多目标跟踪 TAO 数据集使用方法分享
之前给大家分享了多目标跟踪任务及5个相关数据集,其中提到的TAO数据集很受小伙伴们欢迎,今天就带大家一起来看看。
目录
一、数据集简介
二、数据集详细信息
三、数据集任务定义及介绍
四、数据集文件结构解读
五、数据集下载链接
一、数据集简介
发布方:Carnegie Mellon University, Inria, Argo AI
发布时间:2020
背景:
在多目标跟踪领域类别往往来自自动驾驶和视频监控中特定的几个类(车辆、行人、动物等),忽略了真实世界的大多数物体。
众所周知,COCO等类别丰富的大规模数据集极大的促进了目标检测领域的发展,故此,来自CMU等单位的学者推出一个类似COCO的类别多样化的MOT数据集(TAO),用于跟踪任何物体,以期改变多目标跟踪的现状。
简介:
TAO数据集由2907个不同环境的高清视频组成,平均长度36.8秒,包含833个类别,对比现有的公开目标跟踪数据集,TAO数据集样本种类更加丰富。
二、数据集详细信息
1. 标注数据量
训练集:500段视频,包括534092个 jpg图像
测试集:1,419段视频,包括1502450个 jpg图像
验证集:993段视频,包括1045668个 jpg图像
2. 标注类别
数据集中对象的标注共有833个类别:其中488个类别和LVIS这个数据集相同;数据集总共包含2907个不同环境的高清视频;TAO中的数据来源于7个其他数集:ArgoVerse,BDD,Charades,LaSOT,YFCC100M,AVA,HACS。

3. 可视化
下面是 TAO 的原视频的部分样例的标注结果,原始视频数据来源于 Charades, LaSOT 和 ArgoVerse三个数据集。
原视频标注结果
汽车-原视频标注结果
室内-原视频标注结果
三、数据集任务定义及介绍
多目标跟踪
● 任务定义
在给定的一段视频中识别与跟踪多个目标。
● 评估
a. 评估过程
● 在第  帧,ground truth 为
帧,ground truth 为  ,预测结果 hypothesis 为
,预测结果 hypothesis 为 ![]() ,其中每个
,其中每个 ![]() 与每个
与每个 ![]() 都属于一个特定的轨迹,即可能已经出现在此前的若干帧中。
都属于一个特定的轨迹,即可能已经出现在此前的若干帧中。
● 对于 ![]() ,若交并比
,若交并比 ![]() ,则二者可建立关联(relationship),其中
,则二者可建立关联(relationship),其中 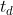 为预设的阈值,在 TAO中为
为预设的阈值,在 TAO中为 ![]() 。
。
● 若 ![]() 在第
在第 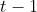 帧匹配(matched),且在第 帧可建立关联,则在第 帧直接进行匹配。
帧匹配(matched),且在第 帧可建立关联,则在第 帧直接进行匹配。
● 对于剩余未匹配的 ground truth 和 hypothesis,基于建立的关联关系,计算最大二分匹配。
● 仍未匹配的 ground truth 为 False Negative,仍未匹配的 hypothesis 为 False Positive。
● 若  与
与  匹配,且此前最近的一次匹配对象为
匹配,且此前最近的一次匹配对象为 ![]() ,则 在第 帧发生一次 identity switch (IDSW)。
,则 在第 帧发生一次 identity switch (IDSW)。
b. 评价指标
TAO竞赛所用的评价指:
https://motchallenge.net/results/TAO_Challenge/

四、数据集文件结构解读
1. 目录结构
dataset_root/
├── train/ #训练数据集,包含七个数据集ArgoVerse,BDD,Charades,LaSOT,YFCC100M,AVA,HACS总共包含352504个文件
│ ├── ArgoVerse/ #数据集ArgoVerse,包含37个视频文件,总共21967个jpg文件
│ │ ├── rear_right_26d141ec-f952-3908-b4cc-ae359377424e/#固定时间的1个视频文件,此文件中有451个jpg(帧)文件
│ │ │ ├── ring_rear_right_315970942123500864.jpg #*.jpg: 图片文件(帧)
│ │ │ └── ...
│ │ ├── side_right_84c35ea7-1a99-3a0c-a3ea-c5915d68acbc/#固定时间的1个视频文件,此文件中有871个jpg(帧)文件
│ │ │ └── ...
│ │ └── ...
│ ├── BDD/ #数据集BDD,包含54个视频文件,总共84294个jpg文件
│ │ ├── b1d0a191-03dcecc2/ #固定时间的1个视频文件,此文件中有1171个jpg(帧)文件
│ │ │ ├── frame0001.jpg #*.jpg: 图片文件(帧)
│ │ │ └── ...
│ │ ├── b1f85377-44885085/ #固定时间的1个视频文件,此文件中有2341个jpg文件件
│ │ │ └── ...
│ │ └── ...
│ └── ...
├── test/ #测试数据集,包含七个数据集ArgoVerse,BDD,Charades,LaSOT,YFCC100M,AVA,HACS总共包含982754个文件
│ ├── ArgoVerse/ #数据集ArgoVerse,包含112个视频文件,总共62572个jpg文件
│ │ ├── 08aa8ed7-386d-373e-a56a-f01444a8d7e5/ #固定时间的1个视频文件,此文件中有451个jpg文件
│ │ │ └── ...
│ │ ├── rear_right_0f0d7759-fa6e-3296-b528-6c862d061bdd/#固定时间的1个视频文件,此文件中有451个jpg文件
│ │ │ └── ...
│ │ └── ...
│ └── ...
├── val/ #验证数据集,包含七个数据集ArgoVerse,BDD,Charades,LaSOT,YFCC100M,AVA,HACS总共698485个文件
│ ├── ArgoVerse/ #数据集ArgoVerse,包含74个视频文件,总共44474个jpg文件
│ │ ├── 00c561b9-2057-358d-82c6-5b06d76cebcf/ #固定时间的1个视频文件,此文件中有901个jpg文件
│ │ │ ├── ring_front_center_315969629022515560.jpg #*.jpg: 图片文件(帧)
│ │ │ └── ...
│ │ ├── rear_right_028d5cb1-f74d-366c-85ad-84fde69b0fd3/#固定时间的1个视频文件,此文件中有451个jpg文件
│ │ │ ├── ring_rear_right_315972720027556456.jpg #*.jpg: 图片文件(帧)
│ │ │ └── ...
│ │ └── ...
│ └── ...
└── annotations #标注文件
├── checksums
│ ├──train_checksums.json #训练集所有目录文件及目录文件下的所有jpg文件
│ └──validation_checksums.json #验证集所有目录文件及目录文件下的所有jpg文件
├──video-lists #视频文件列表
│ ├──README.md
│ ├──tao_argoverse.txt #关于数据集ArgoVerse的视频文件名
│ ├──tao_ava.txt #关于数据集AVA的视频文件名
│ ├──tao_bdd.txt #关于数据集BDD的视频文件名
│ ├──tao_charades.txt #关于数据集Charades的视频文件名
│ ├──tao_charades_subjects.txt #关于数据集Charades中主题的视频文件名
│ ├──tao_hacs.txt #关于数据集HACS的视频文件名
│ ├──tao_lasot.txt #关于数据集LaSOT的视频文件名
│ └──tao_yfcc.txt #关于数据集YFCC100M的视频文件名
├──README.md
├──test_categories.json #测试数据只有test_without_annotations.json中的categories信息
├──test_without_annotations.json #测试数据标注文件信息
├──train.json #训练数据集的标注文件信息
├──train_with_freeform.json #训练数据freeform形式
├──validation.json #验证数据集标注文件信息
└──validation_with_freeform.json #验证数据freeform形式2. 标注文件及其他文件说明
● 标注的json文件格式如下:
以 train.json 文件为例,其他 test 和 validation 的标注文件信息类似。train.json中其注释文件中的内容就是一个字典数据结构,包括以下7个字段:videos,annotations,tracks,images,info,categories,licenses。
训练数据的标注样例如下:
{
"videos": [
{
"id": 0,
"height": 425,
"width": 640,
"date_captured": "2013-11-19 21:22:42",
"neg_category_ids": [
342,
57,
651,
357,
738
],
"name": "train/YFCC100M/v_f69ebe5b731d3e87c1a3992ee39c3b7e",
"not_exhaustive_category_ids": [805,95],
"metadata":: {"dataset": "YFCC100M", "user_id": "22634709@N00", "username": "Amsterdamized"}
},
...
],
"annotations": [
{
"bbox": [
114,
166,
67,
71
],
"category_id": 95,
"iscrowd":0,
"image_id": 0,
"id": 0,
"track_id":0,
"_scale_uuid":"5a32709e-44a0-47b9-85af-b01286adea67",
"scale_category":"moving object",
"video_id": 0,
"segmentation": [
[
114,
166,
181,
166,
181,
237,
114,
237
]
],
"area": 4757
},
...
],
"tracks": [
{
"id":0,
"category_id":95,
"video_id":0
}
],
"images": [
{
"video": "train/YFCC100M/v_f69ebe5b731d3e87c1a3992ee39c3b7e",
"_scale_task_id": "5de800eddb2c18001a56aa11",
"id": 0,
"license": 0,
"height": 480,
"width": 640,
"file_name": "train/YFCC100M/v_f69ebe5b731d3e87c1a3992ee39c3b7e/frame0391.jpg",
"frame_index":390,
"license": 0,
"video_id": 0
},
...
],
"info": {
"year": 2020,
"version": "0.1.20200120",
"description": "Annotationimported from Scale",
"contributor": " ",
"url": " ",
"data_created":""2020-01-20 15:49:53.519740""
},
"categories": [
{
"frequency": "r",
"id": 1,
"synset":"acorn.n.01",
"image_count":0,
"instance_count":0,
"synonyms": [
"acorn"
],
"def": "nut from an oak tree",
"name": "acorn",
}
...
],
"licenses": [
{
"Unknown"
}
]
}
...整体字段结构
{
"videos": [video], #视频帧相关属性
"annotations" : [annotation],
"tracks": [track], # {'category_id': 805, 'id': 72, 'video_id': 11}
"images" : [image], # 图像相关属性
"info" : info,
"categories": [category], # "{ 'id': 1, 'name': 'acorn', 'synset': 'acorn.n.01',....}"
"licenses" : [license],
}各字段解析
videos: {
"id": int,
"height" : int, #视频中的图像height
"width" : int, #视频中的图像width
"date_captured":str, #数据获取时间
"neg_category_ids": [int], # 标注不完整的类别
"name": str, #记录视频的相对位置 比如 'train/YFCC100M/v_f69ebe5b731d3e87c1a3992ee39c3b7e'
"not_exhaustive_category_ids": [int], # 在图中不存在的类别
"metadata": dict, # Metadata about the video
}
annotation: {
"bbox": [x,y,width,height], #[左上角x,左上角y,width,height],
"category_id":int,
"iscrowd":int,
"id":int,
"track_id":int,
"_scale_uuid":str,
"scale_category":str,
"video_id": int,
"segmentation":[polygon] , # 标注的多边形点,两个一对组成 x,y 位置
"area":int
}
tracks: {
"id": int, #跟踪任务ID
"category_id": int, #类别ID
"video_id": int #video ID
}
images: {
"video": str,
"_scale_task_id": str,
"id": int,
"license": int,
"height": int,
"width": int,
"file_name": str,
"frame_index":int,
"license": int,
"video_id": int
}
info{
"year" : int,
"version ": str,
"description ": str,
"contributor" : str,
"url" : str,
"date_created" : datetime,
}
categories: {
"frequency": str, # 这个类别在所有图中出现的频次
"id": int,
"synset":str, # 对类别唯一的识别字符串
"image_count":0, # 标注了这个类别的图片数量
"instance_count":0, # 标注了这个类别的实体数量
"synonyms": [str], # 同义词
"def": str, # 对这个识别字符串的定义
"name": str,
}
licenses: {
"Unknown"
}● 其他json文件格式:
tao_lasot.txt 的文件格式如下:
microphone-10
elephant-12
bus-4
elephant-10
basketball-14
frog-11
...即每行为一个半分钟左右的视频文件名。其他txt文件如tao_argoverse.txt、tao_ava.txt 同理。
五、数据集下载链接
OpenDataLab平台为大家提供了完整的数据集信息、直观的数据分布统计、流畅的下载速度、便捷的可视化脚本,欢迎体验。点击原文链接查看。
https://opendatalab.com/TAO
参考资料
[1]官网:https://taodataset.org/
[2]论文:A Dave, T Khurana,P Tokmakov, et al. Tao: A large-scale benchmark for tracking any object. in ECCV, 2020. Springer, Cham, 2020: 436-454.
[3]Github:https://github.com/TAO-Dataset/tao