【大数据技术】Spark MLlib机器学习协同过滤电影推荐实战(附源码和数据集)
需要源码和数据集请点赞关注收藏后评论区留言私信~~~
协同过滤————电影推荐
协同过滤是利用大量已有的用户偏好来估计用户对其未接触过的物品的喜好程度。在协同过滤算法中有着两个分支,分别是基于群体用户的协同过滤(UserCF)和基于物品的协同过滤(ItemCF)。
在电影推荐系统中,通常分为针对用户推荐电影和针对电影推荐用户两种方式。若采用基于用户的推荐模型,则会利用相似用户的评级来计算对某个用户的推荐。若采用基于电影的推荐模型,则会依靠用户接触过的电影与候选电影之间的相似度来获得推荐。
在Spark MLlib实现了交替最小二乘(ALS)算法,它是机器学习的协同过滤式推荐算法,机器学习的协同过滤式推荐算法是通过观察所有用户给产品的评分来推断每个用户的喜好,并向用户推荐合适的产品
1:下载数据集
数据集网址
2:建立Scala类
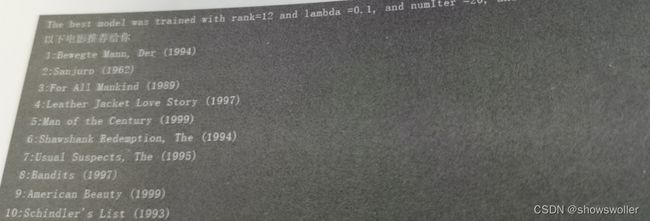
推荐结果如下
部分代码如下 全部代码请点赞关注收藏后评论区留言私信
import java.util.Random
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.rdd._
import org.apache.spark.mllib.recommendation.{ALS, Rating, MatrixFactorizationModel}
object MovieRecomment {
def main(args: Array[String]): Unit = {
//建立spark环境
// val conf = new SparkConf().setAppName("movieRecomment")
val conf = new SparkConf().setAppName("MovieLensALS").setMaster("local[4]")
val sc = new SparkContext(conf)
sc.setLogLevel("error")
//装载样本评分数据,其中最后一列Timestamp取除10的余数作为key,Rating为值,即(Int,Rating)
val ratings = sc.textFile("ratings.dat").map {
line =>
val fields = line.split("::")
//时间戳、用户编号、电影编号、评分
(fields(3).toLong % 10, Rating(fields(0).toInt, fields(1).toInt, fields(2).toDouble))
}
ratings.take(10).foreach { println }
// 装载电影目录对照表(电影ID->电影标题)
val movies = sc.textFile("movies.dat").map { line =>
val fields = line.split("::")
(fields(0).toInt, fields(1))
}.collect.toMap
//记录样本评分数、用户数、电影数
val numRatings = ratings.count
val numUsers = ratings.map(_._2.user).distinct.count
val numMovies = ratings.map(_._2.product).distinct.count
println("从" + numRatings + "记录中" + "分析了" + numUsers + "的人观看了" + numMovies + "部电影")
//提取一个得到最多评分的电影子集(电影编号),以便进行评分启发
//矩阵最为密集的部分
val mostRatedMovieIds = ratings.map(_._2.product)
.countByValue()
.toSeq
.sortBy(-_._2)
.take(50) //取前50个
.map(_._1) //获取他们的id
val random = new Random(0)
//从目前最火的电影中随机获取十部电影
val selectedMovies = mostRatedMovieIds.filter(
x => random.nextDouble() < 0.2).map(x => (x, movies(x))).toSeq
//调用函数 elicitateRatings,引导或者启发评论,让用户打分
val myRatings = elicitateRatings(selectedMovies)
val myRatingsRDD = sc.parallelize(myRatings)
//将评分数据分成训练集60%,验证集20%,测试集20%
val numPartitions = 20
//训练集
val training = ratings.filter(x => x._1 < 6).values
.union(myRatingsRDD).repartition(numPartitions)
.persist
//验证集
val validation = ratings.filter(x => x._1 >= 6 && x._1 < 8).values
.repartition(numPartitions).persist
//测试集
val test = ratings.filter(x => x._1 >= 8).values.persist
val numTraining = training.count
val numValidation = validation.count
val numTest = test.count
println("训练集数量:" + numTraining + ",验证集数量: " + numValidation + ", 测试集数量:" + numTest)
//训练模型,并且在验证集上评估模型
//模型中隐藏因子数
val ranks = List(8, 12)
//正则项的惩罚系数
val lambdas = List(0.1, 10.0)
//循环次数
val numIters = List(10, 20)
var bestModel: Option[MatrixFactorizationModel] = None
var bestValidationRmse = Double.MaxValue
var bestRank = 0
var bestLambda = -1.0
var bestNumIter = -1
for (rank <- ranks; lambda <- lambdas; numIter <- numIters) {
val model = ALS.train(training, rank, numIter, lambda)
val validationRmse = computeRmse(model, validation, numValidation)
println("RMSE (validation)=" + validationRmse + "for the model trained with rand =" + rank + ", lambda=" + lambda + ", and numIter= " + numIter + ".")
if (validationRmse < bestValidationRmse) {
bestModel = Some(model)
bestValidationRmse = validationRmse
bestRank = rank
bestLambda = lambda
bestNumIter = numIter
}
}
//在测试集中 获得最佳模型
val testRmse = computeRmse(bestModel.get, test, numTest)
println("The best model was trained with rank=" + bestRank + " and lambda =" + bestLambda + ", and numIter =" + bestNumIter + ", and itsRMSE on the test set is" + testRmse + ".")
//产生个性化推荐
val myRateMoviesIds = myRatings.map(_.product).toSet
val candidates = sc.parallelize(movies.keys.filter(!myRateMoviesIds.contains(_)).toSeq)
val recommendations = bestModel.get.predict(candidates.map((0, _)))
.collect()
.sortBy((-_.rating))
.take(10)
var i = 1
println("以下电影推荐给你")
recommendations.foreach { r =>
println("%2d".format(i) + ":" + movies(r.product))
i += 1
}
}
/**计算 均方根误差RMSE */
def computeRmse(model: MatrixFactorizationModel, data: RDD[Rating], n: Long) = {
val predictions: RDD[Rating] = model.predict(data.map(x => (x.user, x.product)))
val predictionsAndRatings = predictions.map(x => ((x.user, x.product), x.rating))
.join(data.map(x => ((x.user, x.product), x.rating)))
.values
math.sqrt(predictionsAndRatings.map(x => (x._1 - x._2) * (x._1 - x._2)).reduce(_ + _) / n)
}
/** 从命令行获取用户电影评级. */
def elicitateRatings(movies: Seq[(Int, String)]) = {
val prompt = "给以下电影评分(1——5分)"
println(prompt)
val ratings = movies.flatMap { x =>
var rating: Option[Rating] = None
var valid = false
while (!valid) {
print(x._2 + ": ")
try {
val r = Console.readInt
if (r < 0 || r > 5) {
println(prompt)
} else {
valid = true
if (r > 0) {
rating = Some(Rating(0, x._1, r))
}
}
} catch {
case e: Exception => println(prompt)
}
}
rating match {
case Some(r) => Iterator(r)
case None => Iterator.empty
}
}
if (ratings.isEmpty) {
error("No rating provided!")
} else {
ratings
}
}
}创作不易 觉得有帮助请点赞关注收藏~~~