matlab基于dct的图像压缩编码解码_【融云分析】H.264视频编码的基本原理和过程...
前言:
在音视频通信中,音视频的数据压缩是有效降低带宽的主要方法;其中,视频占用了更高比例的带宽,视频压缩更为重要。
如果不压缩,一副 RGB 图像,按照 800 x 600 的分辨率, 每秒 25 帧的帧率, 那么:每秒的数据量 = 800 x 600 x 3 x 25 x 8 ( bit )。
H.264 压缩后,平均码率可以减少 20 倍;如果使用动态码率,对于某些简单场景的监控等,可以更大的压缩视频,同时保证视频质量。
视频压缩工具有很多,H.263、Mpeg-4、 VP8、VP9、 H.264 等等。目前最常见和最常用的视频压缩算法是 H.264,基于 H.264 比较流行的开源工具有 X264、OpenH264 以及 FFmpeg (内部集成 x264 和 OpenH264 ), 解码工具大多用 FFmpeg 实现。
视频编码的基本要求:
1:有足够的压缩比,能将压缩结果控制在一个范围内;
2:压缩后的视频,解压后要保证一定的视频质量。
H.264 的优势有什么呢?
1:很好的网络亲和性,更适合复杂网络传输;
2:更高的视频压缩比,在同等视频质量下;大约是H.263,Mpeg-4 的 2 倍;
3:目前移动端已经广泛支持 H.264 硬件编解码,效率和速度更快。
H.264/AVC 的常用概念:
帧和场:
视频的一帧,可以看做是一副完整的图像, 一帧视频可以分成两个隔行的场,通常叫做 “顶场” 和 “底场”。
为什么会有“场”的概念?
因为早期在电子显像管电视机中,图像是由电子逐行扫描显示的。为了更好的显示动态图像,就会先隔行扫描显示图像的 “顶场”,然后在扫描显示图像的“底场”。这样运动图像的显示效果会更好。
但是隔行扫描的实际效果是模糊了图像。目前随着科技的发展,在视频编码中,通常直接用一副完整的图像。
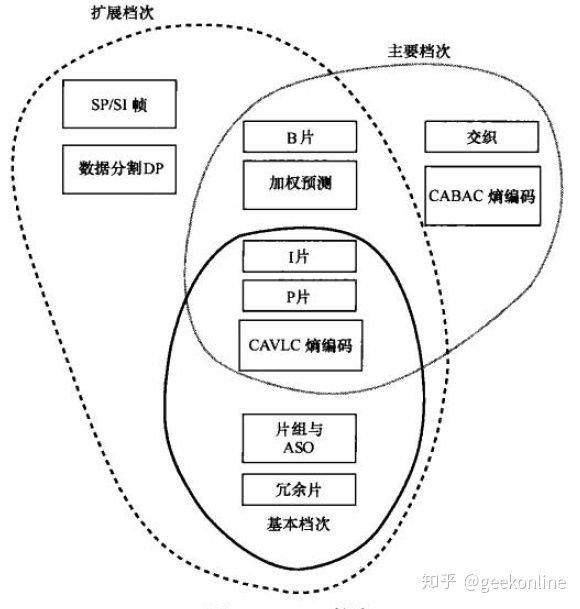
档次和级:
(1)基本档次:基于 I 帧 和 P 帧 ,支持 CAVLC 编码;适合视频会议,视频电话,实时视频流等。
(2)主要档次:支持各行视频,增加 B 帧编码,支持 CABAC 编码。主要用于视频存储等。
(3)扩展档次:支持流之间的切换,改进误码性能;主要用于视频点播等。
YUV 4:2:0 图像:
一帧没有经过压缩的位图数据一般保存的数据是每个像素用 RGB 表示,每个颜色分别用一个字节表示。
我们这里常用的 YUV 图像指的是 YUV 4:2:0 图像,用四个亮度 Y 分量对应一对 UV 色度分量。

RGB 转换 YUV 4:2:0 的公式:
Y = 0.299R + 0.587G + 0.114*B;
U = -0.169R – 0.331G + 0.5 *B ;
V = 0.5 R – 0.419G – 0.081*B;
由此可见,RGB 图像转到 YUV 4:2:0 图像的这一过程中是有图像质量损失的。
为什么用 YUV 4:2:0 ?
首先, YUV 4:2:0 比 RGB 图像小一半。每个像素为 12 bit。
其次,早期的电视分为黑白电视和彩色电视,如果是黑白电视,那么直接播放 Y 亮度分量。
如果是彩色电视,那么就可以全部直接播放。
视频编码系统的基本结构:

视频的压缩原理与过程:
1:我们先看一幅图像:(图1)

这幅图像中,大部分是绿色,如果仅仅将小球保留,绿色用一个变量和坐标表示,那么这幅图像的信息就可以很好的减少,也可以根据变量和坐标恢复图像。
2:再看一副图像:(图2)

这幅图像的小球,向右上角移动了一格,其它内容和信息都与上图基本一致;
如果已经有了“图1”, 那么只需要将“图2”与“图1”中的不同信息保存下来,那么就可以根据“差别信息”参考“图1” 来恢复显示“图2” 了。
这就是视频压缩的本质和原理:
空域压缩;
时域压缩。
GOP:
我们可以按照一定的图像数量进行编码,如 25 帧图像为一组,每组的第一帧图像通过帧内编码,我们称之为 IDR 帧,其它图像参考其它图像的信息进行编码,我们称之为 P 帧 / B 帧,那么可以将这一组数据一个 GOP。
如果一个 GOP 的第一帧图像 IDR 帧丢失或者损坏,那么这个 GOP 后面的所有视频数据将会解码错误。只有等到下一个 GOP,当解码器遇到 IDR 帧会即时刷新图像,清空参考图像列表。

宏块:
H.264 编码的最小单位,我们可以看做是一个宏块,就是一个 16 x 16 的图像区域,也可以划分的更小,如 8 x 8。
什么是预测编码?
在视频压缩中,就是将预测值与实际值作差,然后再次压缩。
帧内预测:
IDR帧 ,I 帧:
帧内编码就是当前帧不参考其它帧,可以独立解码的一种编码方式;
可以简单的想象为,一副 BMP 图像压缩为一副 JPEG 图像;
通常帧内编码的图像,我们称之为 I 帧 intra picture,就是不需要参考其它图像,可以自己独立解码出图像的视频数据帧。
需要注意的是:IDR 帧是 I 帧,但是 I 帧不是 IDR 帧。IDR 帧是一个 GOP 的第一帧,GOP 中间有可能出现 I 帧,后面的帧有可能参考 I 帧之前的视频帧,但是不可能越过 IDR帧。一般 IDR 帧 前面还有 SPS 和 PPS 信息。
在帧内编码中,宏块最多可以有九种预测模式,我们可以找到与原图最相近的预测图像:

帧间预测:
帧间预测技术分为 B 帧预测和 P 帧预测。
B 帧预测 – 双向预测:
主要是参考之前编码的帧和之后编码的帧;
B 帧的数据量更小,但是 B 帧由于需要参考后续帧,那么就会引入延时;
同时用到更多的计算开销;
B 帧不会作为参考帧,所以,丢弃 B 帧也不会引起花屏;如上面的“GOP 图“。
P 帧预测 – 单向预测:
主要参考之前编码过的视频帧;
后面为了清晰说明原理,以 BaseLine 为示例基础,仅包含 I 帧 和 P 帧;
运动矢量:
如:“图1”的小球位置坐标假设为(x0,y0), “图2”的小球位置坐标假设为(x1,y1),那么小球的运动矢量就是(x1 – x0,y1 – y0);
运动估计:
得到运动矢量的过程就是运动估计;

将预测数据和实际数据相减,去掉时域上的数据冗余,就得到了预测的“残差”数据,也就是补偿数据;
解码视频数据,可以根据补偿数据,运动矢量和参考图像恢复出当前图像。
这一步极大的减少了时间域上的图像冗余数据。
DCT – 离散余弦变化 :
这是一个复杂的数学名词,简单描述,就是去除像素间的相关性;
目的当然是进一步压缩数据。
举个例子:

更多的情况可能是图中情况,即便是这样,有效数据也更好的减少了,多了很多 “0” :

量化:
量化过程在不降低视觉效果的前提下减少图像的编码长度,减少图像信息中视觉恢复中不必要的信息。
量化结果,实际上是由量化步长决定的 (QStep),量化步长越小,图像的细节信息保留的越多,码率越高,图像质量越高。反之,量化步长值越大,图像质量越差。
量化是有损压缩,这一步的图像质量有一定的损失。但是前提是不影响正常的视觉和图像质量。
zig-zag 扫描 ,也有人称之为”锯齿扫描” :


zig-zag 扫描和 FFmpeg 官方标志
游程编码 – (RLC, Run Length Coding):
又称“运行长度编码”或“行程编码”,是一种统计编码,是一种无损压缩的编码方式。
其实锯齿扫描和游程编码可以看做是一体的。
游程编码进一步压缩保存了有效的保存扫描数据。
熵编码:
利用信源的统计特性进行码率压缩的编码称之为“熵编码”,也叫统计编码。
从名称来看,还是要压缩数据;这一步是无损压缩。基本原理就是给高频率数据短码,低频率数据长码。
从定义来看,就是指定一组数据中,根据数据出现概率来编码的一种方式。
在 H.264 中,也就是之前提到过的 CABAC 编码 和 CAVLC 编码。

本文图片部分主要来自于“百度图库”和《新一代视频编码压缩标准》。