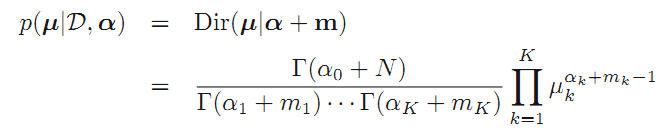"模式识别与机器学习"读书笔记——2.2 Multinomial Variables
2.1章里涉及的x只有两个值:0/1,这太少了,这章允许x有K个离散的值。
它对x取这K个值得表示是用一个k维向量表示的,x也就变成了一个k维向量。例:如果x取值是k个值中的第三个,则表示为:
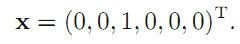
注意,x向量中的1只能有1个,体会一下他的实际意义,这样才能代表K个离散的值。
所以对某个特定的x出现的概率可以表示为:
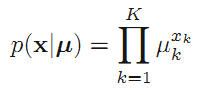
其中 ,对应x向量中每一个位置上出现1的概率。
,对应x向量中每一个位置上出现1的概率。
期望为:(由于x是个向量,所以其每个位置上都有期望,所以期望也是个向量,这都很直观的)
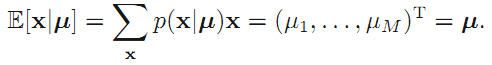
插一句,这种问题的一般思考流程:
1、确定单个x出现的概率p(x|u);
2、给定观察序列D,找出p(D|u)的表达式;
3、找到让这个p(D|u)最大的u,一般方法有取ln再求导,令其导数等于0,如果要normalize需要额外处理(比如引入拉格朗日子);
4、知道p(D|u)后,求在N个样本中,出现各种可能的的x的概率,即分布。
按照上述流程
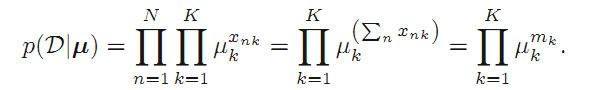
找最大的u,对p(D|u)取对数,再引入拉格朗日乘子得到:
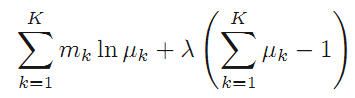
需要让这个式子取最大值,求导令导数为0得到:
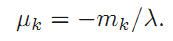
有因为需要normalize,故 ,最后得到:
,最后得到:
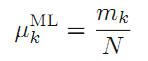
再求在N个样本中,出现各种可能的的x的概率,即分布。:(这是典型的概率问题了,单一情况概率*情况数)
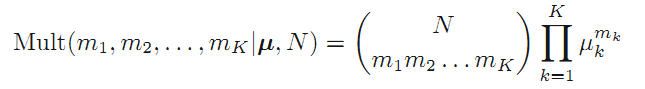
其中:

2.2.1 The Dirichlet distribution
这章与前一节真的很像,而且仔细对比一下可以发现一些有趣的东西。
还是老道理,需要为那个概率{u}引入一个prior distribution,而不再是算出来的单一固定的值。
为了共轭性,确定了prior分布的形式是:
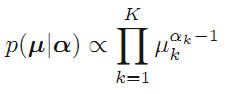
这就解释了为什么会有那些分布,不是凭空想象出来的,而是针对不同的情况,为了满足共轭性而构造出来的!
另外为了保证这些分布的性能,要有参数来调控。a1,a2,...,ak就是参数。
normalize一下,分布变成:
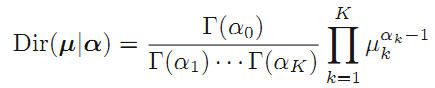
这个分布称作Dirichlet distribution
当然u不应该只有a确定,还应该与观测数据D有关,利用概率的规则与前面推导出的公式得:
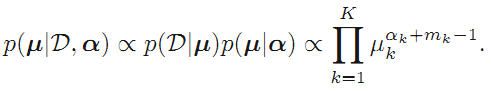
最终形式: