huggingface:transformers中文文本分类
目录
导入相关包
加载数据集
数据集处理
评估函数
配置训练器
训练与评估
预测
导入相关包
import evaluate
from datasets import load_dataset
from transformers import AutoModelForSequenceClassification, AutoTokenizer, DataCollatorWithPadding, TrainingArguments, Trainer加载数据集
这次用到的数据集是ChnSentiCorp_htl_all酒店评论分类数据集,是一项二分类任务,0代表情感负向,1代表情感正向。
| 数据集 | 数据概览 | 下载 |
|---|---|---|
| ChnSentiCorp_htl_all | 7000 多条酒店评论数据,5000 多条正向评论,2000 多条负向评论 | 地址 |

训练自己的数据集时,保证有标签和文本两列.csv格式(标签为0,1,2数字)
# 加载数据集
data_file = "./ChnSentiCorp_htl_all.csv" # 数据文件路径,数据需要提前下载
dataset = load_dataset("csv", data_files=data_file)
dataset = dataset.filter(lambda x: x["review"] is not None) # 删掉空白数据
datasets = dataset["train"].train_test_split(0.2)数据集处理
定义数据处理函数,使用map方法,对数据集进行处理,指定batched参数值为True,这样会加速数据处理。(保证examples[" "]中的名字与数据集中的名字的对应)
model_name = "hfl/rbt3" # 所使用模型
# 数据集处理
tokenizer = AutoTokenizer.from_pretrained(model_name)
def process_function(examples):
tokenized_examples = tokenizer(examples["review"], max_length=64, truncation=True)
tokenized_examples["labels"] = examples["label"]
return tokenized_examples
tokenized_datasets = datasets.map(process_function, batched=True)评估函数
文本分类任务以准确率作为评价指标,直接通过evaluate进行加载。模型预测的结果需要进一步argmax获取标签值,最终返回结果为字典。
# 构建评估函数
def compute_metrics(eval_pred):
accuracy_metric = evaluate.load("accuracy")
predictions, labels = eval_pred
predictions = predictions.argmax(axis=-1)
return accuracy_metric.compute(predictions=predictions, references=labels)配置训练器
加载模型(多分类时,num_labels=分类的类别数量)
model = AutoModelForSequenceClassification.from_pretrained(model_name, num_labels=2)设置训练参数
args = TrainingArguments(
output_dir="model_for_seqclassification",
learning_rate=2e-5,
per_device_train_batch_size=32,
per_device_eval_batch_size=128,
num_train_epochs=5,
weight_decay=0.01, # 权重衰减
logging_steps=10, # 日志记录的步长(loss,学习率)
evaluation_strategy="epoch", # 评估策略为训练完一个epoch之后进行评估
save_strategy="epoch", # 保存策略同上
save_total_limit=3, # 最多保存数量
load_best_model_at_end=True, # 设置训练完成后加载最优模型
metric_for_best_model="accuracy", # 指定最优模型的评估指标为accuracy
fp16=True # 半精度训练(提高训练速度)
)构建训练器
trainer = Trainer(
model,
args=args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
tokenizer=tokenizer,
compute_metrics=compute_metrics,
data_collator=DataCollatorWithPadding(tokenizer=tokenizer)
)训练与评估
# 训练与评估
trainer.train()
trainer.evaluate()预测
定义预测函数
def predict(txt):
model_path = r'model_for_seqclassification\checkpoint-975' # 训练后的模型路径
model = AutoModelForSequenceClassification.from_pretrained(model_path)
tokenizer = BertTokenizer.from_pretrained("hfl/rbt3")
# 预测
pipe = pipeline("text-classification", model=model, tokenizer=tokenizer)
label_dic = {'LABEL_0': '太次了', 'LABEL_1': '很棒'}
st = time.time()
result = pipe(txt)
result[0]['label'] = label_dic[result[0]['label']]
ed = time.time()
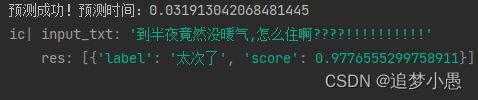
print('预测成功!' + '预测时间:' + str(ed - st))
return resultdemo
input_txt = '到半夜竟然没暖气,怎么住啊????!!!!!!!!!!'
res = predict(input_txt)
ic(input_txt, res)结果