python图像增强_使用Python进行图像增强
Python中的图像增强示例
我目前正在进行一项研究,审查图像数据增强的深度和有效性。本研究的目标是在有限或者少量数据的情况下,学习如何增加我们的数据集大小,来训练鲁棒性卷积网络模型。
这项研究需要列出所有我们能想到的图像增强方法,并穷举所有这些组合,尝试提高图像分类模型的性能。首先出现在脑海中最简单的图片增强:是翻转,平移,旋转,缩放,隔离个别的r,g,b颜色通道,和添加噪音。更令人兴奋的增强是使用生成对抗网络模型,或用遗传算法交换生成器网络,更有甚者在图像中应用instagram风格的光照滤镜、随机区域锐化滤镜、基于聚类技术的均值图像增强等创新方法。
本文将向您展示如何使用NumPy对图像进行增强。
下面是一些增强技术的列表和说明,如果你能想到任何其他方法来增强图像,可提高图像分类器的质量,请留下评论。

原始图片(未增强)
增强
所有的增强都是在没有OpenCV库的情况下使用Numpy完成的
# Image Loading Code used for these examples
fromPIL importImage
importnumpy asnp
importmatplotlib.pyplot asplt
img = Image.open('./NIKE.png')
img = np.array(img)
plt.imshow(img)
plt.show()
翻转
翻转图像是最流行的图像数据增强方法之一。
这主要是由于翻转代码的简单性以及对于大多数问题的直观性,翻转图像会为模型增加价值。
下面的模型可以被认为是看到左鞋而不是右鞋,因此通过这种数据增加,模型对于看到鞋的潜在变化变得更加健壮。

#Flipping images with Numpy
flipped_img = np.fliplr(img)
plt.imshow(flipped_img)
plt.show()
平移
平移增强对检测类分类器有很大价值。 这个分类模型试图检测鞋子何时在图像中而不是在图像中。
平移将有助于它在不看鞋架的整个鞋子的情况下拿起鞋子。

# Shifting Left
fori inrange(HEIGHT, 1, -1):
forj inrange(WIDTH):
if(i < HEIGHT-20):
img[j][i] = img[j][i-20]
elif(i < HEIGHT-1):
img[j][i] = 0
plt.imshow(img)
plt.show()

# Shifting Right
forj inrange(WIDTH):
fori inrange(HEIGHT):
if(i < HEIGHT-20):
img[j][i] = img[j][i+20]
plt.imshow(img)
plt.show()

# Shifting Up
forj inrange(WIDTH):
fori inrange(HEIGHT):
if(j < WIDTH - 20andj > 20):
img[j][i] = img[j+20][i]
else:
img[j][i] = 0
plt.imshow(img)
plt.show()

#Shifting Down
forj inrange(WIDTH, 1, -1):
fori inrange(278):
if(j < 144andj > 20):
img[j][i] = img[j-20][i]
plt.imshow(img)
plt.show()
噪点
噪点是一种有趣的增强技术。 我已经看过很多关于对抗训练的有趣论文,你可以将一些噪点投入到图像中,因此模型无法正确分类。 但我仍然在寻找产生比下图更好的噪点的方法。 添加噪点可能有助于光照畸变并使模型更加鲁棒(编者就2:意思是这里让边缘光照发生失真,让尺度不变的情况下特征转变(SIFT),从而能增加鲁棒性(SURF),使得识别更加准确 ,不过,看这文章的水平应该是我多虑了)。
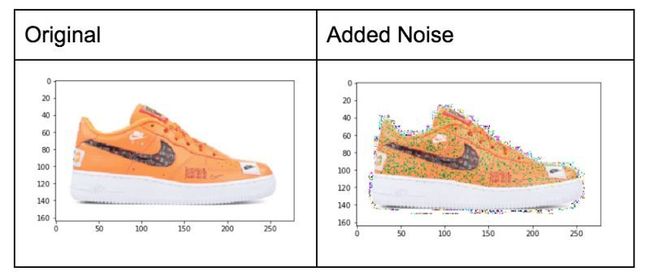
# ADDING NOISE
noise = np.random.randint(5, size = (164, 278, 4), dtype = 'uint8')
fori inrange(WIDTH):
forj inrange(HEIGHT):
fork inrange(DEPTH):
if(img[i][j][k] != 255):
img[i][j][k] += noise[i][j][k]
plt.imshow(img)
plt.show()
GANs(生成对抗网络)
我已经收到很多关于研究使用Generative Adversarial Networks进行数据增强的兴趣,下面是我能够使用MNIST数据集生成的一些图像。

正如我们从上面的图片中可以看出的那样,它们确实看起来像3 ,7和9。我目前在扩展网络架构方面遇到一些麻烦,以支持运动鞋的300x300x3尺寸输出,而不是28x28x1 MNIST数字。
但是,我对这项研究感到非常兴奋,并期待继续这项研究!感谢您阅读本文,希望您现在知道如何实现基本数据扩充以改进您的分类模型!
http://www.gair.link/page/TextTranslation/1088
你每天都有接触到计算机视觉,尽管你没有意识到使用 PCA 进行特征提取使用卷积神经网络做语义分割
如何通过深度学习轻松实现自动化监控
为计算机视觉生成大的、合成的、带标注的、逼真的数据集
使用深度学习做语义分割:简介和代码
使用 SKIL 和 YOLO 构建产品级目标检测系统
MultiTracker 类:基于 OpenCV 的多目标追踪(Python/C++)返回搜狐,查看更多