,如何训练出更好的模型、如何判断模型的效果,以及模型是否过拟合,对模型的最终使用有重要的意义。
2. 模型拟合效果
在机器学习模型的训练过程中,可能会出现3种情况:模型欠拟合、模型正常拟合与模型过拟合。其中模型欠拟合与模型过拟合都是不好的情况。下面将从不同的角度介绍如何判断模型属于哪种拟合情况。
2.1欠拟合与过拟合表现方式
数据的3种拟合情况说明如下。
- 欠拟合:欠拟合是指不能很好地从训练数据中学到有用的数据模式,从而针对训练数据和待预测的数据,均不能获得很好的预测效果。如果使用的训练样本过少,较容易获得欠拟合的训练模型。
- 正常拟合:正常拟合是指训练得到的模型可以从训练集上学习,得到泛化能力强、预测误差小的模型,同时该模型还可以针对待测试的数据进行良好的预测,获得令人满意的预测效果。
- 过拟合:过拟合是指过于精确地匹配了特定数据集,导致获得的模型不能很好地拟合其他数据或预测未来的观察结果。模型如果过拟合,会导致模型的偏差很小,但是方差会很大。
下面分别介绍针对分类问题和回归问题,不同任务下的拟合效果获得的模型对数据训练后的表示形式。
针对二分类问题,可以使用分界面表示所获得的模型与训练数据的表现形式。
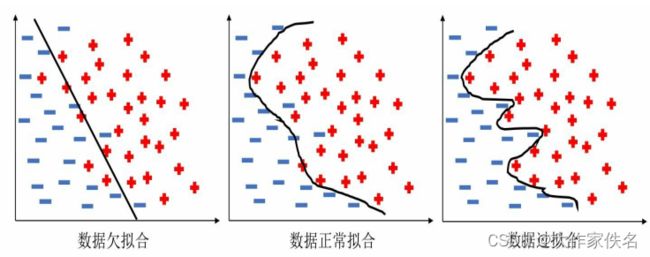
从上图欠拟合的数据模型较为简单,因此获得的预测误差也会较大,而过拟合的模型则正好相反,其分界面完美地将训练数据全部正确分类,获得的模型过于复杂,虽然训练数据能够百分百预测正确,但是当预测新的测试数据时会有较高的错误率。而数据正常拟合的模型,对数据的拟合效果则是介于欠拟合和过拟合之间,训练获得不那么复杂的模型,保证在测试集上的泛化能力。3种情况在训练集上的预测误差的表现形式为:欠拟合>正常拟合>过拟合;而在测试集上的预测误差形式为:欠拟合>过拟合>正常拟合。
针对回归问题,在对连续变量进行预测时,3种数据拟合情况如下图所示,显示了对一组连续变量进行数据拟合时,可能出现的欠拟合、正常拟合与过拟合的三种情形。
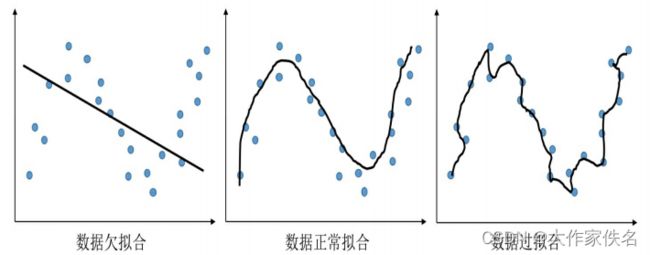
很多时候面对高维的数据,很难可视化出分类模型的分界面与回归模型的预测效果,那么如何判断模型的拟合情况呢?针对这种情况,通常可以使用两种判断方案:一是判断在训练集和测试集上的预测误差的差异大小,正常拟合的模型通常在训练集和测试集上的预测误差相差不大,而且预测效果均较好;欠拟合模型在训练集和测试集上的预测效果均较差;过拟合模型则会在训练集上获得很小的预测误差,但是在测试集上会获得较大的预测误差。二是可视化出模型在训练过程中,3种不同的数据拟合在训练数据和测试数据(或验证数据)上的损失函数变化情况,如下图所示。

2.2 避免欠拟合与过拟合的方法
在实践中,如果发现训练的模型对数据进行了欠拟合或者过拟合,通常要对模型进行调整,解决这些问题是一个复杂的过程,而且经常需要进行多项调整,下面介绍一些可以采用的解决方法。
1.增加数据量
如果训练数据较少,可能会导致数据欠拟合,偶尔也会发生在训练集上过拟合的问题。因此较多的训练样本通常会使模型更加稳定,所以训练样本的增加不仅可以得到更有效的训练结果,也能在一定程度上调整模型的拟合效果,增强其泛化能力。但是如果训练样本有限,也可以利用数据增强技术对现有的数据集进行扩充。
2.合理的数据切分
针对现有的数据集,在训练模型时,可以将数据集切分为训练集、验证集和测试集(或者使用交叉验证的方法)。在对数据进行切分后,可以使用训练集来训练模型,通过验证集监督模型的学习过程,也可以在网络过拟合之前提前终止模型的训练。在模型训练结束后,可以利用测试集来测试训练结果的泛化能力。
当然在保证数据尽可能地来自同一分布的情况下,如何有效地对数据集进行切分也很重要,传统的数据切分方法通常按照60:20:20的比例拆分,但是数据量不同,数据切分的比例也不尽相同,尤其在大数据时代,如果数据集有几百万甚至上亿级条目时,这种60:20:20比例的传统划分已经不再适合,更好的方式是将98%的数据集用于训练,保证尽可能多的样本接受训练,1%的样本用于验证集,这1%的数据已经有足够多的样本来监督模型是否过拟合,最后使用1%的样本测试网络的泛化能力。所以,针对数据量的大小、网络参数的数量,数据的切分比例可以根据实际需要来确定。
3.正则化方法
正则化方法是解决模型过拟合问题的一种手段,其通常会在损失函数上添加对训练参数的范数惩罚,通过添加的范数惩罚对需要训练的参数进行约束,防止模型过拟合。常用的正则化参数有l,和1,范数,1,范数惩罚的目的是将参数的绝对值最小化,1,范数惩罚的目的是将参数的平方和最小化。使用正则化防止过拟合非常有效,在经典的线性回归模型中,使用1范数正则化的模型叫作LASSO回归,使用1,范数正则化的模型叫作Ridge回归,这两种方法会在后面的章节进行介绍。
3.实例分析
3.1鸢尾花数据集
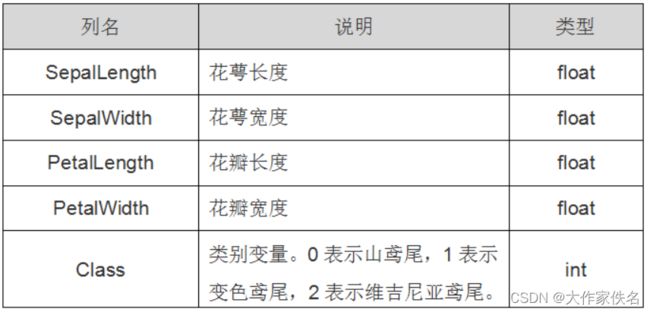
在Sklearn机器学习包中,集成了各种各样的数据集。鸢尾花(Iris)数据集,它是很常用的一个数据集。鸢尾花有三个亚属,分别是山鸢尾(Iris-setosa)、变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica)。该数据集一共包含4个特征变量,1个类别变量。共有150个样本,iris是鸢尾植物,这里存储了其萼片和花瓣的长宽,共4个属性,鸢尾植物分三类。
3.2 对鸢尾花数据进行聚类
##输出高清图像
##图像显示中文的问题
import matplotlib
matplotlib.rcParams['axes.unicode_minus'] = False
import seaborn as sns ##设置绘图的主题
sns.set(font="Kaiti",style="ticks" , font_scale=1.4)
import pandas as pd #设置数据表每个单元显示内容的最大宽度
pd.set_option ("max_colwidth",100)
import numpy as np
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
from sklearn import metrics
from sklearn.model_selection import train_test_split,cross_val_score
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
from sklearn.model_selection import KFold,StratifiedKFold
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from mlxtend.plotting import plot_decision_regions
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
##数据准备,读取鸢尾花数据集
X,y=load_iris(return_X_y=True)
##为了方便数据的可视化分析,将数据降维到二维空间
pca=PCA(n_components=2,random_state=3)
X=pca.fit_transform(X)
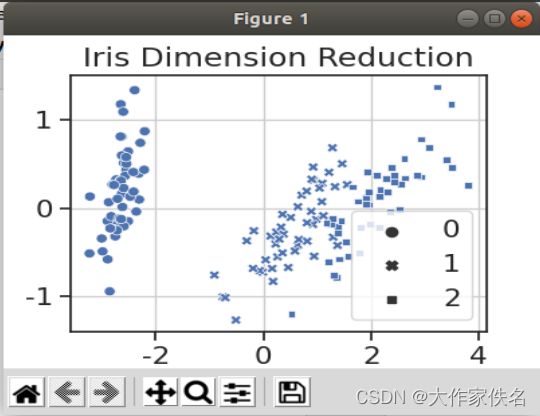
#可视化数据降维后在空间中的分布情况
plt.figure(figsize=(4,3))
sns.scatterplot(x=X[:,0],y= X[:,1],style=y)
plt.title("Iris Dimension Reduction")
plt.legend(loc="lower right")
plt.grid()
plt.show()
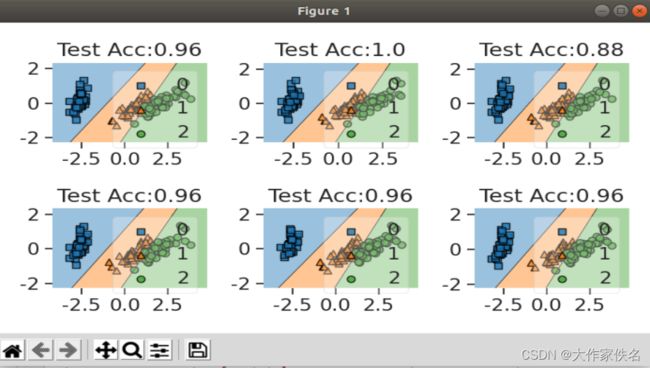
##使用KFold对Iris数据集分类
kf=KFold(n_splits=6,random_state=1,shuffle=True)
datakf=kf.split(X,y)
##获取6折数据
##使用线性判别分类算法进行数据分类
LDA_clf=LinearDiscriminantAnalysis(n_components=2)
scores=[]
##用于保存每个测试集上的精度
plt.figure(figsize=(7,4))
for ii,(train_index,test_index) in enumerate (datakf):
#使用每个部分的训练数据训练模型
LDA_clf=LDA_clf.fit (X[train_index], y[train_index])#计算每次在测试数据上的预测精度
prey=LDA_clf.predict (X[test_index])
acc=metrics.accuracy_score(y[test_index] ,prey)##可视化每个模型在训练数据上的切分平面
plt.subplot(2,3,ii+1)
plot_decision_regions (X[train_index], y[train_index],LDA_clf)
plt.title ("Test Acc:"+str(np.round (acc,4)))
scores.append(acc)
plt.tight_layout()
plt.show()
#计算精度的平均值
print("平均Acc:" , np.mean (scores))
结果