T5 的尝试
T5论文介绍:Transformer T5 模型慢慢读_冬炫的博客-CSDN博客
0 背景
1.出错位置:self.hparams = hparams 改为 self.save_hyperparameters(hparams)
2.xm 包属于torch_xla 这个包是关于TPU 直接手动屏蔽语句。
3.我的是python39 其实很多是pytorch_lightning 的版本问题。所以....可以换版本去解决下面问题,我就直接用新的版本。
checkpoint_callback = pl.callbacks.ModelCheckpoint(
dirpath=args.output_dir, monitor="val_loss", mode="min", save_top_k=5#prefix="checkpoint",
)
4. 关于:amp_level
![]()
可以屏蔽amp_level 参数
或者 Trainer(amp_backend='apex', amp_level='O2') 传入的参数有设置amp_backend='apex'
5. TypeError: forward() got an unexpected keyword argument 'lm_labels'
return self.model(
input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,
decoder_attention_mask=decoder_attention_mask,
labels=lm_labels,#lm_labels
) 6. 将proc_rank改为global_rank

7.TypeError: optimizer_step() got an unexpected keyword argument 'on_tpu'TypeError: optimizer_step() got an unexpected keyword argument 'on_tpu' · Issue #5326 · Lightning-AI/lightning · GitHub
#def optimizer_step(self, epoch, batch_idx, optimizer, optimizer_idx, second_order_closure=None):
def optimizer_step(self,
epoch=None,
batch_idx=None,
optimizer=None,
optimizer_idx=None,
optimizer_closure=None,
on_tpu=None,
using_native_amp=None,
using_lbfgs=None):
#if self.trainer.use_tpu:
# xm.optimizer_step(optimizer)
#else:
optimizer.step(closure=optimizer_closure)
optimizer.zero_grad()
self.lr_scheduler.step()7.调试参考链接:
【1】
https://github.com/Lightning-AI/lightning/discussions/7525
【2】
“简约版”Pytorch —— Pytorch-Lightning详解_@YangZai的博客-CSDN博客_pytorch-lightning
【3】
huggingface/transformers: Transformers v4.0.0: Fast tokenizers, model outputs, file reorganization | Zenodo
exploring-T5/t5_fine_tuning.ipynb at master · patil-suraj/exploring-T5 · GitHub
1. 导入包
import argparse
import glob
import os
import json
import time
import logging
import random
import re
from itertools import chain
from string import punctuation
import nltk
nltk.download('punkt')
from nltk.tokenize import sent_tokenize
import pandas as pd
import numpy as np
import torch
from torch.utils.data import Dataset, DataLoader
import pytorch_lightning as pl
from transformers import (
AdamW,
T5ForConditionalGeneration,
T5Tokenizer,
get_linear_schedule_with_warmup
)
def set_seed(seed):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed_all(seed)
set_seed(42)2.微调功能
class T5FineTuner(pl.LightningModule):
def __init__(self, hparams):
super(T5FineTuner, self).__init__()
self.hparams = hparams
self.model = T5ForConditionalGeneration.from_pretrained(hparams.model_name_or_path)
self.tokenizer = T5Tokenizer.from_pretrained(hparams.tokenizer_name_or_path)
def is_logger(self):
return self.trainer.proc_rank <= 0
def forward(
self, input_ids, attention_mask=None, decoder_input_ids=None, decoder_attention_mask=None, lm_labels=None
):
return self.model(
input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,
decoder_attention_mask=decoder_attention_mask,
lm_labels=lm_labels,
)
def _step(self, batch):
lm_labels = batch["target_ids"]
lm_labels[lm_labels[:, :] == self.tokenizer.pad_token_id] = -100
outputs = self(
input_ids=batch["source_ids"],
attention_mask=batch["source_mask"],
lm_labels=lm_labels,
decoder_attention_mask=batch['target_mask']
)
loss = outputs[0]
return loss
def training_step(self, batch, batch_idx):
loss = self._step(batch)
tensorboard_logs = {"train_loss": loss}
return {"loss": loss, "log": tensorboard_logs}
def training_epoch_end(self, outputs):
avg_train_loss = torch.stack([x["loss"] for x in outputs]).mean()
tensorboard_logs = {"avg_train_loss": avg_train_loss}
return {"avg_train_loss": avg_train_loss, "log": tensorboard_logs, 'progress_bar': tensorboard_logs}
def validation_step(self, batch, batch_idx):
loss = self._step(batch)
return {"val_loss": loss}
def validation_epoch_end(self, outputs):
avg_loss = torch.stack([x["val_loss"] for x in outputs]).mean()
tensorboard_logs = {"val_loss": avg_loss}
return {"avg_val_loss": avg_loss, "log": tensorboard_logs, 'progress_bar': tensorboard_logs}
def configure_optimizers(self):
"Prepare optimizer and schedule (linear warmup and decay)"
model = self.model
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": self.hparams.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
optimizer = AdamW(optimizer_grouped_parameters, lr=self.hparams.learning_rate, eps=self.hparams.adam_epsilon)
self.opt = optimizer
return [optimizer]
def optimizer_step(self, epoch, batch_idx, optimizer, optimizer_idx, second_order_closure=None):
if self.trainer.use_tpu:
xm.optimizer_step(optimizer)
else:
optimizer.step()
optimizer.zero_grad()
self.lr_scheduler.step()
def get_tqdm_dict(self):
tqdm_dict = {"loss": "{:.3f}".format(self.trainer.avg_loss), "lr": self.lr_scheduler.get_last_lr()[-1]}
return tqdm_dict
def train_dataloader(self):
train_dataset = get_dataset(tokenizer=self.tokenizer, type_path="train", args=self.hparams)
dataloader = DataLoader(train_dataset, batch_size=self.hparams.train_batch_size, drop_last=True, shuffle=True, num_workers=4)
t_total = (
(len(dataloader.dataset) // (self.hparams.train_batch_size * max(1, self.hparams.n_gpu)))
// self.hparams.gradient_accumulation_steps
* float(self.hparams.num_train_epochs)
)
scheduler = get_linear_schedule_with_warmup(
self.opt, num_warmup_steps=self.hparams.warmup_steps, num_training_steps=t_total
)
self.lr_scheduler = scheduler
return dataloader
def val_dataloader(self):
val_dataset = get_dataset(tokenizer=self.tokenizer, type_path="val", args=self.hparams)
return DataLoader(val_dataset, batch_size=self.hparams.eval_batch_size, num_workers=4)logger = logging.getLogger(__name__)
class LoggingCallback(pl.Callback):
def on_validation_end(self, trainer, pl_module):
logger.info("***** Validation results *****")
if pl_module.is_logger():
metrics = trainer.callback_metrics
# Log results
for key in sorted(metrics):
if key not in ["log", "progress_bar"]:
logger.info("{} = {}\n".format(key, str(metrics[key])))
def on_test_end(self, trainer, pl_module):
logger.info("***** Test results *****")
if pl_module.is_logger():
metrics = trainer.callback_metrics
# Log and save results to file
output_test_results_file = os.path.join(pl_module.hparams.output_dir, "test_results.txt")
with open(output_test_results_file, "w") as writer:
for key in sorted(metrics):
if key not in ["log", "progress_bar"]:
logger.info("{} = {}\n".format(key, str(metrics[key])))
writer.write("{} = {}\n".format(key, str(metrics[key])))3.参数列表(data dir 与 ouput dir 根据文件位置修改)
args_dict = dict(
data_dir="", # path for data files
output_dir="", # path to save the checkpoints
model_name_or_path='t5-base',
tokenizer_name_or_path='t5-base',
max_seq_length=512,
learning_rate=3e-4,
weight_decay=0.0,
adam_epsilon=1e-8,
warmup_steps=0,
train_batch_size=8,
eval_batch_size=8,
num_train_epochs=2,
gradient_accumulation_steps=16,
n_gpu=1,
early_stop_callback=False,
fp_16=False, # if you want to enable 16-bit training then install apex and set this to true
opt_level='O1', # you can find out more on optimisation levels here https://nvidia.github.io/apex/amp.html#opt-levels-and-properties
max_grad_norm=1.0, # if you enable 16-bit training then set this to a sensible value, 0.5 is a good default
seed=42,
)4.下面进入各种github 主的各类NLP 任务
IMDB review classification
!wget https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz !tar -xvf aclImdb_v1.tar.gz
train_pos_files = glob.glob('aclImdb/train/pos/*.txt')
train_neg_files = glob.glob('aclImdb/train/neg/*.txt')
random.shuffle(train_pos_files)
random.shuffle(train_neg_files)
val_pos_files = train_pos_files[:1000]
val_neg_files = train_neg_files[:1000]
import shutil
for f in val_pos_files:
shutil.move(f, 'aclImdb/val/pos')
for f in val_neg_files:
shutil.move(f, 'aclImdb/val/neg')上面是下载一种Imdb 评价级,总共两种评价,积极与消极。但数据集只有tran 和test 。此处代码抽离1000个文段,组成val 数据集 。
该文档没什么特殊之处
This film is a good example of how through media manipulation you can sell a film that is no more than a very unfunny TV sitcom. In Puerto Rico the daily newspaper with the widest circulation has continuously written about the marvels of this film, almost silencing all others. Coincidentally the newspaper with the second largest circulation belongs to the same owners. The weekly CLARIDAD is the only newspaper on the island that has analyzed the film's form and content, and pointed out all its flaws, clich茅s, and bad writing.
Just because a film makes a portion of the audience laugh with easy and obvious jokes, and because one can recognize actors and scenery, does not make it an acceptable film.

Prepare Dataset
#tokenizer = T5Tokenizer.from_pretrained('t5-base')
tokenizer = T5Tokenizer.from_pretrained('t5-small')
# 尝试tokenizer 功能
ids_neg = tokenizer.encode('negative ')
ids_pos = tokenizer.encode('positive ')
len(ids_neg), len(ids_pos)
将下载的数据打包成T5所能接受的形式,这里github主说不需要任何前缀词,只需要原文+ 形式即可。且下面将文中的标点符号等进行预处理。
最终输入到self.tokenizer.batch_encode_plus()函数中,我猜测是可以自己生成id 号,适合get_item 函数的调用,而且将英文字母按照词典转换成token id。这样的话T5 的文件输入形式还是很自由。如果很短的话,一个文件,分行代表例子,就可以轻松描述出来。
class ImdbDataset(Dataset):
def __init__(self, tokenizer, data_dir, type_path, max_len=512):
self.pos_file_path = os.path.join(data_dir, type_path, 'pos')
self.neg_file_path = os.path.join(data_dir, type_path, 'neg')
self.pos_files = glob.glob("%s/*.txt" % self.pos_file_path)
self.neg_files = glob.glob("%s/*.txt" % self.neg_file_path)
self.max_len = max_len
self.tokenizer = tokenizer
self.inputs = []
self.targets = []
self._build()
def __len__(self):
return len(self.inputs)
def __getitem__(self, index):
source_ids = self.inputs[index]["input_ids"].squeeze()
target_ids = self.targets[index]["input_ids"].squeeze()
src_mask = self.inputs[index]["attention_mask"].squeeze() # might need to squeeze
target_mask = self.targets[index]["attention_mask"].squeeze() # might need to squeeze
return {"source_ids": source_ids, "source_mask": src_mask, "target_ids": target_ids, "target_mask": target_mask}
def _build(self):
self._buil_examples_from_files(self.pos_files, 'positive')
self._buil_examples_from_files(self.neg_files, 'negative')
def _buil_examples_from_files(self, files, sentiment):
REPLACE_NO_SPACE = re.compile("[.;:!\'?,\"()\[\]]")
REPLACE_WITH_SPACE = re.compile("(利用decode 函数可以将嵌入id变回英语。
dataset = ImdbDataset(tokenizer, 'aclImdb', 'val', max_len=512)
len(dataset)
data = dataset[28]
print(tokenizer.decode(data['source_ids']))
print(tokenizer.decode(data['target_ids']))Train
mkdir -p t5_imdb_sentiment
args_dict.update({'data_dir': 'aclImdb', 'output_dir': 't5_imdb_sentiment', 'num_train_epochs':2})
args = argparse.Namespace(**args_dict)
checkpoint_callback = pl.callbacks.ModelCheckpoint(
filepath=args.output_dir, prefix="checkpoint", monitor="val_loss", mode="min", save_top_k=5
)
train_params = dict(
accumulate_grad_batches=args.gradient_accumulation_steps,
gpus=args.n_gpu,
max_epochs=args.num_train_epochs,
early_stop_callback=False,
precision= 16 if args.fp_16 else 32,
amp_level=args.opt_level,
gradient_clip_val=args.max_grad_norm,
checkpoint_callback=checkpoint_callback,
callbacks=[LoggingCallback()],
)def get_dataset(tokenizer, type_path, args):
return ImdbDataset(tokenizer=tokenizer, data_dir=args.data_dir, type_path=type_path, max_len=args.max_seq_length)
model = T5FineTuner(args)
trainer = pl.Trainer(**train_params)
trainer.fit(model)
model.model.save_pretrained('t5_base_imdb_sentiment')结果截图

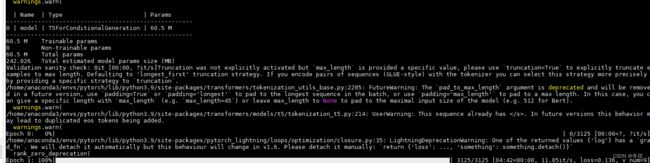
Eval
1.报错num_samples:shuffle =False
2. iter() next 函数用不习惯,报错
for i in range(1):
for batch in loader:
print(batch["source_ids"].shape)
break3. 加载上述训练好的模型
model = T5FineTuner(args).cuda()
state_dict = torch.load(pytorch_model.bin 文件位置)
#发现与应该加入的key 少了一个model. 的前缀
model.load_state_dict({("model."+k):v for k,v in state_dict.items()})4.代码片段
import textwrap
from tqdm.auto import tqdm
from sklearn import metrics
dataset = ImdbDataset(tokenizer, 'aclImdb', 'test', max_len=512)
loader = DataLoader(dataset, batch_size=32, shuffle=True)
it = iter(loader)
batch = next(it)
batch["source_ids"].shape
outs = model.model.generate(input_ids=batch['source_ids'].cuda(),
attention_mask=batch['source_mask'].cuda(),
max_length=2)
dec = [tokenizer.decode(ids) for ids in outs]
texts = [tokenizer.decode(ids) for ids in batch['source_ids']]
targets = [tokenizer.decode(ids) for ids in batch['target_ids']]
for i in range(32):
lines = textwrap.wrap("Review:\n%s\n" % texts[i], width=100)
print("\n".join(lines))
print("\nActual sentiment: %s" % targets[i])
print("Predicted sentiment: %s" % dec[i])
print("=====================================================================\n")调试参考链接:
pytorch报错:ValueError: num_samples should be a positive integer value, but got num_samples=0_不起名就没有名吗的博客-CSDN博客
torch的模型保存和加载各种细节各种坑尤其是多GPU训练会出现各种问题 - 百度文库
结果截图
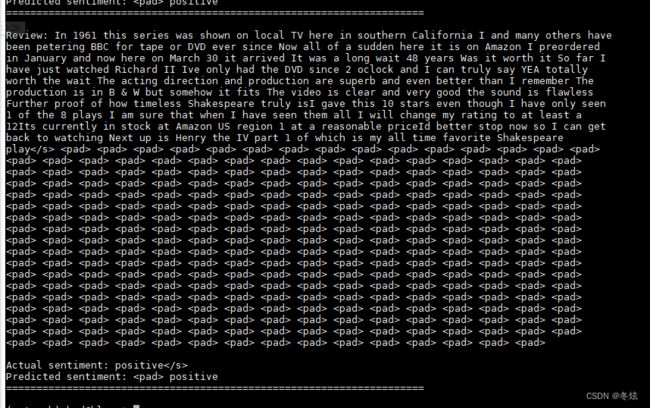
5.测试准确率输出
loader = DataLoader(dataset, batch_size=32, num_workers=4)
model.model.eval()
outputs = []
targets = []
for batch in tqdm(loader):
outs = model.model.generate(input_ids=batch['source_ids'].cuda(),
attention_mask=batch['source_mask'].cuda(),
max_length=2)
dec = [tokenizer.decode(ids) for ids in outs]
target = [tokenizer.decode(ids) for ids in batch["target_ids"]]
outputs.extend(dec)
targets.extend(target)for i, out in enumerate(outputs):
if out not in ['positive', 'negative']:
print(i, 'detected invalid prediction')
metrics.accuracy_score(targets, outputs)
print(metrics.classification_report(targets, outputs))但是生成的预测格式奇怪,就像上面的截图
for i, out in enumerate(outputs):
if out == ' positive':
outputs[i] = 'positive'#print(i, 'detected invalid prediction')
else:
outputs[i] = 'negative' 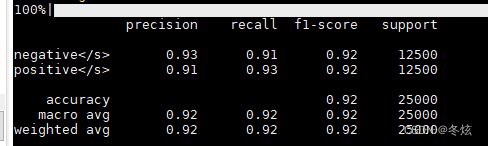
上面的实验都在small 版本的T5模型的结果
