C++ 编译 编译预处理 优化 函数调用约定 汇编 链接
➜ Link g++ -c func.cpp -o func.o
➜ Link ar -rcs libfunc.a func.o //创建静态链接库
➜ Link g++ -o main main.cpp libfunc.a
➜ Link ./main
5
➜ Link ls
func.cpp func.hpp func.o libfunc.a main main.cpp
➜ Link ar -t libfunc.a
func.o
➜ Link touch func2.cpp
➜ Link sudo vim ./func2.cpp
➜ Link g++ -c func2.cpp -o func2.o
➜ Link ar -r libfunc.a func2.o
➜ Link ar -t libfunc.a
func.o
func2.o
➜ Link vim ./main.cpp
➜ Link sudo vim ./main.cpp
➜ Link g++ main.cpp libfunc.a -o main
➜ Link ./main
func1=5
func2=6
➜ Link ls
func2.cpp func2.o func.cpp func.hpp func.o libfunc.a main main.cpp
//main.cpp
#include//func.hpp
int func(const int &a, const int &b);
//func.cpp
#include "func.hpp"
int func(const int &a, const int &b){
return a+b;
}
//func2.cpp
#include 1、默认
命令: g++ test.cpp
功能:生成默认为a.exe的文件。
3、调试 -g
命令: g++ qaq.cpp -o qdq -g
功能:生成用于gdb调试的文件qdq.dSYM。
-
gcc -E source_file.c
-E,只执行到预编译。直接输出预编译结果。 -
gcc -S source_file.c
-S,只执行到源代码到汇编代码的转换,输出汇编代码。 -
gcc -c source_file.c
-c,只执行到编译,输出目标文件。 -
gcc (-E/S/c/) source_file.c -o output_filename
-o, 指定输出文件名,可以配合以上三种标签使用。
-o 参数可以被省略。这种情况下编译器将使用以下默认名称输出:
-E:预编译结果将被输出到标准输出端口(通常是显示器)
-S:生成名为source_file.s的汇编代码
-c:生成名为source_file.o的目标文件。
无标签情况:生成名为a.out的可执行文件。
4、警告 -W -w
命令:g++ qaq.cpp -o qaq -W
功能:显示所有的警告信息
命令:g++ qaq.cpp -o qaq -w
功能:禁止显示所有警告信息
5、优化 -O{num}
命令:g++ qaq.cpp -o qaq -O2
功能:主要有O1,O2,O3,Os,分别优化大小,功能,功能,大小。
6、标准 -std={version}
命令:g++ qaq.cpp -o qaq -O2 -std=c++11
7、Win系统栈 -Wl,–stack={size}
命令:g++ 1.cpp -o 1 -Wl,–stack=16777216
功能:把调用栈的大小指定为16MB。
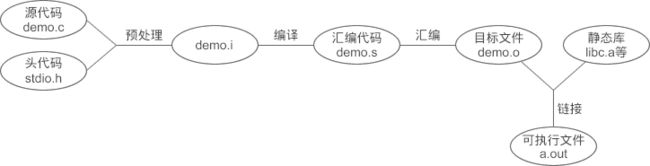
C语言的编译链接过程要把我们编写的一个c程序(源代码)转换成可以在硬件上运行的程序(可执行代码),需要进行编译和链接。编译就是把文本形式源代码翻译为机器语言形式的目标文件的过程。链接是把目标文件、操作系统的启动代码和用到的库文件进行组织,形成最终生成可执行代码的过程。过程图解如下:
从图上可以看到,整个代码的编译过程分为编译和链接两个过程,编译对应图中的大括号括起的部分,其余则为链接过程。
编译过程
编译过程又可以分成两个阶段:编译和汇编。
编译
编译是读取源程序(字符流),对之进行词法和语法的分析,将高级语言指令转换为功能等效的汇编代码,源文件的编译过程包含两个主要阶段:
编译预处理
读取c源程序,对其中的伪指令(以# 开头的指令)和特殊符号进行处理。
伪指令主要包括以下四个方面:
-
宏定义指令,如
# define Name TokenString,# undef等。
对于前一个伪指令,预编译所要做的是将程序中的所有Name用TokenString替换,但作为字符串常量的 Name则不被替换。对于后者,则将取消对某个宏的定义,使以后该串的出现不再被替换。 -
条件编译指令,如
# ifdef,# ifndef,# else,# elif,# endif等。
这些伪指令的引入使得程序员可以通过定义不同的宏来决定编译程序对哪些代码进行处理。预编译程序将根据有关的文件,将那些不必要的代码过滤掉。 -
头文件包含指令,如
# include "FileName"或者# include < FileName>等。
在头文件中一般用伪指令# define定义了大量的宏(最常见的是字符常量),同时包含有各种外部符号的声明。
采用头文件的目的主要是为了使某些定义可以供多个不同的C源程序使用。因为在需要用到这些定义的C源程序中,只需加上一条# include语句即可,而不必再在此文件中将这些定义重复一遍。预编译程序将把头文件中的定义统统都加入到它所产生的输出文件中,以供编译程序对之进行处理。
包含到c源程序中的头文件可以是系统提供的,这些头文件一般被放在/ usr/ include目录下。在程序中# include它们要使用尖括号(< >)。另外开发人员也可以定义自己的头文件,这些文件一般与c源程序放在同一目录下,此时在# include中要用双引号("")。 -
特殊符号,预编译程序可以识别一些特殊的符号。
例如在源程序中出现的LINE标识将被解释为当前行号(十进制数),FILE则被解释为当前被编译的C源程序的名称。预编译程序对于在源程序中出现的这些串将用合适的值进行替换。
预编译程序所完成的基本上是对源程序的“替代”工作。经过此种替代,生成一个没有宏定义、没有条件编译指令、没有特殊符号的输出文件。这个文件的含义同没有经过预处理的源文件是相同的,但内容有所不同。下一步,此输出文件将作为编译程序的输入而被翻译成为机器指令。
编译、优化阶段
经过预编译得到的输出文件中,只有常量;如数字、字符串、变量的定义,以及C语言的关键字,如main, if , else , for , while , { , } , + , - , * , \ 等等。
编译程序所要作得工作就是通过词法分析和语法分析,在确认所有的指令都符合语法规则之后,将其翻译成等价的中间代码表示或汇编代码。
四元式
四元式也是一种比较普遍采用的中间代码形式,
其形式为:(OP,ARG1,ARG2,RESULT)
其中:OP为运算符,ARG1为第一运算对象,ARG2为第二运算对象,RESULT为运算结果。
运算对象和运算结果有时指用户自定义的变量,有时指编译程序引进的临时变量。我们很容易将一个表达式或一个语句表示为一组四元式。例如表达式a+b的四元式为:( +,a,b,T)在四元式表示法中,特别规定,对于单目运算符(单目减、逻辑非、类型转换等),其四元式中的ARG2为空,一般用符号“/”或“ -”表示。例如表达式-a的四元式为:( -,a,/,T)
三元式
三元式表示是与四元式类似的一种表示法,所不同的仅是三元式中没有表示运算结果的部分,凡要涉及到运算结果的均用三元式的位置或序号来代替。
三元式的形式为:(OP,ARG1,ARG2)
其中,OP为运算符,ARG1为第一运算对象,ARG2为第二运算对象。运算对象ARG1,ARG2可以是变量名,也可以是三元式的编号。
例如,表达式a+bc的三元式表示为:
①(,b,c)
②( +,a,①)
其中,三元式中的元素①表示第一个三元式的结果。
优化处理是编译系统中一项比较艰深的技术。它涉及到的问题不仅同编译技术本身有关,而且同机器的硬件环境也有很大的关系。优化一部分是对中间代码的优化,这种优化不依赖于具体的计算机。另一种优化则主要针对目标代码的生成而进行的。
对于前一种优化,主要的工作是删除公共表达式、循环优化(代码外提、强度削弱、变换循环控制条件、已知量的合并等)、复写传播,以及无用赋值的删除,等等。
针对目标代码:
P := 0
for I := 1 to 20 do
P := P + A[I]*B[I]
假设其翻译所得的中间代码如下

- 删除多余运算
分析上图的中间代码,可以发现(3)和式(6)属于重复计算(因为I并没有发生变化),故而式(6)是多余的,完全可以采用T4∶=T1代替。 - 代码外提
减少循环中代码总数的一个重要办法是循环中不变的代码段外提。这种变换把循环不变运算,即结果独立于循环执行次数的表达式,提到循环的前面,使之只在循环外计算一次。针对改定的例子,显然数组A和 B的首地址在计算过程中并不改变,则作出的改动如下

3. 强度削弱
强度削弱的本质是把强度大的运算换算成强度小的运算,例如将乘法换成加法运算。针对上面的循环过程,每循环一次,I的值增加1,T1的值与I保持线性关系,每次总是增加4。因此,可以把循环中计算T1值的乘法运算变换成在循环前进行一次乘法运算,而在循环中将其变换成加法运算。
经过优化得到的汇编代码必须经过汇编程序的汇编转换成相应的机器指令,方可能被机器执行。

后一种类型的优化同机器的硬件结构密切相关,最主要的是考虑是如何充分利用机器的各个硬件寄存器存放有关变量的值,以减少对于内存的访问次数。另外,如何根据机器硬件执行指令的特点(如流水线、RISC、CISC、VLIW等)而对指令进行一些调整使目标代码比较短,执行的效率比较高,也是一个重要的研究课题。
函数调用约定
__cdecl是C/C++和MFC程序默认使用的调用约定,也可以在函数声明时加上__cdecl关键字来手工指定。采用__cdecl约定时,函数参数按照从右到左的顺序入栈,并且由调用函数者把参数弹出栈以清理堆栈。因此,实现可变参数的函数只能使用该调用约定。由于每一个使用__cdecl约定的函数都要包含清理堆栈的代码,所以产生的可执行文件大小会比较大。__cdecl可以写成_cdecl。
__stdcall调用约定用于调用Win32 API函数。采用__stdcall约定时,函数参数按照从右到左的顺序入栈,被调用的函数在返回前清理传送参数的栈,函数参数个数固定。由于函数体本身知道传进来的参数个数,因此被调用的函数可以在返回前用一条ret n指令直接清理传递参数的堆栈。__stdcall可以写成_stdcall。
__fastcall约定用于对性能要求非常高的场合。__fastcall约定将函数的从左边开始的两个大小不大于4个字节(DWORD)的参数分别放在ECX和EDX寄存器,其余的参数仍旧自右向左压栈传送,被调用的函数在返回前清理传送参数的堆栈。__fastcall可以写成_fastcall
汇编
汇编过程实际上指把汇编语言代码翻译成目标机器指令的过程。对于被翻译系统处理的每一个C语言源程序,都将最终经过这一处理而得到相应的目标文件。目标文件中所存放的也就是与源程序等效的目标的机器语言代码。
目标文件由段组成。通常一个目标文件中至少有两个段:
-
代码段:该段中所包含的主要是程序的指令。该段一般是可读和可执行的,但一般却不可写。
-
数据段:主要存放程序中要用到的各种全局变量或静态的数据。一般数据段都是可读,可写,可执行的。
- 链接过程
由汇编程序生成的目标文件并不能立即就被执行,其中可能还有许多没有解决的问题。
例如,某个源文件中的函数可能引用了另一个源文件中定义的某个符号(如变量或者函数调用等);在程序中可能调用了某个库文件中的函数,等等。所有的这些问题,都需要经链接程序的处理方能得以解决。
链接程序的主要工作就是将有关的目标文件彼此相连接,也即将在一个文件中引用的符号同该符号在另外一个文件中的定义连接起来,使得所有的这些目标文件成为一个能够被操作系统装入执行的统一整体。
根据开发人员指定的同库函数的链接方式的不同,链接处理可分为两种:
- 静态链接
在这种链接方式下,函数的代码将从其所在的静态链接库中被拷贝到最终的可执行程序中。这样该程序在被执行时这些代码将被装入到该进程的虚拟地址空间中。静态链接库实际上是一个目标文件的集合,其中的每个文件含有库中的一个或者一组相关函数的代码。
- 动态链接
在此种方式下,函数的代码被放到称作是动态链接库或共享对象的某个目标文件中。链接程序此时所作的只是在最终的可执行程序中记录下共享对象的名字以及其它少量的登记信息。在此可执行文件被执行时,动态链接库的全部内容将被映射到运行时相应进程的虚地址空间。动态链接程序将根据可执行程序中记录的信息找到相应的函数代码。
对于可执行文件中的函数调用,可分别采用动态链接或静态链接的方法。使用动态链接能够使最终的可执行文件比较短小,并且当共享对象被多个进程使用时能节约一些内存,因为在内存中只需要保存一份此共享对象的代码。但并不是使用动态链接就一定比使用静态链接要优越。在某些情况下动态链接可能带来一些性能上损害。
- GCC的编译链接
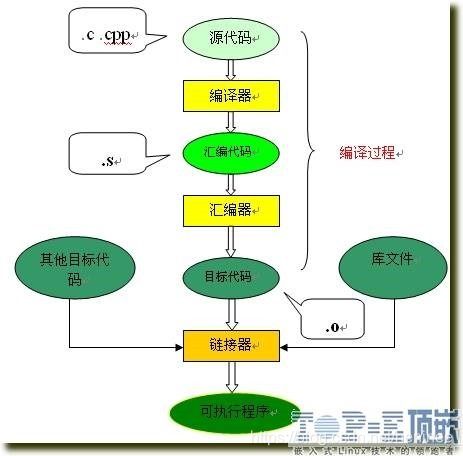
我们在linux使用的gcc编译器便是把以上的几个过程进行捆绑,使用户只使用一次命令就把编译工作完成,这的确方便了编译工作,但对于初学者了解编译过程就很不利了,下图便是gcc代理的编译过程:
- 预编译
将.c 文件转化成 .i文件
使用的gcc命令是:gcc –E
对应于预处理命令cpp - 编译
将.c/.h文件转换成.s文件
使用的gcc命令是:gcc –S
对应于编译命令 cc –S - 汇编
将.s 文件转化成 .o文件
使用的gcc 命令是:gcc –c
对应于汇编命令是 as - 链接
将.o文件转化成可执行程序
使用的gcc 命令是: gcc
对应于链接命令是 ld
总结起来编译过程就上面的四个过程:预编译处理(.c) --> 编译、优化程序(.s、.asm)--> 汇编程序(.obj、.o、.a、.ko) --> 链接程序(.exe、.elf、.axf等)。
- 总结
C语言编译的整个过程是非常复杂的,里面涉及到的编译器知识、硬件知识、工具链知识都是非常多的,深入了解整个编译过程对工程师理解应用程序的编写是有很大帮助的,希望大家可以多了解一些,在遇到问题时多思考、多实践。
一般情况下,我们只需要知道分成编译和链接两个阶段,编译阶段将源程序(*.c) 转换成为目标代码(一般是obj文件,至于具体过程就是上面说的那些阶段),链接阶段是把源程序转换成的目标代码(obj文件)与你程序里面调用的库函数对应的代码连接起来形成对应的可执行文件(exe文件)就可以了,其他的都需要在实践中多多体会才能有更深的理解。