SimGCL:Are Graph Augmentations Necessary? Simple GraphContrastive Learning for Recommendation 论文代码解读
一、前言
1、摘要

CL通过学习更均匀的用户/项目表示,这隐式地减轻了流行度偏差。作者提出了一种简单的CL方法,该方法丢弃图增强,仅通过在嵌入空间中添加均匀噪声来自由调整学习表示的均匀性,从而创建对比视图。
2、介绍
CL应用于推荐的一种典型方法是,首先使用结构扰动(如随机边/节点的丢弃)来增强用户-项二部图,然后最大化通过图编码器学习的不同视图下表示的一致性。
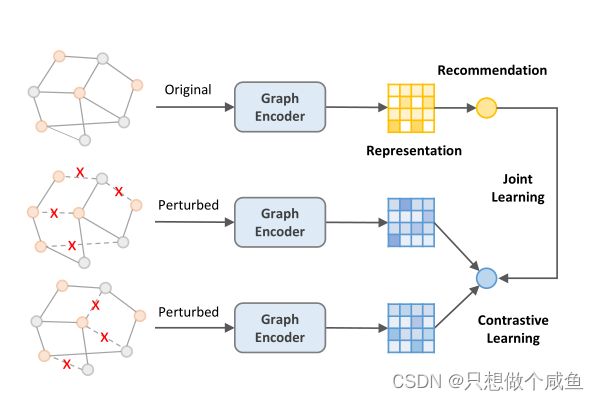
问题:当将CL与推荐集成时,我们真的需要图增强吗?
对推荐性能真正重要的是CL的损失,而不是图的增强。优化对比损失InfoNCE可以学习更统一的用户/项目表示,这在减轻流行偏差方面发挥了隐形的作用。
(图的增强并不是完全无用的,因为原始图的适当扰动有助于学习抗干扰的表示。然而,生成手工制作的图增强需要在训练过程中不断地重建图的邻接矩阵,这是相当耗时的。此外,删除一个临界边/节点可能会将一个连接图分割成几个断开的组件,这可能会使增广图和原始图共享很少的可学习不变性。)
3、贡献
在发现表示分布的均匀性是关键的基础上,我们开发了一种无图增强的CL方法,其中均匀性更可控。从技术上讲,我们遵循上图中所示的图CL框架,但我们放弃了基于dropout的图增强,而是在原始表示中添加随机均匀噪声,以实现表示层的数据增强。施加不同的随机噪声会在对比视图之间产生差异,而可学习的不变性仍然保持不变。与图增强相比,噪声版本直接将嵌入空间正则化,使其分布更均匀,易于实现,且效率更高。
二、传统的对比学习
1、SGL
在SGL中的联合学习方案被正式定义为:
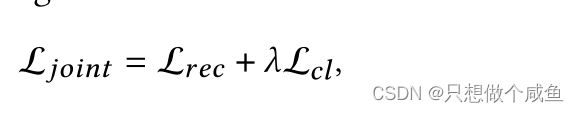
前者是BPR—loss,后者是 InfoNCE—loss
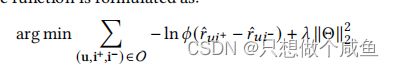
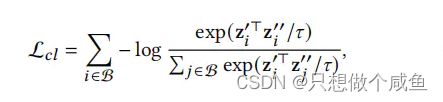
其中,是采样批次中的用户/项目,z'和z''是从两个不同的基于dropout的增强子图中学习到的2归一化的维节点表示,>0是温度系数。CL损失鼓励了zi'和zi''之间的一致性,它们是同一节点的增广表示,是彼此的正样本,同时最小化了'和z'之间的一致性,它们是彼此的负样本。
LightGCN作为其主干,其消息传递过程定义为:

2、图增强的必要性
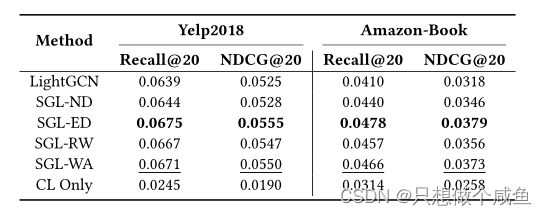
上表中,ND表示节点dropout,ED表示边缘dropout,-RW表示随机游走(即多层边缘dropout),CL意味着只有SGL中的CL损失被最小化。可以观察到,SGL的所有变体都大大优于LightGCN,这证明了CL在提高推荐性能方面的有效性。令人惊讶的是,当图的增强被删除时,性能的提高仍然是如此显著,以至于SGL-WA甚至优于SGL-ND和SGL-RW。作者推测节点dropout和随机游走(特别是前者)很可能丢弃关键节点和相关的边,从而将相关的子图断开成各部分,这极大地扭曲了原始图。相比之下,边缘dropout干扰原始图语义的风险较低,因此SGL-ED比起SGL-WA可以保持微不足道的优势,这表明了适当的图增强的潜力。然而,考虑到在每个时期对邻接矩阵的耗时重建,作者认为应该重新考虑图扩充的必要性,并寻找更好的替代方案。此外,作者想知道SGL-WA出色的性能基础到底是什么。
3、InfoNCE Loss带来的更大影响

根据上图,我们可以观察到明显不同的特征/密度分布。在最左边的一列中,LightGCN显示了高度聚集的特征,主要位于几段弧线上。而在第二列和第三列中,分布变得更加均匀,密度估计曲线也不那么陡峭。在第四列中,我们绘制了等式中对比损失学习的特征,这里的分布几乎是完全一致的。
作者认为有两个原因可以解释高度聚集的特征分布。第一个是LightGCN中的消息传递机制。随着层数的增加,节点嵌入变得局部相似。第二个是推荐数据中的流行度偏差,由于推荐数据通常遵循长尾分布,当是一个具有大量交互的流行项目时,用户嵌入将会不断更新到的方向。
作者得出一个结论,即分布的均匀性是对SGL中的推荐性能有决定性影响的潜在因素,而不是图增强。优化CL损失可以看作是一种隐式的去偏倚的方法,因为一个更均匀的表示分布可以保留节点的内在特征,提高泛化能力。
三、SIMGCL模型
模型图如下:
主干还是LightGCN,这里的训练就是原版,消息传递过程结点嵌入不加噪声,采用BPR损失函数
右侧是生成两个伪LightGCN的训练,为什么是伪呢?因为他在传播过程中在聚合后的嵌入加入噪声,提高抗干扰性,关于对比,也是右面两个伪LightGCN进行对比了,这一批次中两个视图中同一结点互为正样本,其他的就为负样本了,具体下面代码有展示,关于loss和上面讲的传统对比学习一样的损失函数,对比时用 InfoNCE—loss

由于操纵均匀表示分布的图结构是棘手的,作者将注意力转移到嵌入空间。受在输入图像中添加难以察觉的小扰动所构造的对抗性实例的启发,作者直接在表示中添加随机噪声,以实现有效的增强。



采用LightGCN作为图编码器来传播节点信息。在每一层,对当前节点嵌入施加不同比例的随机噪声。最终的扰动节点表示可以通过:

在计算最终表示时,作者跳过了输入嵌入E(0),因为作者通过实验发现,跳过它会导致我们的设置有轻微的性能提高。但是,如果没有CL任务,此操作将导致LightGCN的性能下降。
实验结果
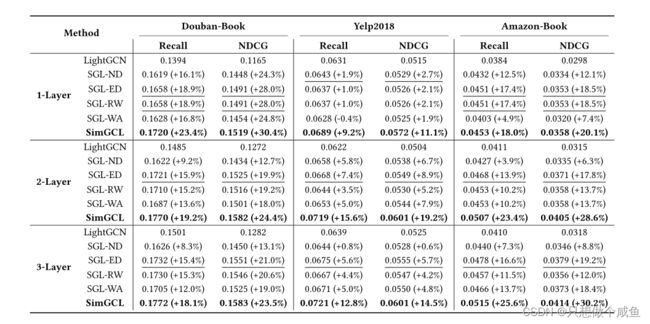
去偏差的能力
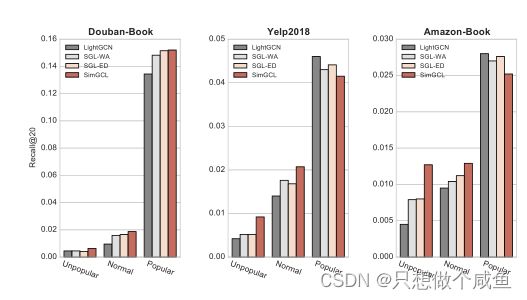
SimGCL的提升都来自于受欢迎程度较低的项目。它在推荐长尾项目方面的显著优势,在很大程度上弥补了它在“流行”组上的损失。相比之下,LightGCN倾向于推荐流行的项目,并在最后两个数据集上获得最高的召回值。SGL变体在探索长尾项目上介于LightGCN和SimGCL之间,并表现出相似的推荐偏好。
四、pytorch代码实现
仅作测试,对照论文梳理代码,(因为是我自己的数据集,所以不调参,只run)
1、数据集
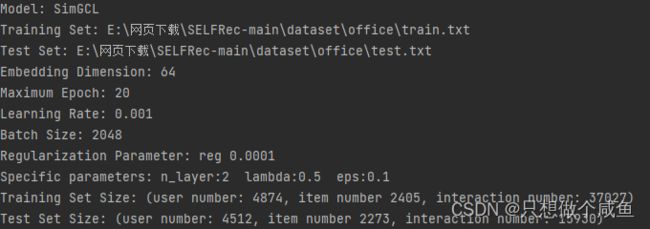
这里我用的是office数据集
下面是具体的参数及数据集描述
2、采样
虽然代码里和原来的lightGCN看起来不同,但是本质是一摸一样的,不同点在于输入的数据形式不同罢了,但是最后batch-size选择还是老样子
def next_batch_pairwise(data,batch_size):
training_data = data.training_data #37027
shuffle(training_data)
batch_id = 0
data_size = len(training_data)
while batch_id < data_size:
if batch_id + batch_size <= data_size:
users = [training_data[idx][0] for idx in range(batch_id, batch_size + batch_id)] #选2048个user(可能会有重复的userID)
items = [training_data[idx][1] for idx in range(batch_id, batch_size + batch_id)] #提取相应的交互的正样本
batch_id += batch_size
else:
users = [training_data[idx][0] for idx in range(batch_id, data_size)]
items = [training_data[idx][1] for idx in range(batch_id, data_size)]
batch_id = data_size
u_idx, i_idx, j_idx = [], [], []
item_list = list(data.item.keys()) #2405
for i, user in enumerate(users):
i_idx.append(data.item[items[i]])
u_idx.append(data.user[user])
neg_item = choice(item_list) #随机选择负样本(一定是没交互过的)
while neg_item in data.training_set_u[user]: #如果有交互重新选
neg_item = choice(item_list)
j_idx.append(data.item[neg_item])
yield u_idx, i_idx, j_idx代码很繁琐,可以看下面的白话:
白话:例如batch_size=1024,我们先从训练数据中随机选取1024user,然后根据这些user找到对应的交互item(也叫正样本),然后从这个user没有交互的物品中,选择一个item作为负样本,如果不满足就继续重新选,over!!!
3、主干网络的训练
def forward(self, perturbed=False):
ego_embeddings = torch.cat([self.embedding_dict['user_emb'], self.embedding_dict['item_emb']], 0) #7297*64
all_embeddings = []
for k in range(self.n_layers):
ego_embeddings = torch.sparse.mm(self.sparse_norm_adj, ego_embeddings) #7297*64
all_embeddings.append(ego_embeddings) #list 2
all_embeddings = torch.stack(all_embeddings, dim=1) # 7297*2*64
all_embeddings = torch.mean(all_embeddings, dim=1) # 7297*64
user_all_embeddings, item_all_embeddings = torch.split(all_embeddings, [self.data.user_num, self.data.item_num])
return user_all_embeddings, item_all_embeddings就是lightGCN的传播过程
BPR损失
def bpr_loss(user_emb, pos_item_emb, neg_item_emb):
pos_score = torch.mul(user_emb, pos_item_emb).sum(dim=1) #2048
neg_score = torch.mul(user_emb, neg_item_emb).sum(dim=1) # 2048
loss = -torch.log(10e-8 + torch.sigmoid(pos_score - neg_score))# 2048
return torch.mean(loss)4、对比部分训练
def forward(self, perturbed=False):
ego_embeddings = torch.cat([self.embedding_dict['user_emb'], self.embedding_dict['item_emb']], 0) #7297*64
all_embeddings = []
for k in range(self.n_layers):
ego_embeddings = torch.sparse.mm(self.sparse_norm_adj, ego_embeddings)
if perturbed:
#random_noise = torch.rand_like(ego_embeddings).cuda()
random_noise = torch.rand_like(ego_embeddings) # 7297*64 产生同维度的噪
ego_embeddings += torch.sign(ego_embeddings) * F.normalize(random_noise, dim=-1) * self.eps # 7297*64
all_embeddings.append(ego_embeddings) #list 2
all_embeddings = torch.stack(all_embeddings, dim=1) # 7297*2*64
all_embeddings = torch.mean(all_embeddings, dim=1) # 7297*64
user_all_embeddings, item_all_embeddings = torch.split(all_embeddings, [self.data.user_num, self.data.item_num])
return user_all_embeddings, item_all_embeddings就是相比上面多了中间加噪声的部分
InfoNCE—loss
def InfoNCE(view1, view2, temperature):
view1, view2 = F.normalize(view1, dim=1), F.normalize(view2, dim=1) # 第一个加了干扰的 eu1 第二个加了干扰的eu2
pos_score = (view1 * view2).sum(dim=-1) #1563
pos_score = torch.exp(pos_score / temperature) #分子
ttl_score = torch.matmul(view1, view2.transpose(0, 1))
ttl_score = torch.exp(ttl_score / temperature).sum(dim=1) # 分母 1563
cl_loss = -torch.log(pos_score / ttl_score) #1563
return torch.mean(cl_loss)cl_loss = self.cl_rate * self.cal_cl_loss([user_idx,pos_idx])
def cal_cl_loss(self, idx):
#u_idx = torch.unique(torch.Tensor(idx[0]).type(torch.long)).cuda()
#i_idx = torch.unique(torch.Tensor(idx[1]).type(torch.long)).cuda()
u_idx = torch.unique(torch.Tensor(idx[0]).type(torch.long)) #1563
i_idx = torch.unique(torch.Tensor(idx[1]).type(torch.long)) #1077
user_view_1, item_view_1 = self.model(perturbed=True) #4874*64 2405*64 第一个加噪声的embedded U1+I1
user_view_2, item_view_2 = self.model(perturbed=True) #4874*64 2405*64 第二个加噪声的embedded U2+I2
user_cl_loss = InfoNCE(user_view_1[u_idx], user_view_2[u_idx], 0.2)
item_cl_loss = InfoNCE(item_view_1[i_idx], item_view_2[i_idx], 0.2)
return user_cl_loss + item_cl_loss
总结
在基于CL的推荐模型中,CL的损失是核心,而图的增强只起次要作用。优化CL损失可以得到更均匀的表示分布,这有助于在推荐的场景中消除偏差。然后,我们开发了一种简单的无图增强的CL方法,以一种更直接的方式来调节表示分布的均匀性。通过在表示中加入有向随机噪声,进行不同的数据增强和对比,提出的方法显著提高了推荐能力。大量的实验表明,该方法优于基于图增强的方法,同时大大减少了训练时间。