【三】多智能体强化学习(MARL)近年研究概览 {Analysis of emergent behaviors(行为分析)_、Learning communication(通信学习)}
相关文章:
【一】最新多智能体强化学习方法【总结】
【二】最新多智能体强化学习文章如何查阅{顶会:AAAI、 ICML }
【三】多智能体强化学习(MARL)近年研究概览 {Analysis of emergent behaviors(行为分析)_、Learning communication(通信学习)}
【四】多智能体强化学习(MARL)近年研究概览 {Learning cooperation(协作学习)、Agents modeling agents(智能体建模)}
下面遵循综述 Is multiagent deep reinforcement learning the answer or the question? A brief survey 对多智能体强化学习算法的分类方法,将 MARL 算法分为以下四类:
- Analysis of emergent behaviors(行为分析)
- Learning communication(通信学习)
- Learning cooperation(协作学习)
- Agents modeling agents(智能体建模)
下面我将分别按照时间顺序对这四类算法中的一些典型工作进行详细讨论。
1. 行为分析
行为分析类别的算法主要是将单智能体强化学习算法(SARL)直接应用到多智能体环境之中,每个智能体之间相互独立,遵循 Independent Q-Learning [2] 的算法思路。本类别的工作相对来说比较早期,这里主要讨论以下两个工作:
[1] Tampuu, Ardi, et al. "Multiagent cooperation and competition with deep reinforcement learning." PloS one 12.4 (2017): e0172395.
[2] Gupta, Jayesh K., Maxim Egorov, and Mykel Kochenderfer. "Cooperative multi-agent control using deep reinforcement learning" International Conference on Autonomous Agents and Multiagent Systems . Springer, Cham, 2017.
1.1 论文标题:Multiagent Cooperation and Competition with Deep Reinforcement Learning
论文链接:https://arxiv.org/abs/1511.08779

这篇文章首次将 DQN 算法与 IQL 结合起来,并将其应用到 ALE 环境中的 Pong 游戏中(该游戏内部场景如下图所示,图片来源原论文)。
在这样一个环境中,每个智能体拥有独立的 Q network,独自采集数据并进行训练,都有对环境的全局观察,动作空间包含以下四个维度:上移、下移、保持不动以及击球(或称为开始游戏)。
作者为了全面的观察将 DQN 应用到多智能体环境下的各方面表现,通过设计回报函数的方式设计了完全协作环境、完全竞争环境以及非完全协作/竞争环境。具体回报函数设计如下:
-
完全协作环境:一方失球,则两方均获得 -1 的回报
-
完全竞争环境:一方失球,该方获得 -1 的回报;对方获得 +1 的回报
-
非完全协作/竞争环境:一方失球,该方获得 -1 的回报;对方获得 的回报
最终的实验结果表明,在完全协作环境中,智能体学到的策略是尽可能长时间的不失球;而在完全竞争环境中,智能体学到的是如何更好的得分(即让对方失球)。
从这个结果可以看出,在将 DQN 直接应用到多智能体环境中,也能够达到一个比较好的性能,即便 IQL 算法是一个十分简单的算法,没有办法处理环境非平稳问题,但是依旧是一个比较强的基准算法。
由于是一篇比较早期的多智能体论文,因而文中还提到了一些比较有用的实验部分的细节问题:
-
Q 值的收敛与否一定程度上反映了 DQN 算法的收敛与否
-
在训练之前首先随机在环境中采样一些 state 作为测试集,监控这些 state 对应的最大的 Q 值平均值来判断算法收敛与否
1.2论文标题:Cooperative Multi-Agent Control Using Deep Reinforcement Learning
论文链接:https://platformlab.stanford.edu/pdf/ALA2017_Gupta.pdf

本文将基于值函数的算法 DQN、基于策略梯度的算法 TRPO 以及演员-评论家算法 DDPG 与 IQL 算法以及循环神经网络(或前向神经网络)相结合,应用到局部观察的多智能体环境中。
其与前一篇 paper 的区别在于,为了增加算法在大规模场景下的可扩展性, 所有的智能体都共享同一套参数。训练时所有智能体采样得到的样本进行汇总,用来更新共享的模型参数。
同时,为了进一步保证不同的智能体即使在共享参数的情况下也能够表现出不同的行为,其模型输入除了局部的观察外,还 包括自身的索引。实验用到的仿真环境如下:
实验结果表明,在使用前向神经网络构建模型时,基于策略梯度的 TRPO 算法在最终性能上超越了另外两种算法;另外,使用循环神经网络构建模型时,性能超过使用前向神经网络的情况。
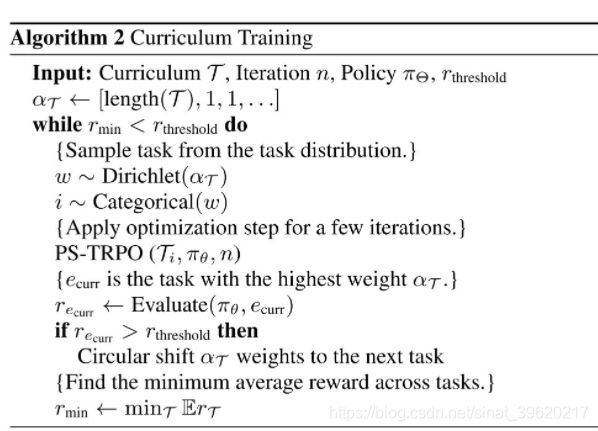
最后,文章还提出了一种课程学习的训练方法:假设我们的课程学习环境是先从 2 个智能体开始训练,逐渐增加到最多 10 个智能体。
我们首先 构建一个迪利克雷分布,该分布的概率密度函数最大值点初始偏向于较少的智能体个数,每一次训练时都从这个分布中采样智能体的个数并进行强化学习算法的训练,直到算法在这些采样出的环境中的性能都达到了某个阈值。
那么接下来我们就改变迪利克雷分布的参数,来使得其概率密度函数最大值点逐渐偏向于较多的智能体个数。循环上述过程直到算法在 10 个智能体上也能达到比较好的性能,这样我们就完成了课程学习。
具体算法流程如下(图片来源原论文):
2.通信学习
这一类别的多智能体强化学习方法显式假设智能体之间存在信息的交互,并在训练过程中学习如何根据自身的局部观察来生成信息,或者来确定是否需要通信、与哪些智能体通信等等。在训练完毕后运行的过程中,需要显式依据其余智能体传递的信息来进行决策。
此部分主要讨论以下五个工作:
[1] Foerster, Jakob, et al. "Learning to communicate with deep multi-agent reinforcement learning" Advances in Neural Information Processing Systems . 2016.
[2] Sukhbaatar, Sainbayar, and Rob Fergus. "Learning multiagent communication with backpropagation" Advances in Neural Information Processing Systems . 2016.
[3] Peng, Peng, et al. "Multiagent bidirectionally-coordinated nets for learning to play starcraft combat games" arXiv preprint arXiv:1703.10069 2 (2017).
[4] Jiang, Jiechuan, and Zongqing Lu. "Learning attentional communication for multi-agent cooperation" Advances in Neural Information Processing Systems . 2018.
[5] Kim, Daewoo, et al. "Learning to Schedule Communication in Multi-agent Reinforcement Learning" arXiv preprint arXiv:1902.01554 (2019).
2.1 论文标题:Learning to Communicate with Deep Multi-Agent Reinforcement Learning
论文链接:https://arxiv.org/abs/1605.06676
这篇文章最先在深度多智能体强化学习中引入通信学习,其解决的强化学习问题是 Dec-POMDP 问题。换句话说,在 Dec-POMDP 中,所有智能体共享一个全局的回报函数,所以是一个完全协作环境,每个智能体只拥有自己的局部观察。文中假设通信信道是离散的,即智能体之间只能能传递离散的信息(即 one-hot 向量)。
本文采用的是 CTDE 框架(即中心化训练去中心化执行,Centralized Training Decentralized Execution),在训练时不对智能体之间的信息传递进行限制(由于是中心化的训练器,所以智能体之间的信息传递完全由这个训练器接管),甚至在训练时可以使用连续的信息。
但是训练完毕之后运行时,智能体之间才进行真正的通信,并且该通信信道是离散(如果训练时是连续的,则在运行时要对信息进行离散化)的。
本文提出了两种算法,后一种是前一种的改进版本,具体名称陈列如下:
Reinforced Inter-Agent Learning (RIAL)
Differentiable Inter-Agent Learning (DIAL)
下面对这两种算法分别讨论。
2.1.1 RIAL
由于本文限定通信信道是离散的,因而 RIAL 算法将生成的信息也作为一个离散的动作空间来考虑,并设定信息的维度为 ,并且原始的动作空间的维度为 。
RIAL 算法将 DRQN 算法与 IQL 算法结合起来,并显式在智能体之间传输可学习的信息来增加智能体对于环境的感知,从而解决 IQL 面临的因为环境非平稳所带来的性能上的问题。但如果只使用一个 Q network,那么总的动作空间的维度就是 。
为了解决这一问题,RIAL 算法使用了两个 Q-network,分别输出原始的动作以及离散的信息。并且 RIAL 算法中 Q network 的输入不仅仅是局部观察,还包括 上一时间步其余智能体传递过来的信息。
另外还需提及的一点是,在多智能体环境中,采用 Experience Replay 反而会导致算法性能变差。这是因为之前收集的样本与现在收集的样本,由于智能体策略更新的原因,两者实际上是从不同的环境中收集而来,从而使得这些样本会阻碍算法的正常训练。
也有许多工作解决这一问题,但由于本文时间较早,因而只是简单的禁用 Experience Replay,但这将大大降低算法的数据有效性。算法框架如下图所示(图片来源原论文):
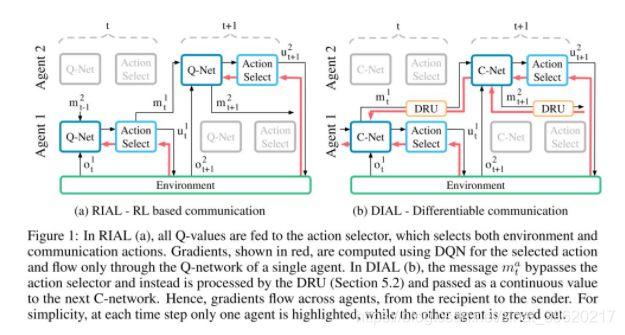
另外,为了算法的可扩展性以及充分利用中心化学习的优势,RIAL 算法可以更改为每个智能体共享同一套模型参数,并且为了进一步对在任务中扮演不同觉得的智能体进行分辨,在 Q network 的输入中还可以额外加入智能体的索引号(可以看到前面讨论的 Cooperative multi-agent control using deep reinforcement learning [3] 同样借用了这种改进方案)。
2.1.2 DIAL
虽然 RIAL 算法可以在智能体之间共享参数,但它仍然没有充分利用中心化训练的优势。而且,智能体不会互相提供,有关其接收到的信息的发送方智能体的通信行为的反馈。
然而人类交流富有紧密的反馈循环。例如,在面对面互动时,听众会向发言者反馈一些非语言信息(例如眼神,微动作等),表明理解和兴趣的程度。RIAL 算法缺乏这种反馈机制,但是后者对于通信学习是非常重要的。
所以本文在 RIAL 的基础上提出了一种新的算法 DIAL,该算法通过通信信道讲梯度信息从信息接收方传回到信息发送方。
具体来说,在中心化训练时,信息发送方的信息动作输出直接连接到信息接收方,并且为了能够实现端到端训练,此时的信息将不再是离散值而是连续值。训练完毕之后执行时,通过这个实值的正负进行 one-hot 离散化。
其具体算法框架如上图所示。同时为了增加算法的鲁棒性,这个信息实值是从一个拥有固定方差的高斯分布中采样而来,该分布的均值即信息发送方生成的实值。
2.2.论文标题:Learning Multiagent Communication with Backpropagation
论文链接:https://arxiv.org/abs/1605.07736

本文与上文是同时期的不同工作(两者发布到 arXiv 上的时间只相差一天)。本文假设智能体之间传递的消息是连续变量(不像 RIAL 或者 DIAL 是离散的),文章采用的强化学习算法应该是 policy gradient 方法(论文本身没有指明,这个结论是从网络结构上推断而出)。
本文解决的也同样是 Dec-POMDP 问题,遵循的是中心化训练中心化执行 CTCE(Centralized Training Centralized Execution)框架,因而在大规模的多智能体环境下,由于网络输入的数据维度过大,会给强化学习算法的训练带来困难。
算法被命名为 CommNet,其框架如下图所示(图片来源原论文)
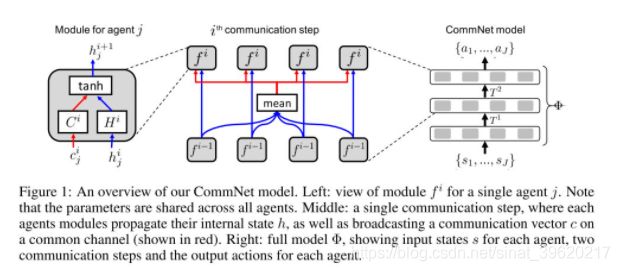
该框架中所有灰色模块部分的参数均是所有智能体共享的,这一定程度上提升了算法的可扩展性。从上图可以看出,算法接收所有智能体的局部观察作为输入,然后输出所有智能体的决策(其实整个框架有一点图神经网络的意思,这里使用的聚合函数就是 mean 函数,然后整个图是一个星状图)。
本算法采用的信息传递方式是采用广播的方式,文中认为可以对算法做出些许修改,让每个智能体只接收其相邻 个智能体的信息。
拿上图中间的框架图来说明,即上层网络每个模块的输入,不再都是所有智能体消息的平均,而是每个模块只接受满足条件的下层消息的输出,这个条件即下层模块对应的智能体位于其领域范围内。 这样通过增加网络层数,即可增大智能体的感受野(借用计算机视觉的术语),从而间接了解全局的信息。
除此之外,文中还提出了两种对上述算法可以采取的改进方式:
-
可以对上图中间的结构加上 skip connection,类似于 ResNet。这样可以使得智能体在学习的过程中同时考虑局部信息以及全局信息,类似于计算机视觉领域 multi-scale 的思想
-
可以将灰色模块的网络结构换成 RNN-like,例如 LSTM 或者 GRU 等等,这是为了处理局部观察所带来的 POMDP 问题
2.3 论文标题:Multiagent Bidirectionally-Coordinated Nets: Emergence of Human-level Coordination in Learning to Play StarCraft Combat Games
论文链接:https://arxiv.org/abs/1703.10069
本文提出了一个新的算法 BiCNet,同样假设智能体之间传递的信息是离散的,旨在解决 zero-sum Stochastic Game (SG) 问题(具体在后面讨论)。
算法基于演员-评论家算法框架,使用的是 DDPG 算法,并且考虑到算法在大规模多智能体环境下的可扩展性问题,智能体之间共享模型参数,并且算法假设每个智能体都拥有同样的全局观察(全局状态),这也是本文的局限之一。另外,BiCNet 同样遵循 CTCE 框架。
整体模型结构如下图所示(图片来源原论文)
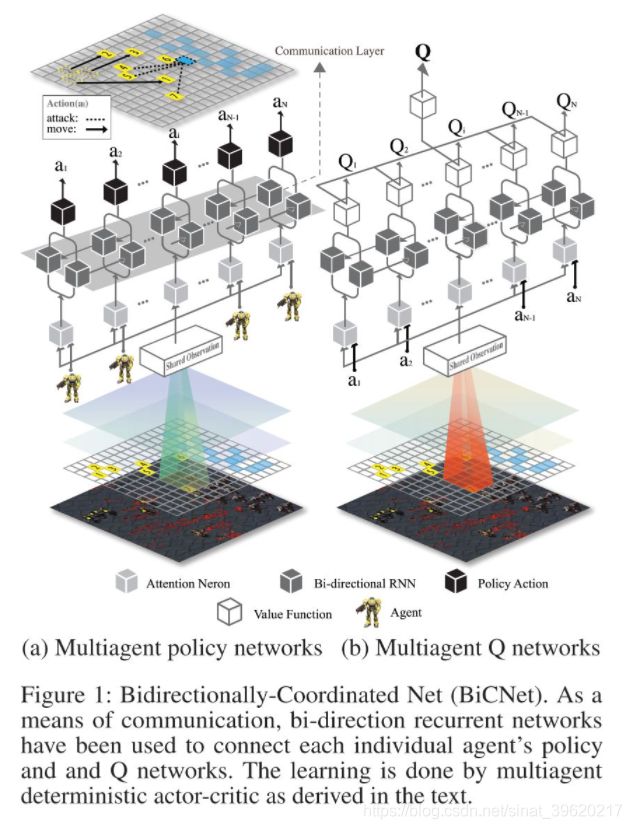
可以看出,BiCNet 通过中间的 Bi-RNN 层进行智能体之间的痛惜。算法伪代码如下(图片来源原论文):

接下来我们聚焦在 BiCNet 解决的问题上,前面说到,BiCNet 是为了解决 zero-sum Stochastic Game(SG)而提出的,一般可以将多智能体竞争环境建模为 SG。一个 SG 可以形式化地被如下元组定义:
其中 s代表被所有智能体共享的全局状态; 和 n代表竞争双方的智能体数目; 和 则分别代表两方智能体的动作空间; p代表全局状态转移概率,r 则是智能体 接收到的环境回报。
在 SG 中,对于某一方来说,其实是一个完全协作问题。为此,我们设计如下的全局回报函数:
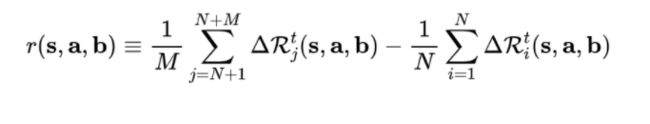
其中:
对于我方智能体来说,其目标是最大化这样一个全局的期望累积回报;而对于敌方智能体来说,其目标则是最小化这样一个全局的期望累积回报。因而,我们就有了一个 Minimax game,对应的最优的 Q value 如下:
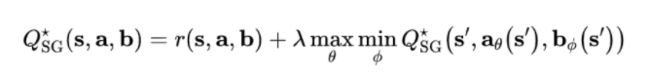
对于这样一个 minimax game,我们可以采用虽然可以采用 Minimax Q-Learning 这样的算法来去解决,但是对于复杂的高维多智能体环境,前者基本无法处理。
因而在本文中假设地方的 policy 是固定的(即敌方智能体遵循一个固定的策略,只有己方智能体的策略是不断更新的),所以上述 SG 就转化为了一个 MDP:
那么我们就可以使用类似 DDPG 这样的算法来去解这样一个 MDP 问题。
由于所有的智能体都共享同一套参数,并且对于环境的观察也是共享的全局观察,那么对于特定任务(例如足球比赛),如何体现智能体在角色上的差别呢?BiCNet 算法做出了以下两点改进:
-
设计新的回报函数
-
固定智能体在 Bi-RNN 的位置
对于第一点,我们展开讲一下(第二点比较直观),BiCNet 采用了类似后面要讲的 MADDPG 算法的方法(由于是不同多智能体算法类别内按时间顺序排列,类别之间的论文并没有按照时间先后顺序排列,所以这里会出现之后发表的工作反而先讨论的情况),每个智能体都拥有自己独立的回报函数:
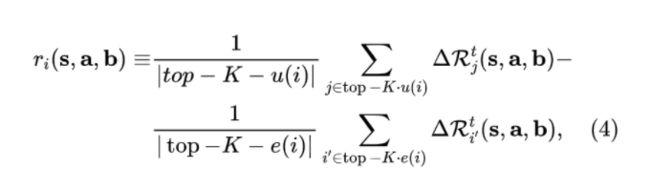
这里的 top-K 论文没有具体说明如何选取,这里可以认为按照距离选取等。那么每个智能体也都拥有自己的 Q-value (虽然所有的智能体共享同一个 RNN,但是也因为这个原因,所以排在不同位置的智能体可以看成拥有不同的 Q-network),即:
这里说明一下,即使每一个智能体共享一个全局回报,这里所说的情况依然会发生,这也是为什么智能体可以通过放在 Bi-RNN 的不同位置来体现其在任务中扮演的角色的不同;而每个智能体使用不同的回报函数,只是增大了这种智能体之间的差异。
计算得到不同的 bellman errors 之后,就可以采用下述多智能体梯度定理(本文提出的,因为本文使用的 RNN 包含共享参数)以及 BPTT 来更新模型参数了
: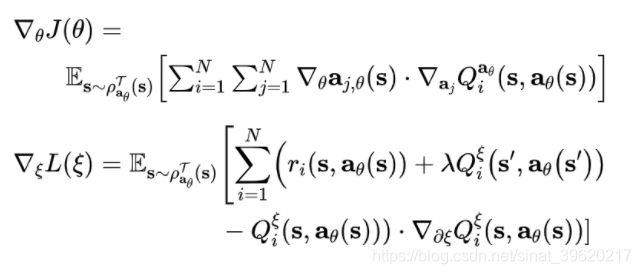
换句话说,BiCNet 中所有的智能体都拥有独立的回报函数以及 Q-network 以及 policy network,但这些 network 中部分参数是共享的。这些智能体一起在环境中进行数据采样,最后将所有的数据集中起来,更新他们的共享部分的参数。
所以这样一看,将 BiCNet 和 MADDPG 相比较,其实就是共享 Q-network 以及 policy network 的拥有特定网络结构的 MADDPG?
2.4 论文标题:Learning Attentional Communication for Multi-Agent Cooperation
论文链接:https://arxiv.org/abs/1805.07733
前面我们讨论的三种算法,R(D)IAL、CommNet 以及 BiCNet,都是每一个时间步所有智能体之间都要进行通信,或者每个智能体与自己相邻的智能体进行通信,这在本文看来属于一个预定义的通信模式,不够灵活。
本文的出发点正是基于此,希望提出一个算法, 能够让智能体在任何时刻,自己决定是否需要与其他智能体进行通信,以及与哪些智能体进行通信。
本文为了达到上述目标,提出了一个基于注意力机制的通信模型 ATOC,该模型基于智能体的局部观察,可同时适用于协作环境(共享一个全局的回报函数或者拥有各自的回报函数)以及竞争环境(实质也是协作环境,因为算法只控制一方)。
其基本思想是,通过其局部观察与动作( 其实是策略网络的中间层输出)的编码,来决定其是否需要与其视野范围内的其他智能体进行通信,以及哪些智能体进行通信。
对于决定进行通信的智能体,我们称之为发起者(initiator),这个发起者从其视野范围内选择协作者共同形成一个通信群组,这个通信群组在整个 episode 中动态变化并且只在需要的时候存在。
本文采用一个双向的 LSTM 网络作为通信群组之间的通信信道(类似于 BiCNet),这个 LSTM 以通信群组中各个智能体的局部观察与动作的编码(之前提到的)作为输入,输出的 higher-level 的编码信息作为各智能体策略网络的额外输入,来指导协作策略的生成。
ATOC 算法采用的是演员-评论家框架,DDPG 算法,遵循 CTDE 框架,同时考虑到算法在大规模多智能体环境下的可扩展性,所有智能体共享策略网络、注意力单元以及通信信道的参数(parameter sharing 好像已经是标准设置了)。
整个算法的模型框架如下图所示(图片来源原论文):
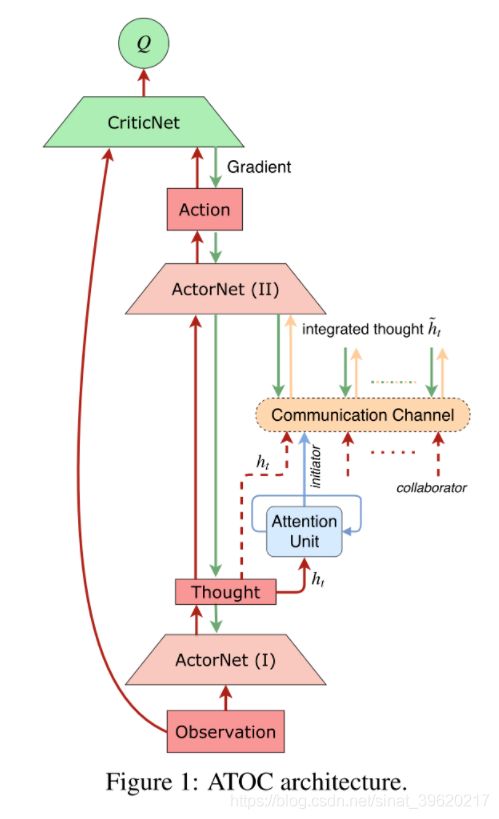
这里注意力模块来决定自身是否要成为发起者,但是并不是每一个时间步都需要做这样一个判断,而是每隔固定的 个时间步,这是因为协作策略需要持续一段时间才能看到效果。注意力模块的训练过程是完全独立于整个强化算法的训练过程的,即注意力模块并不是通过端到端的方式来训练的。
具体来说,注意力模块是一个 RNN 网络,在每隔一个时间步(其实在环境中是 个时间步),其以上一步的隐状态以及这一步智能体局部观察以及动作的编码作为输入,输出端是一个二分类器,判断其是否要成为发起者。
训练数据通过以下方式获得:对于每一个发起者及其通信群组,我们计算其通信群组中每一个智能体采用协作动作(即使用编码作为额外输入得到的动作)与不采用协作动作在 Q-value 上带来的差值的平均值:
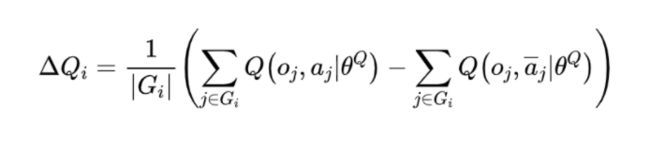
然后我们将元组 存起来作为训练集,在一个 episode 结束之后,对训练集中的数据采用下述二分类交叉熵损失函数进行拟合:
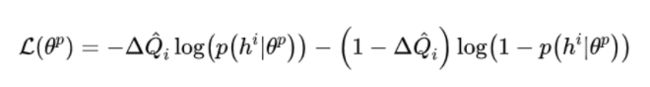
而强化部分则按照标准流程进行,算法伪代码如下(图片来源原论文):

最后来说明以下为什么 ATOC 算法要选择视野范围之内的智能体建立通信群组,主要有以下两点原因:
邻近的智能体的局部观察更加相似,因而更容易互相理解
邻近的智能体之间更容易协作
一个发起者邻近的智能体可以分为以下三种:
其他发起者
被其他发起者选定的智能体
没有被其他发起者选定的智能体
每个发起者最多选择 个智能体,选择的优先级:没有被其他发起者选定的智能体 > 被其他发起者选定的智能体 > 其他发起者。当一个智能体同时被多个发起者选择,则会同时在所有的通信群组中起作用。
具体来说,假定智能体 同时被发起者 a和 b顺序选中,则其首先会加入到发起者 a的通信群组中,生成一个对应的编码:
这相当于智能体 的编码被更新了一次;接着它再参与到发起者 的通信群组中,再次更新自己的编码,并且上一次更新后的编码也会影响群组中其余智能体的编码更新:
这样,这种处于交界处的智能体就会起到一个信息桥梁的作用,使得局部的信息按照顺序逐步的传递到全局( 但是这种传递遵循某个特定的顺序)。
另外,与 BiCNet 相比,ATOC 有以下相似以及改进点:
为了进一步凸显不同智能体在特定任务中的不同定位,固定其在 LSTM 中的位置
将 RNN 通信信道改为 LSTM,从而过滤掉无关信息
最后,ATOC 在竞争环境下的训练方式是与 baseline 对抗训练,而不是分别 self-play 最后再进行比较。
2.5 论文标题:Learning to Schedule Communication in Multi-agent Reinforcement Learning
论文链接:https://arxiv.org/abs/1902.01554

与 ATOC 相比,这篇工作关注的是另外一个问题。这里同样从 R(D)IAL、CommNet 以及 BiCNet 算法出发,这三种算法在每一个时间步所有的智能体之间都参与通信,或者是类似于 R(D)IAL 这样智能体两两之间相互传递信息,或者是像 CommNet 以及 BiCNet 这样所有的智能体都将自己的信息发送到通信信道中参与高级信息的生成。
但是在现实情况中,通信信道的带宽是有限的,如果所有智能体都往这个有限带宽的信道中发送信息,则容量一旦超出,就会出现信息丢失或者阻塞等等情况。ATOC 是通过限制每个发起者只能选择最多 个智能体加入到通信群组中,但是其选取的方式十分简单。本文将通信领域 MAC (Medium Access Control) 方法引入到多智能体强化学习中,来解决上述问题。
本文提出的 SchedNet 算法,同样是解决 Dec-POMDP 问题,并遵循 CTDE 框架,基于演员-评论家算法。
具体来说,整个算法的框架如下图所示(图片来源原论文):
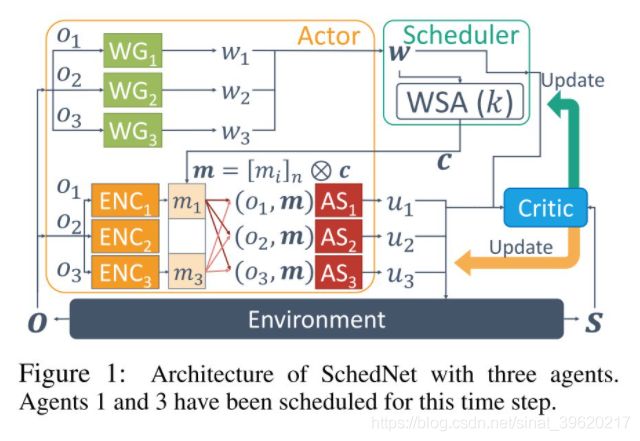
整个框架分为三个部分,Actor 网络,Scheduler 以及 Critic 网络。对于 actor 网络部分,每一个智能体都有其独立的 actor 网络,该网络分为以下三个部分:
信息编码器(message Encoder):
动作选择器 (Action Selector):action selector
权重生成器(Weight Generator):
是一个 mask 向量,代表哪些智能体能够将自己的信息发送到通信信道上, 表示拼接操作。例如, 并且 则 。
那么当每个智能体生成自己的权重之后,算法如何根据权重来生成 mask 向量 呢?这里就涉及到 Scheduler 部分的 WSA(Weight- based Scheduling Algorithm)模块。具体来说,WSA 模块采用了两种在通信领域简单但高效地分配算法:
-
Top(k):顾名思义,选择权重排名靠前的智能体
-
Softmax(k):先将权重通过 softmax 函数转化为一个概率分布,再从这个概率分布中进行采样
WSA 模块的主要问题是,在中心化训练时我们自然可以收集到所有智能体的权重,但是在去中心化执行时,如何运行 WSA 模块呢?本文表明去中心化的 WSA 是目前通信领域的研究热点,具体方法可参见论文附录部分,因为内容不在本文讨论范围之内,就不详细展开了。
最后是 Critic 模块,该模块包含两个 heads,具体框架如下(图片来源原论文):
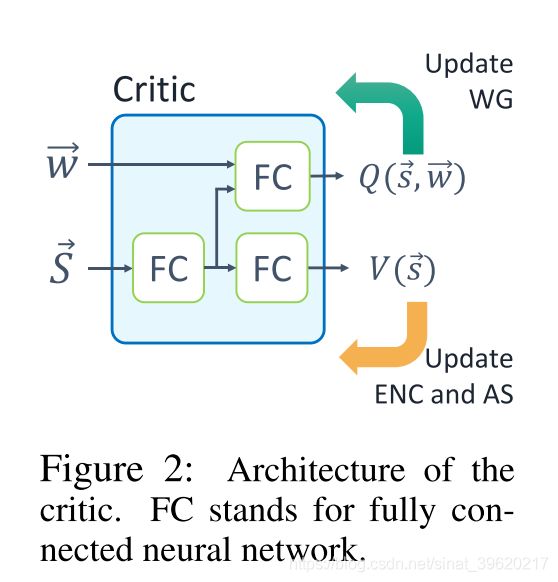
注意这里有两个 heads 是因为在 SchedNet 中要训练两个不同的 policy,其中一个 policy 是权重生成器,它的动作空间是连续的,因而本文使用了 DDPG 算法,所以需要 Q value。
另一个 policy 则是真正的policy,它的动作空间是离散的,因而本文使用了普通的 actor-critic 算法,并且 critic 通过 来计算,这样可以同时保证较小的方差以及偏差,因而需要 state value。
具体的权重生成器的参数以及(动作选择器-信息编码器,这两者当作一个网络的两部分来整体考虑)的参数更新方式如下:
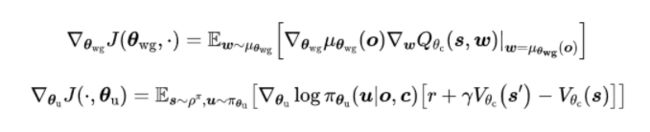
文章参考链接:
https://www.sohu.com/a/380219083_500659
https://blog.csdn.net/weixin_40005454/article/details/111161097