目标检测6--NanodetPlus算法分析
文章目录
-
- 1.简介
- 2.辅助训练模块Assign Guidance Module
- 3.损失函数
- 4.标签匹配策略
- 5.后处理介绍
- 6.特征融合
- 参考资料
欢迎访问个人网络日志知行空间
1.简介
NanoDet是上海人工智能实验室的RangiLyu于2020年10月份开源的轻量级检测项目,取得了很好的效果,广受关注。2021年12月份,作者又更新发布了NanoDetPlus,在coco val上的map提升了7个百分点。
2.辅助训练模块Assign Guidance Module
Nanodet Plus的检测头只使用了2个深度可分离卷积以减少模型的参数,但同时也导致其学习能力有限,对于从零开始学习预测分类和标签
匹配有一定困难。作者使用了同WACV上一篇paperLAD:Improving Object Detection by Label Assignment Distillation一样的做法,通过教师学生模型训练多了一个网络来引导NanodetPlus检测头的训练,同知识蒸馏的思想。

在Nanodet Plus中,辅助训练模块在整个网络中组成中的所占的部分如下图:
https://zhuanlan.zhihu.com/p/449912627

辅助训练模块和物体的检测头使用共同的backbone提取出特征,并复制一份检测头的PAFPN作为bottleneck,最后接比检测头要大的多的模块作为检测头。其配置为:
head:
name: NanoDetPlusHead
num_classes: 80
input_channel: 96
feat_channels: 96
stacked_convs: 2
kernel_size: 5
strides: [8, 16, 32, 64]
activation: LeakyReLU
reg_max: 7
norm_cfg:
type: BN
# Auxiliary head, only use in training time.
aux_head:
name: SimpleConvHead
num_classes: 80
input_channel: 192
feat_channels: 192
stacked_convs: 4
strides: [8, 16, 32, 64]
activation: LeakyReLU
reg_max: 7
可以看到检测头head中feat_channels: 96, stacked_convs: 2,辅助训练检测头aux_head中feat_channels: 192, stacked_convs: 4,且检测头中使用的还是深度可分离卷积,因此参数比辅助训练头少很多,因此辅助训练头的学习能力更强。辅助训练分支只在网络的训练过程中起作用,训练时,backbone输出的特征同时送入检测分支和辅助训练分支,因辅助训练分支有更多的参数,故其更容易从初始状态学习判断如何划分正负样本并实现标签匹配。辅助训练分支和检测分支的输出是相同维度的预测框和类别数,因辅助训练分支训练学习的更快更好,因此可以使用辅助训练分支预测框输出结果来做标签匹配,将匹配的结果当成检测分支预测框的匹配结果来计算训练loss。
在nanodet_plus.py文件foward_train方法中,可以看到前向推理同时计算了aux_head和head,且把aux_head的输出送到了loss函数中。
# in nanodet_plus.py
def forward_train(self, gt_meta):
img = gt_meta["img"]
feat = self.backbone(img)
fpn_feat = self.fpn(feat)
if self.epoch >= self.detach_epoch:
aux_fpn_feat = self.aux_fpn([f.detach() for f in feat])
dual_fpn_feat = (
torch.cat([f.detach(), aux_f], dim=1)
for f, aux_f in zip(fpn_feat, aux_fpn_feat)
)
else:
aux_fpn_feat = self.aux_fpn(feat)
dual_fpn_feat = (
torch.cat([f, aux_f], dim=1) for f, aux_f in zip(fpn_feat, aux_fpn_feat)
)
head_out = self.head(fpn_feat)
aux_head_out = self.aux_head(dual_fpn_feat)
loss, loss_states = self.head.loss(head_out, gt_meta, aux_preds=aux_head_out)
return head_out, loss, loss_states
3.损失函数
Nanodet Plus参考了Generalized Focal Loss中的Distributed Bounding Boxes方法,在特征图尺度上回归检测框距特征grid cell中心距离时,采用离散化的方法,将回归范围分成特征图尺度上的reg_max份,并计算落在0,1,...,reg_max上的概率。因此Nanodet Plus除了检测的分类和box IoU损失外,还加多了一个DistributionFocalLoss。类别评价使用的是QualityFocalLoss,box评价使用的是Generalized Intersection over Union,GIoU。
# in nanodet_plus_head.py
class NanoDetPlusHead:
...
def _get_loss_from_assign(self, cls_preds, reg_preds, decoded_bboxes, assign):
device = cls_preds.device
labels, label_scores, bbox_targets, dist_targets, num_pos = assign
num_total_samples = max(
reduce_mean(torch.tensor(sum(num_pos)).to(device)).item(), 1.0
)
labels = torch.cat(labels, dim=0)
label_scores = torch.cat(label_scores, dim=0)
bbox_targets = torch.cat(bbox_targets, dim=0)
cls_preds = cls_preds.reshape(-1, self.num_classes)
reg_preds = reg_preds.reshape(-1, 4 * (self.reg_max + 1))
decoded_bboxes = decoded_bboxes.reshape(-1, 4)
loss_qfl = self.loss_qfl(
cls_preds, (labels, label_scores), avg_factor=num_total_samples
)
pos_inds = torch.nonzero(
(labels >= 0) & (labels < self.num_classes), as_tuple=False
).squeeze(1)
if len(pos_inds) > 0:
weight_targets = cls_preds[pos_inds].detach().sigmoid().max(dim=1)[0]
bbox_avg_factor = max(reduce_mean(weight_targets.sum()).item(), 1.0)
loss_bbox = self.loss_bbox(
decoded_bboxes[pos_inds],
bbox_targets[pos_inds],
weight=weight_targets,
avg_factor=bbox_avg_factor,
)
dist_targets = torch.cat(dist_targets, dim=0)
loss_dfl = self.loss_dfl(
reg_preds[pos_inds].reshape(-1, self.reg_max + 1),
dist_targets[pos_inds].reshape(-1),
weight=weight_targets[:, None].expand(-1, 4).reshape(-1),
avg_factor=4.0 * bbox_avg_factor,
)
else:
loss_bbox = reg_preds.sum() * 0
loss_dfl = reg_preds.sum() * 0
loss = loss_qfl + loss_bbox + loss_dfl
loss_states = dict(loss_qfl=loss_qfl, loss_bbox=loss_bbox, loss_dfl=loss_dfl)
return loss, loss_states
def loss(self, preds, gt_meta, aux_preds=None):
"""Compute losses.
Args:
preds (Tensor): Prediction output.
gt_meta (dict): Ground truth information.
aux_preds (tuple[Tensor], optional): Auxiliary head prediction output.
Returns:
loss (Tensor): Loss tensor.
loss_states (dict): State dict of each loss.
"""
gt_bboxes = gt_meta["gt_bboxes"]
gt_labels = gt_meta["gt_labels"]
device = preds.device
batch_size = preds.shape[0]
input_height, input_width = gt_meta["img"].shape[2:]
featmap_sizes = [
(math.ceil(input_height / stride), math.ceil(input_width) / stride)
for stride in self.strides
]
# get grid cells of one image
mlvl_center_priors = [
self.get_single_level_center_priors(
batch_size,
featmap_sizes[i],
stride,
dtype=torch.float32,
device=device,
)
for i, stride in enumerate(self.strides)
]
center_priors = torch.cat(mlvl_center_priors, dim=1)
cls_preds, reg_preds = preds.split(
[self.num_classes, 4 * (self.reg_max + 1)], dim=-1
)
dis_preds = self.distribution_project(reg_preds) * center_priors[..., 2, None]
decoded_bboxes = distance2bbox(center_priors[..., :2], dis_preds)
if aux_preds is not None:
# use auxiliary head to assign
aux_cls_preds, aux_reg_preds = aux_preds.split(
[self.num_classes, 4 * (self.reg_max + 1)], dim=-1
)
aux_dis_preds = (
self.distribution_project(aux_reg_preds) * center_priors[..., 2, None]
)
aux_decoded_bboxes = distance2bbox(center_priors[..., :2], aux_dis_preds)
batch_assign_res = multi_apply(
self.target_assign_single_img,
aux_cls_preds.detach(),
center_priors,
aux_decoded_bboxes.detach(),
gt_bboxes,
gt_labels,
)
else:
# use self prediction to assign
batch_assign_res = multi_apply(
self.target_assign_single_img,
cls_preds.detach(),
center_priors,
decoded_bboxes.detach(),
gt_bboxes,
gt_labels,
)
loss, loss_states = self._get_loss_from_assign(
cls_preds, reg_preds, decoded_bboxes, batch_assign_res
)
if aux_preds is not None:
aux_loss, aux_loss_states = self._get_loss_from_assign(
aux_cls_preds, aux_reg_preds, aux_decoded_bboxes, batch_assign_res
)
loss = loss + aux_loss
for k, v in aux_loss_states.items():
loss_states["aux_" + k] = v
return loss, loss_states
DistributionFocalLoss的定义见工程gfocal_loss.py文件,通过box2distance转换得到的label是浮点数,而网络回归的标签是离散形的,故在计算DistributionFocalLoss时会计算取左边离散值和右边离散值当作target,并按距离给左右两个点来分配损失权重。
class DistributionFocalLoss
...
def forward(
self, pred, target, weight=None, avg_factor=None, reduction_override=None
):
"""Forward function.
Args:
pred (torch.Tensor): Predicted general distribution of bounding
boxes (before softmax) with shape (N, n+1), n is the max value
of the integral set `{0, ..., n}` in paper.
target (torch.Tensor): Target distance label for bounding boxes
with shape (N,).
weight (torch.Tensor, optional): The weight of loss for each
prediction. Defaults to None.
avg_factor (int, optional): Average factor that is used to average
the loss. Defaults to None.
reduction_override (str, optional): The reduction method used to
override the original reduction method of the loss.
Defaults to None.
"""
assert reduction_override in (None, "none", "mean", "sum")
reduction = reduction_override if reduction_override else self.reduction
loss_cls = self.loss_weight * distribution_focal_loss(
pred, target, weight, reduction=reduction, avg_factor=avg_factor
)
return loss_cls
def distribution_focal_loss(pred, label):
r"""Distribution Focal Loss (DFL) is from `Generalized Focal Loss: Learning
Qualified and Distributed Bounding Boxes for Dense Object Detection
`_.
Args:
pred (torch.Tensor): Predicted general distribution of bounding boxes
(before softmax) with shape (N, n+1), n is the max value of the
integral set `{0, ..., n}` in paper.
label (torch.Tensor): Target distance label for bounding boxes with
shape (N,).
Returns:
torch.Tensor: Loss tensor with shape (N,).
"""
dis_left = label.long()
dis_right = dis_left + 1
weight_left = dis_right.float() - label
weight_right = label - dis_left.float()
loss = (
F.cross_entropy(pred, dis_left, reduction="none") * weight_left
+ F.cross_entropy(pred, dis_right, reduction="none") * weight_right
)
return loss
4.标签匹配策略
NanodetPlus使用了DynamicSoftLabelAssigner,DSLA,参考YoloX中的SimOTA算法来做标签匹配,SimOTA是一种动态标签匹配算法,基于dynamic k来实现,先计算cost matrix,再将其当作任务分配问题,关于YoloX中的
SimOTA算法可以参考这里。
5.后处理介绍
虽然NanoDetPlus作者将模型最终的输出concat为了一个输出,从下图可以看到NanoDetPlus有四个输出头,对应的stride分别为[8, 16, 32, 64]。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-q5mRVvqm-1666880487603)(/images/Detection/10NanodetPlus/1.png)]
上图中四个输出头特征图的shape为[1, 33, 80, 80]/[1, 33, 40, 40]/[1, 33, 20, 20]/[1, 33, 10, 10],shape分别对应的含义是[batch_size, num_class+4*(reg_max+1), feature_map_height, feature_map_width]。batch_size,num_class,feature_map_{height,width}都好理解,reg_max却是新引入的一个超参数,值得介绍一下。
NanodetPlus是类FCOS的AnchorFree算法,直接预测的是检测框距离中心点的距离(left,top,right,bottom)。
https://foobarweb.net/2022/09/22/7FCOSNet/

中心点就是通过meshgrid(range(feature_width), range(feature_height))*stride得到的从特征图映射到输入图像尺度中的点,而(left,top,right,bottom)的预测作者使用的是Generalized Focal Loss(GFL)中提出的离散化回归的方法。
Generalized Focal Loss(GFL)是南开大学的李翔在2020年6月发表的论文中提出的。该方法是离散化检测框回归的范围,选取range(0, reg_max+1)上的离散值作为回归目标,reg_max是最大回归范围。
如上选reg_max=7,则可以理解为在特征图上将检测框上下左右边距离中心的距离设置为[0,1,...,7]这8种离散值,网络输出预测的分别是上下左右边落在[0,1,..,7]上的概率,因此输入的大小为4*(reg_max+1),为求边距中心的距离,需求落在[0,1,..7]上各点的期望,然后再利用stride将检测框映射到输入图尺寸上即可。当reg_max=7,stride=8时,对应检测框的最大尺寸为(7x8+7x8)x(7x8+7x8)=112x112,因此检测框范围可以覆盖(0-112)。关于这一部分详细的介绍可以参考源码nanodet/model/head/gfl_head.py。
class Integral(nn.Module):
"""A fixed layer for calculating integral result from distribution.
This layer calculates the target location by :math: `sum{P(y_i) * y_i}`,
P(y_i) denotes the softmax vector that represents the discrete distribution
y_i denotes the discrete set, usually {0, 1, 2, ..., reg_max}
Args:
reg_max (int): The maximal value of the discrete set. Default: 16. You
may want to reset it according to your new dataset or related
settings.
"""
def __init__(self, reg_max=16):
super(Integral, self).__init__()
self.reg_max = reg_max
self.register_buffer(
"project", torch.linspace(0, self.reg_max, self.reg_max + 1)
)
def forward(self, x):
"""Forward feature from the regression head to get integral result of
bounding box location.
Args:
x (Tensor): Features of the regression head, shape (N, 4*(n+1)),
n is self.reg_max.
Returns:
x (Tensor): Integral result of box locations, i.e., distance
offsets from the box center in four directions, shape (N, 4).
"""
shape = x.size()
x = F.softmax(x.reshape(*shape[:-1], 4, self.reg_max + 1), dim=-1)
x = F.linear(x, self.project.type_as(x)).reshape(*shape[:-1], 4)
return x
除了Integral处理外,其余的就是常规的后处理操作了,distance2Box然后做multiclass_nms。还有一点就是作者计算分类的评分时使用的sigmoid函数,一个detection box有可能分配多个标签,直观上NanodetPlus应该对不同类别的物体遮挡有相对好的检测效果。具体可以参考nanodet/model/module/nms.py中multiclass_nms函数的下面部分代码:
def multiclass_nms(...args):
...
num_classes = multi_scores.size(1) - 1
# exclude background category
if multi_bboxes.shape[1] > 4:
bboxes = multi_bboxes.view(multi_scores.size(0), -1, 4)
else:
bboxes = multi_bboxes[:, None].expand(multi_scores.size(0), num_classes, 4)
scores = multi_scores[:, :-1]
# filter out boxes with low scores
valid_mask = scores > score_thr
# We use masked_select for ONNX exporting purpose,
# which is equivalent to bboxes = bboxes[valid_mask]
# we have to use this ugly code
bboxes = torch.masked_select(
bboxes, torch.stack((valid_mask, valid_mask, valid_mask, valid_mask), -1)
).view(-1, 4)
if score_factors is not None:
scores = scores * score_factors[:, None]
scores = torch.masked_select(scores, valid_mask)
labels = valid_mask.nonzero(as_tuple=False)[:, 1]
6.特征融合
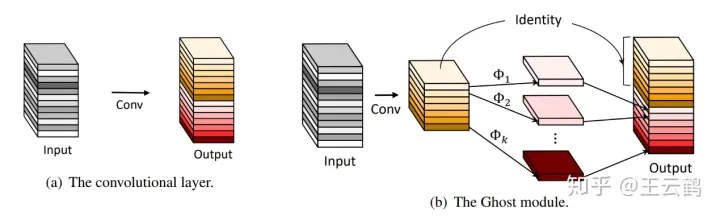
在bottleneck部分除了FPN和PAN,NanodetPlus中还引入了GhostPAN更好的做特征融合,GhostNet是华为诺亚实验室在CVPR2020上提出的模型,GhostNet作者指出在一个训练好的神经网络中,通常会包含丰富甚至冗余的特征图,

其实部分特征图完全可以通过一次线性变换 Φ i \Phi_{i} Φi来实现,因此卷积层输出的通道就部分来自于卷积,部分通过对卷积结果线性变换得到,concat后得到最终的输出。
欢迎访问个人网络日志知行空间
参考资料
- 1.大白话 Generalized Focal Loss
- 2.超简单辅助模块加速训练收敛,精度大幅提升!移动端实时的NanoDet升级版NanoDet-Plus来了!
- 3.YOLO之外的另一选择,手机端97FPS的Anchor-Free目标检测模型NanoDet现已开源~
- 4.CVPR 2020:华为GhostNet,超越谷歌MobileNet,已开源