【图像去雾】Contrastive Learning for Compact Single Image Dehazing阅读
论文:https://arxiv.org/pdf/2104.09367.pdf https://arxiv.org/pdf/2104.09367.pdf
https://arxiv.org/pdf/2104.09367.pdf
代码:https://github.com/GlassyWu/AECR-Nethttps://github.com/GlassyWu/AECR-Net
提出对比正则化;利用有雾图像和清晰图像的信息作为正负样本。确保恢复的图像远离模糊图像,而更接近清晰图像 。此外,考虑到性能和内存存储之间的权衡,开发了一个基于类自动编码器(AE)框架的紧凑的dehazing网络。
Adaptive mixup enables the information of shallow features from the downsampling part adaptively flow to high-level features from the upsampling one, which is effective for feature preserving.
- 提出了新颖的ACER-Net,通过对比正则化和高度紧凑的自编码器类去雾网络,可以有效地生成高质量的无雾图像。与最先进的方法相比,AECR-Net实现了参数-性能的权衡。
- 该对比正则化作为一种通用的正则化,可以进一步提高各种最先进的去雾网络的性能。
- 所提出的类自编码器(AE)去雾网络中的自适应混合(adaptive mixup)和动态特征增强模块(dynamic feature enhancement)可以分别帮助去雾模型自适应地保持信息流,提高网络的转换能力。

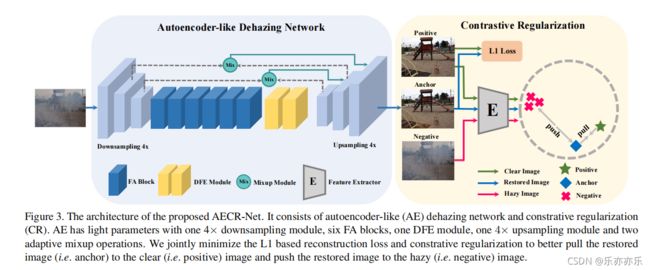
其中 FA Block 来源于FFA-Net中的模块;与FFA-Net不同,显著减少了内存存储,以生成一个紧凑的去雾模型。论文中使用FA 模块作为AE (Autoencoder-like)网络的基本模块。
如上图Figure 3所示,AE-like 网络首先采用4x Downsampling模块,使用一个stride=1的卷积,和两个stride=2 的卷积实现;使密集的FA块在低分辨率空间中学习特征表示。
###### downsample
self.down1 = nn.Sequential(nn.ReflectionPad2d(3),
nn.Conv2d(input_nc, ngf, kernel_size=7, padding=0),
nn.ReLU(True))
self.down2 = nn.Sequential(nn.Conv2d(ngf, ngf*2, kernel_size=3, stride=2, padding=1),
nn.ReLU(True))
self.down3 = nn.Sequential(nn.Conv2d(ngf*2, ngf*4, kernel_size=3, stride=2, padding=1),
nn.ReLU(True))然后利用相应的4× Upsampling 和一个卷积生成恢复后的图像。请注意,这里仅使用6个FA块(与FFA-net中的57个FA块相比),从而显著减少了FA块的数量。
###### upsample
self.up1 = nn.Sequential(nn.ConvTranspose2d(ngf*4, ngf*2, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(True))
self.up2 = nn.Sequential(nn.ConvTranspose2d(ngf*2, ngf, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(True))
self.up3 = nn.Sequential(nn.ReflectionPad2d(3),
nn.Conv2d(ngf, output_nc, kernel_size=7, padding=0),
nn.Tanh())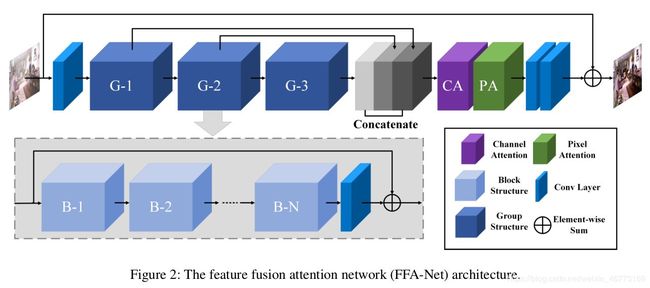
FA模块结构图如下图:
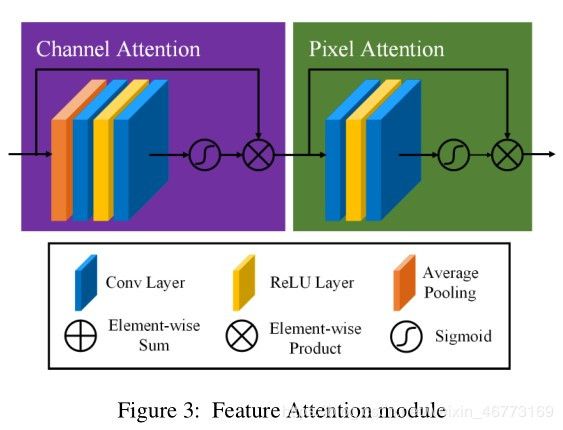
FA Block 的代码:
class PALayer(nn.Module):
def __init__(self, channel):
super(PALayer, self).__init__()
self.pa = nn.Sequential(
nn.Conv2d(channel, channel // 8, 1, padding=0, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(channel // 8, 1, 1, padding=0, bias=True),
nn.Sigmoid()
)
def forward(self, x):
y = self.pa(x)
return x * y
# 通道注意力模块 Channel Attention (CA) Layer
class CALayer(nn.Module):
def __init__(self, channel):
super(CALayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.ca = nn.Sequential(
nn.Conv2d(channel, channel // 8, 1, padding=0, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(channel // 8, channel, 1, padding=0, bias=True),
nn.Sigmoid()
)
def forward(self, x):
y = self.avg_pool(x)
y = self.ca(y)
return x * y
# 参考FFA_Net
# 大多数图像去雾网络对通道和像素特征的处理是平等的,不能处理雾度分布不均匀和加权通道的图像。
# 提出的特征注意由通道注意和像素注意组成,这可以在处理不同类型的信息时提供额外的灵活性。
class DehazeBlock(nn.Module):
def __init__(self, conv, dim, kernel_size, ):
super(DehazeBlock, self).__init__()
self.conv1 = conv(dim, dim, kernel_size, bias=True)
self.act1 = nn.ReLU(inplace=True)
self.conv2 = conv(dim, dim, kernel_size, bias=True)
self.calayer = CALayer(dim)
self.palayer = PALayer(dim)
def forward(self, x):
res = self.act1(self.conv1(x))
res = res + x
res = self.conv2(res)
res = self.calayer(res)
res = self.palayer(res)
res += x
return res为了改善层间的信息流,融合更多的空间结构化信息,提出了两种不同的连接模式:(1)自适应混合,动态融合下采样层和上采样层之间的特征,以保持特征。(2)动态特征增强(DFE)模块通过融合更多的空间结构化信息来增强转换能力。
Figure 4 为Adaptive mixup 结构;
在图像去雾网络中,来自下采样层和上采样层的特征之间的连接缺失了,这导致了浅层特征(如边缘和角)的丢失。使用自适应混合操作来融合来自这两层的信息,以保持特征。如图Figure 4 所示。
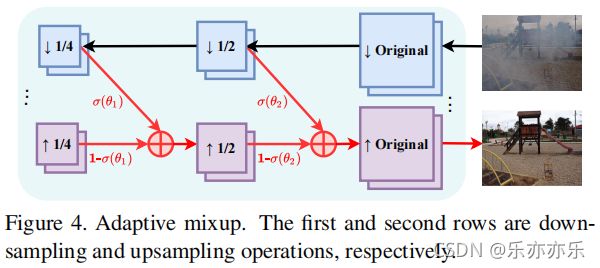
在论文中,考虑两个下采样层和两个上采样层,这样混合操作的最终输出可以表述为:

Adaptive mixup 代码如下所示。其中w(公式中参数θ)是可学习的参数。
# Adaptive mixup
class Mix(nn.Module):
def __init__(self, m=-0.80):
super(Mix, self).__init__()
w = torch.nn.Parameter(torch.FloatTensor([m]), requires_grad=True)
w = torch.nn.Parameter(w, requires_grad=True)
self.w = w
self.mix_block = nn.Sigmoid()
def forward(self, fea1, fea2):
mix_factor = self.mix_block(self.w)
out = fea1 * mix_factor.expand_as(fea1) + fea2 * (1 - mix_factor.expand_as(fea2))
return out
图Figure 5 动态特征增强模块

引入可变形卷积动态特征增强模块(DFE),以自适应形状扩展感受野,提高模型的转换能力,实现更好的图像去雾。使用了两个可变形的卷积层来使采样网格实现更自由形式的变形。如图Figure 3 黄色模块(DFE)所示。

受对比学习(对于给定的锚点,对比学习的目标是将锚拉到接近正点附近,并将锚推离表示空间中的负点。)的影响,作者提出了一种新的对比正则化(CR)来生成更好的恢复图像。因此,需要考虑CR中的两个方面:一是构造“正”对和“负”对,二是找到这些对的潜在特征空间进行对比。

为简单起见,我们将恢复的图像、清晰图像和模糊图像分别称为Anchor、Positive、Negative。
于是公式(1)就可以变成公式(3)这种形式:

为了提高对比能力,我们从固定的预训练模型的不同层中提取了隐藏的特征。因此总体损失如公式(4)所示:

与CR相关的是感知损失(perceptual loss)。感知损失通过利用从预先训练过的深度神经网络中提取的多层特征来测量预测和ground truth之间的视觉差异。与正向正则化的感知损失不同,我们也采用有雾图像(去雾网络的输入)作为负图像来约束解空间。实验证明了CR对于图像去雾优于感知损失。
实验部分:
与SOTA方法对比:

消融实验:

完整代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import init
import functools
from deconv import FastDeconv
def default_conv(in_channels, out_channels, kernel_size, bias=True):
return nn.Conv2d(in_channels, out_channels, kernel_size, padding=(kernel_size // 2), bias=bias)
# https://blog.csdn.net/weixin_46773169/article/details/105462644
# Pixel Attention Layer
class PALayer(nn.Module):
def __init__(self, channel):
super(PALayer, self).__init__()
self.pa = nn.Sequential(
nn.Conv2d(channel, channel // 8, 1, padding=0, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(channel // 8, 1, 1, padding=0, bias=True),
nn.Sigmoid()
)
def forward(self, x):
y = self.pa(x)
return x * y
# 通道注意力模块 Channel Attention (CA) Layer
class CALayer(nn.Module):
def __init__(self, channel):
super(CALayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.ca = nn.Sequential(
nn.Conv2d(channel, channel // 8, 1, padding=0, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(channel // 8, channel, 1, padding=0, bias=True),
nn.Sigmoid()
)
def forward(self, x):
y = self.avg_pool(x)
y = self.ca(y)
return x * y
# 参考FFA_Net
# 大多数图像去雾网络对通道和像素特征的处理是平等的,不能处理雾度分布不均匀和加权通道的图像。
# 提出的特征注意由通道注意和像素注意组成,这可以在处理不同类型的信息时提供额外的灵活性。
class DehazeBlock(nn.Module):
def __init__(self, conv, dim, kernel_size, ):
super(DehazeBlock, self).__init__()
self.conv1 = conv(dim, dim, kernel_size, bias=True)
self.act1 = nn.ReLU(inplace=True)
self.conv2 = conv(dim, dim, kernel_size, bias=True)
self.calayer = CALayer(dim)
self.palayer = PALayer(dim)
def forward(self, x):
res = self.act1(self.conv1(x))
res = res + x
res = self.conv2(res)
res = self.calayer(res)
res = self.palayer(res)
res += x
return res
# DCN 可变性卷积
from DCNv2.dcn_v2 import DCN
class DCNBlock(nn.Module):
def __init__(self, in_channel, out_channel):
super(DCNBlock, self).__init__()
self.dcn = DCN(in_channel, out_channel, kernel_size=(3,3), stride=1, padding=1).cuda()
def forward(self, x):
return self.dcn(x)
# Adaptive mixup
class Mix(nn.Module):
def __init__(self, m=-0.80):
super(Mix, self).__init__()
w = torch.nn.Parameter(torch.FloatTensor([m]), requires_grad=True)
w = torch.nn.Parameter(w, requires_grad=True)
self.w = w
self.mix_block = nn.Sigmoid()
def forward(self, fea1, fea2):
mix_factor = self.mix_block(self.w)
out = fea1 * mix_factor.expand_as(fea1) + fea2 * (1 - mix_factor.expand_as(fea2))
return out
class Dehaze(nn.Module):
def __init__(self, input_nc, output_nc, ngf=64, use_dropout=False, padding_type='reflect'):
super(Dehaze, self).__init__()
###### downsample
self.down1 = nn.Sequential(nn.ReflectionPad2d(3),
nn.Conv2d(input_nc, ngf, kernel_size=7, padding=0),
nn.ReLU(True))
self.down2 = nn.Sequential(nn.Conv2d(ngf, ngf*2, kernel_size=3, stride=2, padding=1),
nn.ReLU(True))
self.down3 = nn.Sequential(nn.Conv2d(ngf*2, ngf*4, kernel_size=3, stride=2, padding=1),
nn.ReLU(True))
###### FFA blocks
self.block = DehazeBlock(default_conv, ngf * 4, 3)
###### upsample
self.up1 = nn.Sequential(nn.ConvTranspose2d(ngf*4, ngf*2, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(True))
self.up2 = nn.Sequential(nn.ConvTranspose2d(ngf*2, ngf, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(True))
self.up3 = nn.Sequential(nn.ReflectionPad2d(3),
nn.Conv2d(ngf, output_nc, kernel_size=7, padding=0),
nn.Tanh())
self.dcn_block = DCNBlock(256, 256)
self.deconv = FastDeconv(3, 3, kernel_size=3, stride=1, padding=1)
self.mix1 = Mix(m=-1)
self.mix2 = Mix(m=-0.6)
def forward(self, input):
x_deconv = self.deconv(input) # preprocess
x_down1 = self.down1(x_deconv) # [bs, 64, 256, 256]
x_down2 = self.down2(x_down1) # [bs, 128, 128, 128]
x_down3 = self.down3(x_down2) # [bs, 256, 64, 64]
x1 = self.block(x_down3)
x2 = self.block(x1)
x3 = self.block(x2)
x4 = self.block(x3)
x5 = self.block(x4)
x6 = self.block(x5)
x_dcn1 = self.dcn_block(x6)
x_dcn2 = self.dcn_block(x_dcn1)
x_out_mix = self.mix1(x_down3, x_dcn2)
x_up1 = self.up1(x_out_mix) # [bs, 128, 128, 128]
x_up1_mix = self.mix2(x_down2, x_up1)
x_up2 = self.up2(x_up1_mix) # [bs, 64, 256, 256]
out = self.up3(x_up2) # [bs, 3, 256, 256]
return out
# 返回的是Figure 3 中的Anchor