利用huggingface进行文本分类
在 Hub 中,您可以找到 AI 社区共享的 27,000 多个模型,这些模型在情感分析、对象检测、文本生成、语音识别等任务上具有最先进的性能。
from transformers import pipeline
#sentiment_pipeline = pipeline("sentiment-analysis")
data = [
"This is wonderful and easy to put together. My cats love it.",
"This cat tree is almost perfect. I wanted a tall tree, and this one delivers. It reaches almost to the top of my 8\' ceiling",
"The super large box had disintegrated by the time it arrived to my doorstep & large portions were missing from a 89” solid wood cat tree. I took detailed pictures of the box before & after unpacking & laying out all contents. Several pieces were badly damaged & 3 crucial pieces were missing.
A 45 minute phone call with Amazon resulted in Amazon requesting missing parts from Armarkat who never responded despite my repeated attempts to follow-through. Amazon offered for me to purchase another box, pack it & haul the box (weighs more than I weigh) to a place to be picked up. There’s no opportunity to do that where I live.
It’s a very expensive loss"]
sentiment_pipeline = pipeline("sentiment-analysis")
print(sentiment_pipeline(data))
在自己的亚马逊数据集上训练
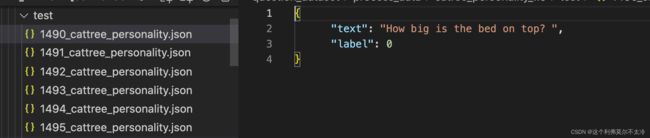
from datasets import load_dataset
from transformers import AutoTokenizer
from transformers import DataCollatorWithPadding
from transformers import AutoModelForSequenceClassification, TrainingArguments, Trainer
from datasets import load_dataset
import os.path as osp
import os
import numpy as np
from datasets import load_metric
### pretrained model :distilbert-base-uncased
### bert-base-uncased
### gpt2
### distilgpt2
def get_list(path,file_list):
end_list = []
for sample in file_list:
sample_path = osp.join(path,sample)
end_list.append(sample_path)
return end_list
def get_dataset(dataset_path):
test_path = osp.join(dataset_path,'test/')
train_path = osp.join(dataset_path,'train/')
val_path = osp.join(dataset_path,'val/')
test_file_list = os.listdir(test_path)
train_file_list = os.listdir(train_path)
val_file_list = os.listdir(val_path)
test_list = get_list(test_path,test_file_list)
train_list = get_list(train_path,train_file_list)
val_list = get_list(val_path,val_file_list)
return test_list,train_list,val_list
def check_the_wrong_sample(labels,predictions):
val_folder = '/cloud/cloud_disk/users/huh/dataset/nlp_dataset/question_dataset/process_data/cattree_product_quality/val'
end_folder = '/cloud/cloud_disk/users/huh/dataset/nlp_dataset/question_dataset/process_data/cattree_product_quality/wrong_sample'
sample_list = os.listdir(val_folder)
index = 0
for samle in labels:
if samle != predictions[index]:
print(index)
print(sample_list[index])
wrong_sample_path = osp.join(val_folder,sample_list[index])
end_sample_path = osp.join(end_folder,sample_list[index])
os.system("cp {} {}".format(wrong_sample_path,end_sample_path))
index +=1
def compute_metric(eval_pred):
metric = load_metric("accuracy")
logits,labels = eval_pred
print(logits,labels)
print(len(logits),len(labels))
predictions = np.argmax(logits,axis=-1)
print(len(predictions))
print('predictions')
print(predictions)
check_the_wrong_sample(labels,predictions)
return metric.compute(predictions = predictions,references = labels)
def train(dataset_path):
test_list,train_list,val_list = get_dataset(dataset_path)
question_dataset = load_dataset('json', data_files={'train':train_list,'test':test_list,'val':val_list})
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
def preprocess_function(examples):
return tokenizer(examples["text"], truncation=True)
tokenized_imdb = question_dataset.map(preprocess_function, batched=True)
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)
training_args = TrainingArguments(
output_dir="./results",
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=5,
weight_decay=0.01,
logging_steps = 50,
run_name = "catree",
save_strategy='no'
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_imdb["train"],
eval_dataset=tokenized_imdb["val"],
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metric
)
trainer.train()
trainer.evaluate()
if __name__ == '__main__':
#dataset_path = '/cloud/cloud_disk/users/huh/dataset/nlp_dataset/question_dataset/process_data/catree_personality_2.0'
dataset_path = '/cloud/cloud_disk/users/huh/dataset/nlp_dataset/question_dataset/process_data/cattree_product_quality'
train(dataset_path)