3节点Fate集群实战记录 -- 纵向联邦学习
前一篇博客记录了3节点fate集群实现横向联邦学习的实践过程link,本篇接着记录纵向联邦学习的实践过程,其中有些简单步骤未详细列出,具体执行方法可以参考上篇博客。
纵向联邦的场景简单说就是A和B两数据方,A知道B有A没有的特征bx,B知道A有B没有的特征ax以及标注y,且A和B猜测两方有较多共同的用户(id),两方想基于共同用户构建用上双方特征数据的模型,且互不泄露共同用户id。
一、三方训练
1.1、数据制作
同上篇博客,以睡/醒二分类模型为实践对象,本人将数据的40个特征按3大类(呼吸breathrate、心率heartrate、体动值energy)分割开来,集群的3个节点各自只拥有其中一类特征的数据。3节点的训练数据id可以完全相同(官方例子是完全相同),也可以部分相同,但要保证3节点有较多共同的数据id。数据制作代码如下,注意事项在代码中有注释:
# -*-coding:utf-8-*-
import pandas as pd
from sklearn.preprocessing import StandardScaler
# 完整的训练数据和测试数据
train = pd.read_csv('E:/FederalLearning/sleep_belt_homo/data/train_feature_0916.csv')
test = pd.read_csv('E:/FederalLearning/sleep_belt_homo/data/test_0916.csv')
# 标准化特征数据
f_cols = [item for item in train.columns.tolist() if item not in ['file', 'person', 'y']]
scaler = StandardScaler() # 实例化
scaler = scaler.fit(train[f_cols].values) # #fit,在这里本质是生成min(x)和max(x)
# 训练数据
train_a = scaler.transform(train[f_cols].values)
# 测试数据
test_a = scaler.transform(test[f_cols].values)
# 赋值为标准化后的值
train[f_cols] = train_a.astype("float32") # 数据精度搞成32位数,以免出错
test[f_cols] = test_a.astype("float32")
train['y'] = train['y'].apply("int32")
test['y'] = test['y'].apply("int32")
# 数据的id设置
train['id'] = list(range(train.shape[0]))
test['id'] = list(range(test.shape[0]))
test['id'] = test['id'] + train.shape[0] # 确保训练集id和测试集id不要有重复
# 查看各个人的数据量
for item in sorted(train['person'].unique()):
print(item, train[train['person']==item].shape[0], train[train['person']==item]['file'].iloc[0])
# 将数据量最多的3个person剔除掉其一变成为一份数据
data1 = train[train['person']!=1]
data2 = train[train['person']!=4]
data3 = train[train['person']!=6]
# 将数据按心率、呼吸、体动能量特征分为3类
col1 = [item for item in train.columns.tolist() if 'heartrate' in item]
col2 = [item for item in train.columns.tolist() if 'breathrate' in item]
col3 = [item for item in train.columns.tolist() if 'energy' in item]
col1_x = [ 'x'+str(i) for i in range(len(col1))] # 注意这里的新特征编号
col2_x = [ 'x'+str(i) for i in range(len(col2))] # 注意这里的新特征编号
col3_x = [ 'x'+str(i) for i in range(len(col3))] # 注意这里的新特征编号
# 训练数据
data1 = data1[['id', 'y']+col1]
data1.columns = ['id', 'y']+col1_x
data2 = data2[['id']+col2]
data2.columns = ['id']+col2_x
data3 = data3[['id']+col3]
data3.columns = ['id']+col3_x
# 测试数据
test1 = test[['id', 'y']+col1]
test1.columns = ['id', 'y']+col1_x
test2 = test[['id']+col2]
test2.columns = ['id']+col2_x
test3 = test[['id']+col3]
test3.columns = ['id']+col3_x
# 保存数据
data1.to_csv('E:/FederalLearning/sleep_belt_hetero/data/sleep_hetero_train_1_y.csv', index=False)
data2.to_csv('E:/FederalLearning/sleep_belt_hetero/data/sleep_hetero_train_2.csv', index=False)
data3.to_csv('E:/FederalLearning/sleep_belt_hetero/data/sleep_hetero_train_3.csv', index=False)
test1.to_csv('E:/FederalLearning/sleep_belt_hetero/data/sleep_hetero_test_1_y.csv', index=False)
test2.to_csv('E:/FederalLearning/sleep_belt_hetero/data/sleep_hetero_test_2.csv', index=False)
test3.to_csv('E:/FederalLearning/sleep_belt_hetero/data/sleep_hetero_test_3.csv', index=False)
以下表格是各个节点将需要上传的数据或配置文件:
| 节点 | fate-9998 | fate-9999 | fate-10000 |
|---|---|---|---|
| 训练数据 | sleep_hetero_train_3.csv | sleep_hetero_train_1_y.csv | sleep_hetero_train_2.csv |
| 测试数据 | sleep_hetero_test_3.csv | sleep_hetero_test_1_y.csv | sleep_hetero_test_2.csv |
| 训练数据上传脚本 | upload_train_9998.json | upload_train_9999.json | upload_train_10000.json |
| 测试数据上传脚本 | upload_test_9998.json | upload_test_9999.json | upload_test_10000.json |
1.2、上传数据文件到容器
以fate-10000为例,先进入python容器创建放数据的目录:
[root@harbor ~]# kubectl exec -it svc/fateflow -c python -n fate-10000 -- bash
(app-root) bash-4.2# cd ..
(app-root) bash-4.2# mkdir my_test
(app-root) bash-4.2# cd my_test
(app-root) bash-4.2# mkdir sleep_hetero
(app-root) bash-4.2# cd sleep_hetero
(app-root) bash-4.2# pwd
/data/projects/my_test/sleep_hetero
将宿主机的数据文件拷贝到容器的指定目录:
[root@harbor kubefate]# kubectl get pods -n fate-10000 -o wide # 先查看pod的id
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
client-6765697776-gx7xk 1/1 Running 0 22h 10.244.0.55 harbor.clife.io
clustermanager-7fb64d6778-89zqj 1/1 Running 0 22h 10.244.0.53 harbor.clife.io
mysql-655dc6847c-4xt87 1/1 Running 0 22h 10.244.0.51 harbor.clife.io
nodemanager-0-7b4b9b54c6-xtg7w 2/2 Running 0 22h 10.244.0.52 harbor.clife.io
nodemanager-1-57b75bd874-lt6n6 2/2 Running 0 22h 10.244.0.57 harbor.clife.io
nodemanager-2-679b569f56-7hxfj 2/2 Running 0 22h 10.244.0.58 harbor.clife.io
python-f4b7fff6-bjnfv 2/2 Running 0 22h 10.244.0.56 harbor.clife.io
rollsite-765465d678-rv2gj 1/1 Running 0 22h 10.244.0.54 harbor.clife.io
[root@harbor ~]# kubectl cp /home/FATE_V172/host_to_fate/data/sleep_hetero_test_2.csv fate-10000/python-f4b7fff6-bjnfv:/data/projects/my_test/sleep_hetero/ -c python
[root@harbor ~]# kubectl cp /home/FATE_V172/host_to_fate/data/sleep_hetero_train_2.csv fate-10000/python-f4b7fff6-bjnfv:/data/projects/my_test/sleep_hetero/ -c python
同上方法在fate-9999中传入sleep_hetero_train_1_y.csv,sleep_hetero_test_1_y.csv,在fate-9998中传入sleep_hetero_train_3.csv,sleep_hetero_test_3.csv。
1.3、配置上传数据的文件和上传到容器
以fate-10000节点为例,配置上传数据的文件upload_train_10000.json:
{
"file": "/data/projects/my_test/sleep_hetero/sleep_hetero_train_2.csv",
"head": 1,
"partition": 4,
"work_mode": 1,
"table_name": "sleep_hetero_train_10000",
"namespace": "experiment"
}
配置上传数据的文件upload_test_10000.json:
{
"file": "/data/projects/my_test/sleep_hetero/sleep_hetero_test_2.csv",
"head": 1,
"partition": 4,
"work_mode": 1,
"table_name": "sleep_hetero_test_10000",
"namespace": "experiment"
}
将文件upload_train_10000.json和upload_test_10000.json传入到fate-10000的容器python中:
[root@harbor ~]# kubectl cp /home/FATE_V172/host_to_fate/data/upload_train_10000.json fate-10000/python-f4b7fff6-bjnfv:/data/projects/my_test/sleep_hetero/ -c python
[root@harbor ~]# kubectl cp /home/FATE_V172/host_to_fate/data/upload_test_10000.json fate-10000/python-f4b7fff6-bjnfv:/data/projects/my_test/sleep_hetero/ -c python
同样在fate-9999和fate-9998重复以上操作。
1.4、flow命令上传容器内数据到fate
如果你的flow命令用不了,请参考本人博客的最后小节进行处理link:
以fate-10000为例子,进入fate-10000的python容器,flow上传训练数据:
(app-root) bash-4.2# cd /data/projects/my_test/sleep_hetero
(app-root) bash-4.2# flow data upload -c upload_train_10000.json
{
"data": {
"board_url": "http://fateboard:8080/index.html#/dashboard?job_id=202212200751305475490&role=local&party_id=0",
"code": 0,
"dsl_path": "/data/projects/fate/fateflow/jobs/202212200751305475490/job_dsl.json",
"job_id": "202212200751305475490",
"logs_directory": "/data/projects/fate/fateflow/logs/202212200751305475490",
"message": "success",
"model_info": {
"model_id": "local-0#model",
"model_version": "202212200751305475490"
},
"namespace": "experiment",
"pipeline_dsl_path": "/data/projects/fate/fateflow/jobs/202212200751305475490/pipeline_dsl.json",
"runtime_conf_on_party_path": "/data/projects/fate/fateflow/jobs/202212200751305475490/local/0/job_runtime_on_party_conf.json",
"runtime_conf_path": "/data/projects/fate/fateflow/jobs/202212200751305475490/job_runtime_conf.json",
"table_name": "sleep_hetero_train_10000",
"train_runtime_conf_path": "/data/projects/fate/fateflow/jobs/202212200751305475490/train_runtime_conf.json"
},
"jobId": "202212200751305475490",
"retcode": 0,
"retmsg": "success"
}
(app-root) bash-4.2# flow data upload -c upload_test_10000.json
{
"data": {
"board_url": "http://fateboard:8080/index.html#/dashboard?job_id=202212200751401695710&role=local&party_id=0",
"code": 0,
"dsl_path": "/data/projects/fate/fateflow/jobs/202212200751401695710/job_dsl.json",
"job_id": "202212200751401695710",
"logs_directory": "/data/projects/fate/fateflow/logs/202212200751401695710",
"message": "success",
"model_info": {
"model_id": "local-0#model",
"model_version": "202212200751401695710"
},
"namespace": "experiment",
"pipeline_dsl_path": "/data/projects/fate/fateflow/jobs/202212200751401695710/pipeline_dsl.json",
"runtime_conf_on_party_path": "/data/projects/fate/fateflow/jobs/202212200751401695710/local/0/job_runtime_on_party_conf.json",
"runtime_conf_path": "/data/projects/fate/fateflow/jobs/202212200751401695710/job_runtime_conf.json",
"table_name": "sleep_hetero_test_10000",
"train_runtime_conf_path": "/data/projects/fate/fateflow/jobs/202212200751401695710/train_runtime_conf.json"
},
"jobId": "202212200751401695710",
"retcode": 0,
"retmsg": "success"
}
fate-9999和fate-9998重复以上操作。
1.5、基于pipeline进行三方加密训练
经过4.1小节,3个节点都已经上传了各自的训练数据和测试数据到fate。接着编写基于pipeline的训练代码,本人以fate-9999作为guest方,也就是任务发起方,以fate-10000, fate-9998作为host方,训练参与方,先测试不带加密参数传播的训练方式,代码sleep-hetero-lr-multi-host.py如下:
from pipeline.backend.pipeline import PipeLine
from pipeline.component import DataTransform
from pipeline.component import Evaluation
from pipeline.component import HeteroLR
from pipeline.component import Intersection
from pipeline.component import Reader
from pipeline.interface import Data
from pipeline.interface import Model
def main(namespace="", has_validate=False, need_evaluation=True):
lr_param = {
"name": "hetero_lr_0",
"penalty": "L2",
"optimizer": "nesterov_momentum_sgd",
"tol": 0.0001,
"alpha": 0.01,
"max_iter": 30,
"early_stop": "weight_diff",
"batch_size": -1,
"learning_rate": 0.15,
"init_param": {
"init_method": "zeros"
},
"sqn_param": {
"update_interval_L": 3,
"memory_M": 5,
"sample_size": 5000,
"random_seed": None
},
"cv_param": {
"n_splits": 5,
"shuffle": False,
"random_seed": 103,
"need_cv": False
}
}
guest = 9999 # 有标签一方作为发起方
host1 = 10000 # 参与方
host2 = 9998 # 参与方
hosts = [host1, host2]
arbiter = host2
guest_train_data = {"name": "sleep_hetero_train_"+str(guest), "namespace": f"experiment{namespace}"}
host_train_data1 = {"name": "sleep_hetero_train_"+str(host1), "namespace": f"experiment{namespace}"}
host_train_data2 = {"name": "sleep_hetero_train_"+str(host2), "namespace": f"experiment{namespace}"}
guest_eval_data = {"name": "sleep_hetero_test_"+str(guest), "namespace": f"experiment{namespace}"}
host_eval_data1 = {"name": "sleep_hetero_test_"+str(host1), "namespace": f"experiment{namespace}"}
host_eval_data2 = {"name": "sleep_hetero_test_"+str(host2), "namespace": f"experiment{namespace}"}
# initialize pipeline
pipeline = PipeLine()
# set job initiator
pipeline.set_initiator(role='guest', party_id=guest)
# set participants information
pipeline.set_roles(guest=guest, host=hosts, arbiter=arbiter)
# define Reader components to read in data
reader_0 = Reader(name="reader_0")
# configure Reader for guest
reader_0.get_party_instance(role='guest', party_id=guest).component_param(table=guest_train_data)
# configure Reader for host
reader_0.get_party_instance(role='host', party_id=host1).component_param(table=host_train_data1)
# configure Reader for host
reader_0.get_party_instance(role='host', party_id=host2).component_param(table=host_train_data2)
# define DataTransform components
data_transform_0 = DataTransform(name="data_transform_0", output_format='dense')
# get DataTransform party instance of guest
data_transform_0_guest_party_instance = data_transform_0.get_party_instance(role='guest', party_id=guest)
# configure DataTransform for guest
data_transform_0_guest_party_instance.component_param(with_label=True)
# get and configure DataTransform party instance of host
data_transform_0.get_party_instance(role='host', party_id=hosts).component_param(with_label=False)
# define Intersection components
intersection_0 = Intersection(name="intersection_0")
pipeline.add_component(reader_0)
pipeline.add_component(data_transform_0, data=Data(data=reader_0.output.data))
pipeline.add_component(intersection_0, data=Data(data=data_transform_0.output.data))
train_line = []
train_line.append(data_transform_0)
train_line.append(intersection_0)
last_cpn = None
if has_validate:
reader_1 = Reader(name="reader_1")
reader_1.get_party_instance(role='guest', party_id=guest).component_param(table=guest_eval_data)
reader_1.get_party_instance(role='host', party_id=host1).component_param(table=host_eval_data1)
reader_1.get_party_instance(role='host', party_id=host2).component_param(table=host_eval_data2)
pipeline.add_component(reader_1)
last_cpn = reader_1
for cpn in train_line:
cpn_name = cpn.name
new_name = "_".join(cpn_name.split('_')[:-1] + ['1'])
validate_cpn = type(cpn)(name=new_name)
if hasattr(cpn.output, "model"):
pipeline.add_component(validate_cpn, data=Data(data=last_cpn.output.data),
model=Model(cpn.output.model))
else:
pipeline.add_component(validate_cpn, data=Data(data=last_cpn.output.data))
last_cpn = validate_cpn
hetero_lr_0 = HeteroLR(**lr_param)
if has_validate:
pipeline.add_component(hetero_lr_0, data=Data(train_data=intersection_0.output.data,
validate_data=last_cpn.output.data))
else:
pipeline.add_component(hetero_lr_0, data=Data(train_data=intersection_0.output.data))
evaluation_data = [hetero_lr_0.output.data]
if has_validate:
hetero_lr_1 = HeteroLR(name='hetero_lr_1')
pipeline.add_component(hetero_lr_1, data=Data(test_data=last_cpn.output.data),
model=Model(hetero_lr_0.output.model))
evaluation_data.append(hetero_lr_1.output.data)
if need_evaluation:
evaluation_0 = Evaluation(name="evaluation_0", eval_type="binary")
pipeline.add_component(evaluation_0, data=Data(data=evaluation_data))
pipeline.compile()
# fit model
pipeline.fit()
if __name__ == "__main__":
main(namespace="", has_validate=True, need_evaluation=True)
参照1.2节,同样方式将代码传入到fate-9999容器内(代码只需要传入到guest节点,其他节点不需要传代码),然后在容器内执行代码即可提交训练任务:
(app-root) bash-4.2# python sleep-hetero-lr-multi-host.py
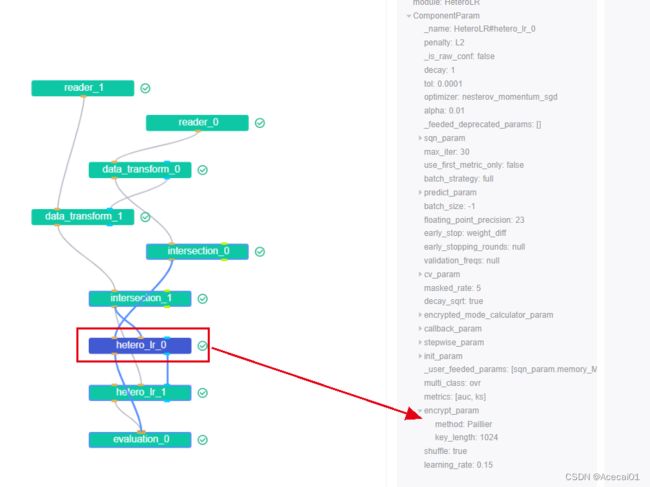
上面代码虽然没有配置加密项,但里面的用户id对齐模块intersection和模型训练模块hetero_lr都默认用了加密,这个可以在fateboard的模块图中查看到具体配置。如下图所示,训练模块hetero_lr用的是同态加密方法Paillier:
加密训练时会比较耗时,训练30轮差不多需要半小时,模型训练的评估结果如下截图所示。

以下表格是将fate-9999节点的数据单独在本地PC训练,以及三方纵向联邦训练所得模型分别在测试集上的数据结果:
| 指标 | fate-9999数据单独训练 | 纵向联邦 |
|---|---|---|
| ACC | 0.81 | 0.84 |
| Recall | 0.19 | 0.31 |
| Precesion | 0.88 | 98.8 |
虽然以上两者的数据都不好,但是纵向联邦学习的模型结果明显还是要好一些。
当上述代码的参数lr_param中"init_param"多一个"fit_intercept": True,在guest节点上fateboard日志会显示:
[INFO] [2022-12-21 02:02:39,968] [202212210159236395460] [81452:140201339701056] - [hetero_lr_guest.fit_binary] [line:132]: iter: 0
2228
[INFO] [2022-12-21 02:05:20,420] [202212210159236395460] [81452:140201339701056] - [hetero_lr_gradient_and_loss.compute_loss] [line:123]: More than one host exist, loss is not available
在两host节点上fateboard日志会显示:
[WARNING] [2022-12-23 07:14:13,387] [202212230706578015990] [29:140218862659328] - [job_saver.update_task] [line:95]: task 202212230706578015990_hetero_lr_0 0 update does not take effect
都不是报错,但是训练模块就一直失败,官网有人在v1.7.0版本遇到同样的问题,未解决,但是若2方执行训练就不会有问题,只会在3方执行训练的情况失败。。。
在3方训练情况下,想尝试改改别的配置参数也很容易报错,唯一没出错的就是上面所示的代码,故后面转而测试2方训练了。
二、两方训练
2.1、数据制作
# -*-coding:utf-8-*-
import pandas as pd
from sklearn.preprocessing import StandardScaler
# 完整的训练数据和测试数据
train = pd.read_csv('E:/FederalLearning/sleep_belt_homo/data/train_feature_0916.csv')
test = pd.read_csv('E:/FederalLearning/sleep_belt_homo/data/test_0916.csv')
# 标准化特征数据
f_cols = [item for item in train.columns.tolist() if item not in ['file', 'person', 'y']]
scaler = StandardScaler() # 实例化
scaler = scaler.fit(train[f_cols].values) # #fit,在这里本质是生成min(x)和max(x)
# 训练数据
train_a = scaler.transform(train[f_cols].values)
# 测试数据
test_a = scaler.transform(test[f_cols].values)
# 赋值为标准化后的值
train[f_cols] = train_a.astype("float32") # 减小数据的位数,防止报错
test[f_cols] = test_a.astype("float32")
train['y'] = train['y'].apply("int32")
test['y'] = test['y'].apply("int32")
# 数据的id设置
train['id'] = list(range(train.shape[0]))
test['id'] = list(range(test.shape[0]))
test['id'] = test['id'] + train.shape[0] # 保证训练集id和测试集id不要有重复
# ------------------ 分成2份-------------------------------------------------------
# 将数据量最多的2个person剔除掉其一变成为一份数据,2份数据既有相同数据也有不同数据
data1 = train[train['person']!=4] # 第一份数据
data2 = train[train['person']!=6] # 第二份数据
# 数据共有心率、呼吸、体动能量特征3类
# 刻意将心率数据赋给第一份数据,心率特征重要性是3类特征中最低的(构建随机森林模型得出),
# 但第一份数据有标签,第二份数据有重要性高的呼吸和能量数据,但是却没有标签。
col1 = [item for item in train.columns.tolist() if 'heartrate' in item]
col2 = [item for item in train.columns.tolist() if 'heartrate' not in item and item not in ['file', 'person', 'y', 'id']]
col1_x = [ 'x'+str(i) for i in range(len(col1))] # 特征列名都换成x+数字
col2_x = [ 'x'+str(i) for i in range(len(col2))] # 特征列名都换成x+数字
# 训练数据
data1 = data1[['id', 'y']+col1] # 第一份数据:心率+标签
data1.columns = ['id', 'y']+col1_x
data2 = data2[['id']+col2] # 第二份数据:呼吸+体动能量数据,无标签
data2.columns = ['id']+col2_x
# 测试数据
test1 = test[['id', 'y']+col1]
test1.columns = ['id', 'y']+col1_x
test2 = test[['id']+col2]
test2.columns = ['id']+col2_x
# 保存数据
data1.to_csv('E:/FederalLearning/sleep_belt_hetero/data/2party-sleep_hetero_train_1_y.csv', index=False)
data2.to_csv('E:/FederalLearning/sleep_belt_hetero/data/2party-sleep_hetero_train_2.csv', index=False)
test1.to_csv('E:/FederalLearning/sleep_belt_hetero/data/2party-sleep_hetero_test_1_y.csv', index=False)
test2.to_csv('E:/FederalLearning/sleep_belt_hetero/data/2party-sleep_hetero_test_2.csv', index=False)
数据制作的说明请看代码的注释
2.2、上传数据到容器后传到fate
参考1.2~1.4小节将数据上传到fate,数据分布如下表格:
| fate-9999 | fate-10000 |
|---|---|
| 2party-sleep_hetero_train_1_y.csv | 2party-sleep_hetero_train_2.csv |
| 2party-sleep_hetero_test_1_y.csv | 2party-sleep_hetero_test_2.csv |
2.3、基于pipline进行两方加密训练
from pipeline.backend.pipeline import PipeLine
from pipeline.component import DataTransform
from pipeline.component import Evaluation
from pipeline.component import HeteroLR
from pipeline.component import Intersection
from pipeline.component import Reader
from pipeline.interface import Data
from pipeline.interface import Model
def main(namespace="", has_validate=False, need_evaluation=True):
lr_param = {
"name": "hetero_lr_0",
"penalty": "L2",
"optimizer": "nesterov_momentum_sgd",
"tol": 0.0001,
"alpha": 0.01,
"max_iter": 15,
"early_stop": "weight_diff",
"batch_size": -1,
"learning_rate": 0.15,
"init_param": {
"init_method": "zeros"
},
"sqn_param": {
"update_interval_L": 3,
"memory_M": 5,
"sample_size": 5000,
"random_seed": None
},
"cv_param": {
"n_splits": 5,
"shuffle": False,
"random_seed": 103,
"need_cv": False
}
}
guest = 9999 # 有标签一方作为发起方
host1 = 10000 # 参与方
hosts = [host1]
arbiter = host1
guest_train_data = {"name": "2party-sleep_hetero_train_"+str(guest), "namespace": f"experiment{namespace}"}
host_train_data1 = {"name": "2party-sleep_hetero_train_"+str(host1), "namespace": f"experiment{namespace}"}
guest_eval_data = {"name": "2party-sleep_hetero_test_"+str(guest), "namespace": f"experiment{namespace}"}
host_eval_data1 = {"name": "2party-sleep_hetero_test_"+str(host1), "namespace": f"experiment{namespace}"}
# initialize pipeline
pipeline = PipeLine()
# set job initiator
pipeline.set_initiator(role='guest', party_id=guest)
# set participants information
pipeline.set_roles(guest=guest, host=hosts, arbiter=arbiter)
# define Reader components to read in data
reader_0 = Reader(name="reader_0")
# configure Reader for guest
reader_0.get_party_instance(role='guest', party_id=guest).component_param(table=guest_train_data)
# configure Reader for host
reader_0.get_party_instance(role='host', party_id=host1).component_param(table=host_train_data1)
# define DataTransform components
data_transform_0 = DataTransform(name="data_transform_0", output_format='dense')
# get DataTransform party instance of guest
data_transform_0_guest_party_instance = data_transform_0.get_party_instance(role='guest', party_id=guest)
# configure DataTransform for guest
data_transform_0_guest_party_instance.component_param(with_label=True)
# get and configure DataTransform party instance of host
data_transform_0.get_party_instance(role='host', party_id=hosts).component_param(with_label=False)
# define Intersection components
intersection_0 = Intersection(name="intersection_0")
pipeline.add_component(reader_0)
pipeline.add_component(data_transform_0, data=Data(data=reader_0.output.data))
pipeline.add_component(intersection_0, data=Data(data=data_transform_0.output.data))
train_line = []
train_line.append(data_transform_0)
train_line.append(intersection_0)
last_cpn = None
if has_validate:
reader_1 = Reader(name="reader_1")
reader_1.get_party_instance(role='guest', party_id=guest).component_param(table=guest_eval_data)
reader_1.get_party_instance(role='host', party_id=host1).component_param(table=host_eval_data1)
pipeline.add_component(reader_1)
last_cpn = reader_1
for cpn in train_line:
cpn_name = cpn.name
new_name = "_".join(cpn_name.split('_')[:-1] + ['1'])
validate_cpn = type(cpn)(name=new_name)
if hasattr(cpn.output, "model"):
pipeline.add_component(validate_cpn, data=Data(data=last_cpn.output.data),
model=Model(cpn.output.model))
else:
pipeline.add_component(validate_cpn, data=Data(data=last_cpn.output.data))
last_cpn = validate_cpn
hetero_lr_0 = HeteroLR(**lr_param)
if has_validate:
pipeline.add_component(hetero_lr_0, data=Data(train_data=intersection_0.output.data,
validate_data=last_cpn.output.data))
else:
pipeline.add_component(hetero_lr_0, data=Data(train_data=intersection_0.output.data))
evaluation_data = [hetero_lr_0.output.data]
if has_validate:
hetero_lr_1 = HeteroLR(name='hetero_lr_1')
pipeline.add_component(hetero_lr_1, data=Data(test_data=last_cpn.output.data),
model=Model(hetero_lr_0.output.model))
evaluation_data.append(hetero_lr_1.output.data)
if need_evaluation:
evaluation_0 = Evaluation(name="evaluation_0", eval_type="binary")
pipeline.add_component(evaluation_0, data=Data(data=evaluation_data))
pipeline.compile()
# fit model
pipeline.fit()
if __name__ == "__main__":
main(namespace="", has_validate=True, need_evaluation=True)
同样的将代码传入到fate-9999这个guest节点,执行任务即可训练模型和评估测试,评估结果如下:

对于有标签的一方A,可以选择不和他方进行联邦训练,自行本地训练模型,这里假设A只有3类特征的一类特征,比如A只有energy特征或heartrate特征,训练得到的模型在测试集上的结果如下表,表中同样给出了有标签方只有energy特征或heartrate特征时,和另一方进行纵向联邦训练所得模型在测试集上的结果:
| 训练方式 | acc | recall | precision |
|---|---|---|---|
| 用energy单机训练 | 0.89 | 0.59 | 0.92 |
| 用heartrate单机训练 | 0.82 | 0.23 | 0.84 |
| 用energy纵向联邦 | 0.87 | 0.46 | 0.98 |
| 用heartrate纵向联邦 | 0.88 | 0.46 | 0.98 |
由上表可知,单机训练情况下,用energy类特征数据训练模型的效果要比用heartrate的效果好,说明energy类特征更为重要,纵向联邦学习情况下,用energy类特征和用heartrate类特征训练的效果是一样的,这个很好理解,不管有标签方有啥特征,因为联合了他方,模型都用到了所有特征数据,所以结果将是一样的;对比联邦学习和单机训练的结果可见,当有标签一方本身就持有很重要的energy特征时,它自己训练的结果要比纵向联邦训练的结果好一些,不需要联合他方做训练,而有标签方持有较差的特征heartrate时,联合他方纵向联邦学习训练模型是有益的。当然对于没有标签的一方,纵向联邦学习总是有益的。