深度学习图像标注工具labelme
来源:极客Merry

前言
在深度学习中若是没有带标注的数据,这可能会阻碍研究的进展,所以深度学习第一步就是制作数据集,手动去标注一些数据。LabelMe就是这样一个在线的图像数据标注工具:
LabelMe工具地址
http://labelme.csail.mit.edu/Release3.0/
今天要介绍的图像标注工具是受到LabelMe启发的,使用Python和PyQT进行重写的一个离线工具labelme:
labelme的GitHub地址
https://github.com/wkentaro/labelme
labelme可以通过多边形,矩形,圆形,直线和点的方式对图像进行标注,能够满足语义分割和目标检测等任务的标注要求。同时,labelme通过json文件存储标注的信息。
01
labelme安装
各个平台的安装方法在GitHub上已有说明,我使用的是Win10,在Win10,Python3环境下的安装也很简单:
pip install pyqt5
pip install labelme
如果安装速度过慢,可以考虑换源:
pip install labelme -i https://pypi.tuna.tsinghua.edu.cn/simple
安装完成后,在命令行执行以下命令,就会出现labelme的界面
labelme
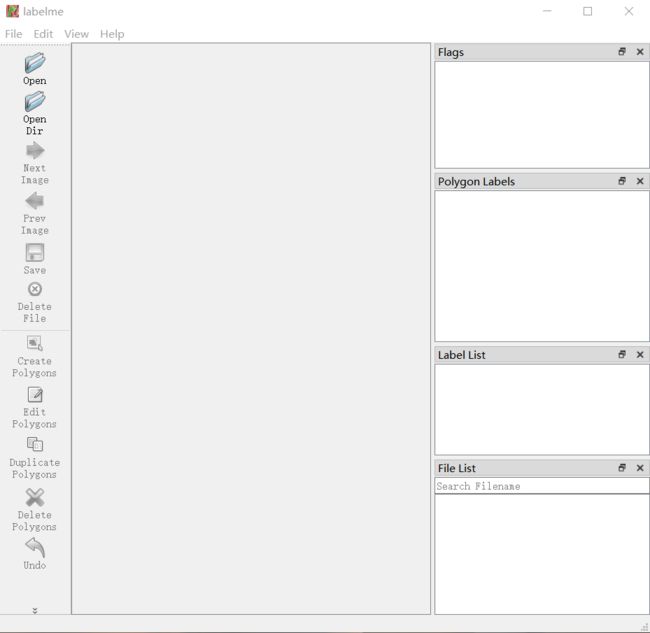
然后就可以对图像进行标注了。Open选项是打开一张图像,对单张图像进行标注,OpenDir选项是选中要标记的图像文件夹,对文件夹内的所有图像进行标注。
02
语义分割标注
点击"open",打开需要标注的图像,选择"CreatePolygons",然后对目标区域进行标注。
"CreatePolygons"是采用多边形方式标注,同样有矩形(Rectangle),圆形(Circle),线段(Line)和点(Point)的方式进行标注,可根据需要自由选择。

标注完成后,点击"save"会生成一个json文件,这个文件就保存了图像标注的信息。打开json文件看看里面都是什么东东。限于篇幅原因,只展示关键的数据信息。
下面的json文件只展示了桌子的标注信息(上图中两个人的标注信息由于太长,故删去)。可以看到,"shapes"字段包含了整幅图像所有区域的标注点信息,具体的各个区域标注的点的信息都存在"points"里,它表示的是图像上构成多边形标注的各点坐标,"label"指明该目标区域的类别,"imageData"参数保存了原始图像的信息。
{
"version": "4.5.7",
"flags": {},
"shapes": [
{
"label": "tabel",
"points": [
[
304.34715025906735,
274.3523316062176
],
[
330.7720207253886,
268.13471502590676
],
[
367.0414507772021,
268.9119170984456
],
[
393.98445595854923,
279.01554404145077
],
[
422.74093264248705,
295.0777202072539
],
[
432.0673575129534,
316.0621761658031
],
[
426.6269430051814,
331.0880829015544
],
[
422,
337
],
[
292,
337
],
[
277.4041450777202,
336.7875647668394
],
[
273.25906735751295,
303.8860103626943
],
[
283.10362694300517,
290.1554404145078
]
],
"group_id": null,
"shape_type": "polygon",
"flags": {}
}
],
"imagePath": "2011_000003.jpg",
"imageData": "巨长巨长的图像数据",
"imageHeight": 338,
"imageWidth": 500
}
然后将json文件转换为对应的标签图像。进入json文件所在目录下,在命令行执行以下命令
labelme_json_to_dataset 2011_000003.json在同一级目录下会生成一个与json同名的文件夹,里面有四个文件:
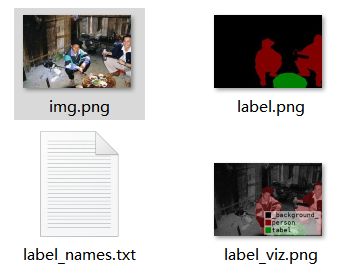
"label.png"就是语义分割需要的标签数据了。这张图像标注了两类区域(加上背景总共三类),一类是"person",另一类是"tabel",同一类别的区域用同一种颜色填充。

读取"label.png"看看里面底层数据都是什么妖魔鬼怪:写一个脚本将图像数据转换为ASCII码,并且保存到txt文件中,这个过程有点像是图像转字符画。
import numpy as np
from PIL import Image
png_file = "label.png路径"
img = Image.open(png_file)
img = img.resize((int(img.size[0]*0.25),int(img.size[1]*0.25)))
print(img.size)
img_arr = np.asarray(img)
# 统计图像中的像素点数值
label = np.unique(img_arr)
print(label)
height, width = img_arr.shape
print(height, width)
img2code = ''
for i in range(height):
for j in range(width):
#pixel = img.getpixel((j, i))
#img2code += ascii(pixel)
img2code += ascii(img_arr[i][j])
img2code += '\n'
fo = open('txt存储路径', 'w')
fo.write(img2code)
fo.close()
打开刚刚保存的txt文件,因为太大全屏显示不了,将字体大小设置为七号,可以看到效果如下。字符画的宽高比例和原图不一样,这是因为竖直方向上显示字符占用的空间大小和水平方向上不一样。

从上图可以看出,最终得到的标签图像,底层存储的数值按不同类别区域设置为不同数值,背景的每个像素数值设置为0,person的每个像素数值设为1,tabel的每个像素数值设为2。
03
批量转换json为标签图像
"labelme_json_to_dataset"这个命令能将json文件转为标签数据,但是它一次只能转换一个,若是有成千上万张图像简直难以想象,本来标注完图像已经头昏脑胀,难道还要我一个一个转换? 不可能的!这时需要自己写个脚本来帮我们完成这个任务。
不可能的!这时需要自己写个脚本来帮我们完成这个任务。
第一种方式借助于labelme提供的"labelme_json_to_dataset"这个命令。利用os.system()函数批量转换json文件,每个json生成的同名文件夹与json在同一级目录下。
import os
json_path = "json文件保存路径"
for filename in os.listdir(json_path):
os.system("labelme_json_to_dataset "+os.path.join(json_path,filename))
第二种方式使用labelme提供的API。使用img_b64_to_arr()函数,将json文件中"iamgeData"字段的字符转换为原始图像;然后根据json文件中"shapes"字段的标注信息,使用labelme_shapes_to_label()函数获取到标签图像lbl。
有童鞋可能会发现,此时的lbl标签图像一片漆黑,什么也没有。这是因为图像中各点的像素值是标签对应的数字(如同上面画的字符画),而这些数字都很小:0,1,2,3....,而黑色对应的像素值为0,所以lbl图像的颜色和黑色非常接近,看起来就是一片漆黑。
这时我们只需要给图像上色就可以了:使用putpalette()函数,而且我们可以自定义各个类别区域的颜色。
import json
import os
import numpy as np
from PIL import Image
from labelme import utils
def json2mask_multi(json_path, save_path):
if not os.path.exists(save_path):
os.makedirs(save_path)
for json_name in os.listdir(json_path):
data = json.load(open(os.path.join(json_path, json_name)))
json_name = json_name.split('.')[0]
# 根据imageData字段的字符可以得到原图像
img = utils.img_b64_to_arr(data['imageData'])
# lbl为label图像(用类别名对应的数字来标,背景为0)
# lbl_names为label名和数字的对应关系字典
lbl, lbl_names = utils.labelme_shapes_to_label(img.shape, data['shapes'])
mask = Image.fromarray(lbl).convert('L')
# putpalette给对象加上调色板,相当于上色:R,G,B
# 三个数一组,对应于RGB通道,可以自己定义标签颜色
mask.putpalette([0, 0, 0,
255, 0, 255,
255, 255, 0,
128, 128, 128])
mask.save(os.path.join(save_path, json_name + ".png"))
json_path = "json文件存储路径"
save_path = "标签图像的保存路径"
json2mask_multi(json_path,save_path)
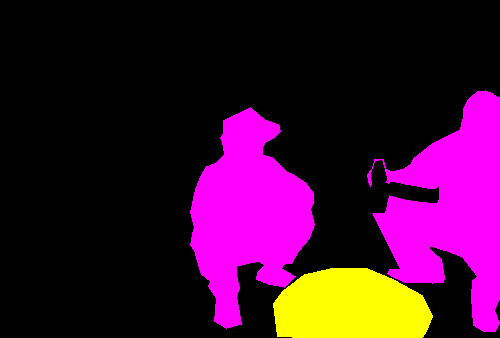
本文只是对labelme简单介绍了一番,因为自己在做语义分割时需要做一些标注,所以只介绍了语义分割上的应用,而labelme还可以满足目标检测和图像分类任务的标注要求,这些功能就留给各位童鞋去探索研究,这里就不一一展开来说明。
------- End -------
点右下角「在看」与转发
是对我们最大的支持
特别推荐下公众号「价值前瞻」,分享读书、成长和投资思考,欢迎来串门。
回复「书单」 可获取精选书单一份,包括《如何阅读 一本书》、《巴菲特之道》、《金字塔原理》、高瓴张磊的《价值》、《投资最重要的事》、《戴维斯王朝》等书籍的笔记内容或思维导图


价 值 前 瞻
做一个有远见的人

扫码关注,查看更多内容