Show and Tell Lessons learned from the 2015 MSCOCO Image Captioning Challenge论文及tensorflow源码解读
- Show and Tell Lessons learned from the 2015 MSCOCO Image Captioning Challenge论文及tensorflow源码解读
- 论文
- 1 Model Overview
- 文章目的
- Model
- Image decoder
- LSTM based Sentence Generator
- Inference
- Evalution
- 1 Model Overview
- Source code
- 1 数据预处理
- 1 build_model
- 11 build_inputs
- 论文
Show and Tell Lessons learned from the 2015 MSCOCO Image Captioning Challenge论文及tensorflow源码解读
1 论文
“Show and Tell: Lessons learned from the 2015 MSCOCO Image Captioning Challenge.”
Full text available at: http://arxiv.org/abs/1609.06647
1.1 Model Overview
文章目的
用英文来描述图片内容
Indeed, a description must capture not only the objects contained in an image, but it also must express how these objects relate to each other as well as their attributes and the activities they are involved in. Moreover, the above semantic knowledge has to be expressed in a natural language like English, which means that a language model is needed in addition to visual understanding.
最大化 p(S|I) , Si 代表句子中单词, I 代表图片(image)
本质:
sequence to sequence learning
Model
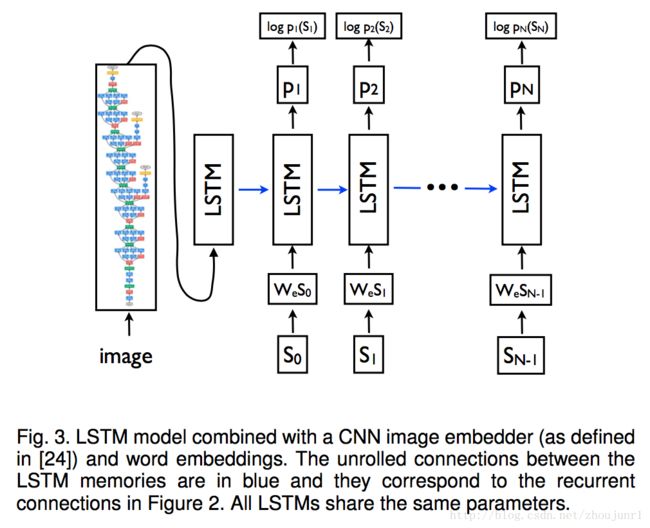
概述:通过CNN提取图片特征,使用LSTM在每一个时间点产生一个word
目标函数:
θ∗=argmaxθ∑(I,S)logp(S|I,θ)
where θ are the parameters of our model, I is an image, and S its correct transcription
由于 S 长度不固定,使用下式
logp(S|I)=∑Nt=0logp(St|I,S0,S1,...,St−1)
文章中使用RNN来对 p 建模
where the variable number of words we condition upon up to t−1 is expressed by a fixed length hidden state or memory ht . This memory is updated after seeing a new input xt by using a non-linear function f :
ht+1=f(ht,xt)
其中:使用LSTM作为 f , 使用CNN来提取image特征
1. Image decoder
NIC – Neural Image Caption
use a CNN as an image “encoder”, by first pre-training it for an image classification task and using the last hidden layer as an input to the RNN decoder that generates sentences
使用用于图像分类的CNN网络输出的特征,作为RNN decoder的输入,RNN用于产生句子
2. LSTM based Sentence Generator
LSTM可以暂时理解为一个黑箱模型,它通过输入的图片特征和在当前时刻输入的word,计算下一时刻每个word的概率,以此作为依据产生下一个word

其中We是一个embedding模型,作用就是将一个word表示为一个维度固定的实数向量
文中说:
We empirically verified that feeding the image at each time step as an extra input yields inferior results, as the network can explicitly exploit noise in the image and overfits more easily.
所以将 I 作为时刻 -1 点输入
Loss funciton:
L(I,S)=−∑Nt=1logpt(St)
3. Inference
最后,在训练结束后,如何产生一个句子呢,文中提出了两种方法:Sampling, BeamSearch
Sampling: where we just sample the first word according to p1, then provide the corresponding embedding as input and sample p2, continuing like this until we sample the special end-of-sentence token or some maximum length.
BeamSearch:iteratively consider the set of the k best sentences up to time t as candidates to generate sentences of size t + 1, and keep only the resulting best k of them. This better approximates S = argmaxS′ p(S′|I). We used the BeamSearch approach in the following experi- ments, with a beam of size 20.
4. Evalution
最后的最后,Evalution
…
..
.
2. Source code
源代码的解读顺序按照train.py的顺序,在train之前首先要下载数据。
https://github.com/tensorflow/models/tree/master/im2txt
可以直接运行以下代码,需要150G的空间。。。
其实数据并没有150G,只是在预处理的时候增加了很多。因为每个caption都等于一个图片。
# Location to save the MSCOCO data.
MSCOCO_DIR="${HOME}/im2txt/data/mscoco"
# Build the preprocessing script.
cd tensorflow-models/im2txt
bazel build //im2txt:download_and_preprocess_mscoco
# Run the preprocessing script.
bazel-bin/im2txt/download_and_preprocess_mscoco "${MSCOCO_DIR}"这部分按照源代码中 train.py 中的 main 的过程分析代码
在测试代码前,首先要做一些准备工作。
下载数据
参考源代码 /im2txt/im2txt/data/download_and_preprocess_mscoco.sh
在浏览器中输入 http://msvocds.blob.core.windows.net/coco2014/train2014.zip
下载训练数据
将train改为val,可以下载训练数据
Download the captions.
BASE_CAPTIONS_URL=”http://msvocds.blob.core.windows.net/annotations-1-0-3”
CAPTIONS_FILE=”captions_train-val2014.zip”
在浏览器输入对应url,下载caption,也就是描述图片的语句
captions 保存为json格式,e.g. {“image_id”: 511179, “id”: 829447, “caption”: “A group of people sitting at a dining table.”}
接下来是对下载的图片和文字进行预处理
This script converts the combined MSCOCO data into sharded data files consisting
of 256, 4 and 8 TFRecord files, respectively
Each TFRecord file contains ~2300 records. Each record within the TFRecord file
is a serialized SequenceExample proto consisting of precisely one image-caption
pair. Note that each image has multiple captions (usually 5) and therefore each
image is replicated multiple times in the TFRecord files.
The SequenceExample proto contains the following fields:
context:
image/image_id: integer MSCOCO image identifier
image/data: string containing JPEG encoded image in RGB colorspace
feature_lists:
image/caption: list of strings containing the (tokenized) caption words
image/caption_ids: list of integer ids corresponding to the caption word
具体的代码细节可以参考文件 /im2txt/im2txt/data/build_mscoco_data.py
下载Inception v3 Check Point
2.1 数据预处理
数据的预处理
用
代替未知 用
代替起始用代替结束
将数据转化为TFRecord文件
with tf.gfile.FastGFile(captions_file, "r") as f:
caption_data = json.load(f)
for image_id, base_filename in id_to_filename:
filename = os.path.join(image_dir, base_filename)
captions = [_process_caption(c) for c in id_to_captions[image_id]]
image_metadata.append(ImageMetadata(image_id, filename, captions))
num_captions += len(captions)ImageMetadata定义如下:
ImageMetadata = namedtuple("ImageMetadata",
["image_id", "filename", "captions"])使用 tf.image.decode_jpeg 将一个 JPEG-encoded image 转换为一个 uint8 tensor.
class ImageDecoder(object):
"""Helper class for decoding images in TensorFlow."""
def __init__(self):
# Create a single TensorFlow Session for all image decoding calls.
self._sess = tf.Session()
# TensorFlow ops for JPEG decoding.
self._encoded_jpeg = tf.placeholder(dtype=tf.string)
self._decode_jpeg = tf.image.decode_jpeg(self._encoded_jpeg, channels=3)
def decode_jpeg(self, encoded_jpeg):
image = self._sess.run(self._decode_jpeg,
feed_dict={self._encoded_jpeg: encoded_jpeg})
assert len(image.shape) == 3
assert image.shape[2] == 3
return imageThis script converts the combined MSCOCO data into sharded data files consisting
of 256, 4 and 8 TFRecord files, respectively:
output_dir/train-00000-of-00256
output_dir/train-00001-of-00256
…
output_dir/train-00255-of-00256
and
output_dir/val-00000-of-00004
…
output_dir/val-00003-of-00004
and
output_dir/test-00000-of-00008
…
output_dir/test-00007-of-00008
Each TFRecord file contains ~2300 records. Each record within the TFRecord file
is a serialized SequenceExample proto consisting of precisely one image-caption
pair. Note that each image has multiple captions (usually 5) and therefore each
image is replicated multiple times in the TFRecord files.
2.1 build_model
通过预处理,我们将图片以及caption保存下来到指定的文件名,接下来是建立模型。tensorflow首先需要建立graph
g = tf.Graph()
with g.as_default():
# Build the model.
model = show_and_tell_model.ShowAndTellModel(
model_config, mode="train", train_inception=FLAGS.train_inception)
model.build()model.build()分以下几个操作
def build(self):
"""Creates all ops for training and evaluation."""
self.build_inputs()
self.build_image_embeddings()
self.build_seq_embeddings()
self.build_model()
self.setup_inception_initializer()
self.setup_global_step()所有的操作都是在model类上
2.1.1 build_inputs
build_inputs就是将数据读入的过程。prefetching, preprocessing and batching.
Prefetch:
tf.gfile.Glob(pattern)
返回所有符合pattern的文件名的列表。
filename_queue = tf.train.string_input_producer(
data_files, shuffle=True, capacity=16, name=shard_queue_name)将列表变为一个queue。
values_queue = tf.RandomShuffleQueue(
capacity=capacity,
min_after_dequeue=min_queue_examples,
dtypes=[tf.string],
name="random_" + value_queue_name)来创建一个queue。
enqueue_ops = []
for _ in range(num_reader_threads):
# filename_queue -- list for path_names type:string
_, value = reader.read(filename_queue)
# a enqueue op for values_queue
enqueue_ops.append(values_queue.enqueue([value]))创建enqueue操作,提供给上面的用randomshufflequeue创建的queue。
最终prefetch返回上面创建的queue,里面是filename_queue
接下来通过上面返回的queue,通过dequeue方法可以返回一个serialized_sequence_example。
将它的encoded_image, caption提取出来,通过以下函数处理:
image = self.process_image(encoded_image, thread_id=thread_id)
# 并添加到列表中用于返回
images_and_captions.append([image, caption])process_image:Decode an image, resize and apply random distortions. 还加入了summary
最后有一个batch_with_dynamic_pad
def batch_with_dynamic_pad(images_and_captions,
batch_size,
queue_capacity,
add_summaries=True):
"""Batches input images and captions.
This function splits the caption into an input sequence and a target sequence,
where the target sequence is the input sequence right-shifted by 1. Input and
target sequences are batched and padded up to the maximum length of sequences
in the batch. A mask is created to distinguish real words from padding words.剩下的留在下一篇博客