INT303 Big Data 个人笔记
又来到了经典半个月写一个学期内容的环节
目前更新至Lec{14}/Lec14
依旧是不涉及代码,代码请看学校的jupyter notebook~
Lec1 Introduction
介绍课程
| Topic | Range |
|---|---|
| Topic 1: Introduction to Big Data Analytics | Lec1~Lec3 |
| Topic2: Big data collection and visualization | Lec4~Lec5 |
| Topic3: Systems and software | Lec6 |
| Topic 4: Data processing methods and algorithms | Lec7~13 |
| Topic 5: Review | Lec14 |
Lec 2 Data
2.1. What are Data
Where do data come from: Internal sources, exising external sources, external souces requiring collection effors…
Ways to gather online data: API(Application Programming Interface), RSS(Rich Site Summary), Web scraping
2.2. Data Exploration
数据存储的形式:
+Tabular Data:每行表示一次数据记录,每列表示一种特征(measurement)
+Structured Data:以json,xml格式保存的数据
+Semistructured Data:半结构化数据,数据的键不一致,或有部分数据不是键值对形式
数据的形式:
数字,布尔值,字符串,时间,列表,字典
2.1.1. Tabular data
每列又叫做variable,attribute,features,列的数量叫做dimension,通常来讲希望每列只表示一种feature。
使用pd.read_csv()读取csv
- Quantitative variable:数字类型的变量:
- Discrete离散
在任何有界区间内都可能有有限数量的值。
例如:“物体的数量”是一个离散变量 - Continuous连续
在任何有界区间内都可能有无限数量的值。
例如:“身高”是一个连续变量
使用np.linspace()和np.digitize()来将连续变量按区间划分成离散变量
- Discrete离散
- Categorical variable:分类变量:
值之间没有固有的顺序例如:人名是分类变量
可以使用OneHotEncoder或get_dummies()将分类变量变为离散变量
2.3. Data Cleaning
2.3.1. Missing data
三种缺失:
MISSING COMPLETELY AT RANDOM: 丢失的数据完全随机,丢失的概率与自身和其他变量无关
MISSING AT RANDOM:数据随机缺失,但并非完全的缺失,丢失的概率和其他变量有关,例如人群IQ测试的数据集,发现幼儿的IQ数据为空(因为年龄太小没法通过测试)。
NOT MISSING AT RANDOM :非随机丢失,丢失概率和这个变量本身有关
处理缺失:
Delete:移除包含较多遗失数据的记录
Imputation:通过推断得出遗失数据的值
- 设定固定值(0,均值mean,众数mode,中位数median)
- 根据邻居数据点计算均值(KNN)
2.3.2. Messy data format
行列之间有关联

列代表意义不纯
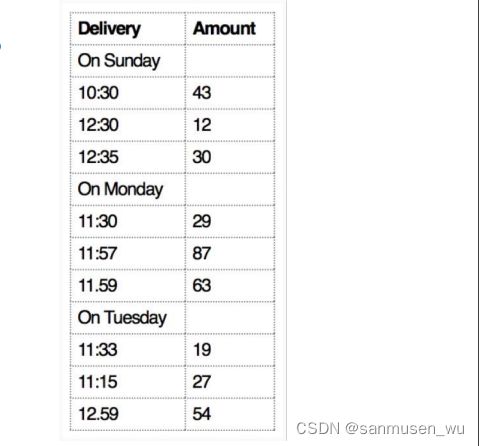
2.3.3. Not usable
略
2.4. Data Descriptive Statistics数据描述性统计
population全体集合
sample样本,采样的概念:A sample is a “representative” subset of the objects or events under study. Needed because it’s impossible or intractable to obtain or compute with population data.
采样产生的偏差Biases:
+Selection bias:由于某些样本的特殊性使得他们更容易被选择
+Volunteer/nonresponse bias:不易获得的样本没法体现代表性
解释了mean和median差别:
mean更容易受极端值(extreme)和异常值(outliers)影响
right-skewed右偏:指某个数据集的mean>median

对于分类数据,使用众数填充
- 使用Range(maximum-minumum)衡量一个数据的分布广度
- 用方差Variance( s 2 = 1 n − 1 ∑ i = 1 n ∣ x i − x ˉ ∣ 2 s^2=\frac{1}{n-1}\sum_{i=1}^{n}|x_i-\bar x|^2 s2=n−11∑i=1n∣xi−xˉ∣2)衡量数据的离散程度
- 标准方差Standard Deviation( s 2 \sqrt{s^2} s2)
Lec3 Data Grammar
Exploratory Data Analysis (EDA):
- 数据存储进方便处理的数据结构
- 确保行代表样本,列代表原子属性(并转成数字类型
- 探索全局属性:使用直方图、散点图和聚合函数来汇总数据
- 探索组属性:将类似的项目分组在一起以比较数据子集(比较结果是否合理/预期)
后面就是在比较使用python的pandas库和不使用库如何操作,涉及文件读取,数据存储,空值检查,数据排序,主要是代码,建议看老师的notebook,此处略
(归一化之前,先划分训练集和测试集,然后对训练集计算归一化参数,直接套用到测试集上)
3.1. Data Concerns
Standardization and normalization 标准化和规范化

Lec4 Data collection
4.1. Web servers
A server is a long running process (also called daemon) which listens on a prespecified port and responds to a request, which is sent using a protocol called HTTP

Example:
• Our notebooks also talk to a local web server on our machines: http://localhost:8888/Documents/cs109/BLA.ipynb#something
• protocol is http, hostname is localhost, port is 8888
• url is /Documents/cs109/BLA.ipynb
• url fragment is #something
4.2. Python data scraping
Why scrape the web?
• companies have not provided APIs
• automate tasks
• keep up with sites
• fun!
Stages:
- INSPECT YOUR DATA SOURCE
观察页面 - SCRAPE HTML CONTENT FROM A PAGE
用request库请求网页内容 - PARSE HTML CODE WITH BEAUTIFUL SOUP
用bs解析网页- result=soup.find(id=“”)
- result=soup.find(“div”,class_=“”)
- result=soup.find(“h2”,string=“”)
- result=soup.find(“div”,string=lambda text:“python” in text.lower())
- parent=result.parent
- link_url=link[“href”]
- text=result.text.strip()
4.2. Application Program Interface
api接口,可以实现对资源的获取,上传等操作
Lec5 Data Visualization
5.1. Visualization motivation
为何需要可视化:
+Anscombe’s Data四重奏:计算均值、标准差、方差、相关系数r,斜率和截距,可以看出四组数据的这些统计值几乎完全一致。

+a picture can be worth a thousand words
+Visualizations help us to analyze and explore the data. They help to:
- Identify hidden patterns and trends
- Formulate/test hypotheses
- Communicate any modeling results
- –Present information and ideas succinctly
- –Provide evidence and support
- –Influence and persuade
- Determine the next step in analysis/modeling
5.2. Principle of Visualization
-
Maximize data to ink ratio: show the data

-
Don’t lie with scale (Lie Factor)(想到手机厂商“吊打友商”的数据)

-
Minimize chart-junk: show data variation, not design variation

-
Clear, detailed and thorough labeling
5.3. Types of Visualization
-
Distribution: how a variable or variables in the dataset distribute over a range of possible values. 研究数值在坐标轴上的分布,用户可以观察到值范围、中心趋势和异常值。
- histogram直方图
- scatter plot散点图
-
Relationship: how the values of multiple variables in the dataset relate,通过颜色形状等表现方式使二维图像展示更多关系,3d数据可以通过圆圈大小显示

-
Comparision: how trends in multiple variable or datasets compare数据集之间的比较
- pie charts 饼状图
- 在同一个图表中绘制多个数据图片,能够清晰地比较数据

- boxpolt 箱图

-
Composition: how a part of your data compares to the whole.数据集部分和数据集整体之间的比较
-
pie chart
-
stacked area graph. This shows the relationship of a categorical variable (AgeGroup) to a quantitative variable (year).

5.4. QA
WHAT ARE SOME IMPORTANT FEATURES OF A GOOD DATA VISUALIZATION?
数据可视化应轻便,必须突出数据的基本方面;看看重要的变量,什么是相对重要的,趋势和变化(trends and changes)是什么。此外,数据可视化必须具有视觉吸引力(visually appealing),但不应包含不必要的信息(unnecessary information)。
人们回答这个问题一定要记住以下几点:
- 最大化数据与图像复杂度的比率:专注于数据
- 不要使用坐标轴缩放撒谎
- 最小化图表:显示数据变化,而不是设计变化
- 清晰、详细和彻底的标签
WHAT IS A SCATTER PLOT?
FOR WHAT TYPE OF DATA IS SCATTER PLOT USUALLY USED FOR?
+A scatter plot散点图 is a chart used to plot a correlation between two or more variables at the same time. It’s usually used for numeric data.
WHAT TYPE OF PLOT WOULD YOU USE IF YOU NEED TO DEMONSTRATE “RELATIONSHIP” BETWEEN VARIABLES/PARAMETERS?
Scatter plots or charts are used to show the relationship between 2 variables. When we are trying to show “relationship” between three variables, bubble charts are used.
Lec6: Infrastructure that supports Big Data processing
6.1. Large-scale computing大规模计算
Issue:假设每台主机能用1000天不坏,那么1000台机子平均每天坏一台,1百万台机子平均每天坏1000台
Issue:通过网络传输数据非常耗时
Idea:
- 备份文件
- bring computation to data后文解释
- Storage Infrastructure - File system 存储结构-文件系统(“通俗地说,文件系统就是一个软件,它负责为用户建立文件,存入、读出、修改、转储文件,控制文件的存取,当用户不再使用时撤销文件等。像这种一台计算机,单个存储节点、一个操作系统,一个具体的文件系统的场景称之为一般文件系统。”)
【https://blog.csdn.net/qq_37862148/article/details/113999206】
6.1.1. STORAGE INFRASTRUCTURE
Issue:If nodes fail, how to store data persistently?
Answer:
- Distributed File System – Provides global file namespace
使用情形:- 大文件 (100s of GB to TB)
- 不需要频繁更新的数据
- 频繁读和添加新数据
6.2. Distributed file system分布式文件系统
(“分布式文件系统中的数据存储在多台机器上,这些专门用来存储数据的机器称之为存储节点,由多个节点构成分布式集群,节点上的小的分布式文件系统组合成总的分布式文件系统,由主服务器对总的文件系统进行管理。用户任意访问某一台主机,都能获取到自己想要的目标文件。”)
【https://blog.csdn.net/qq_37862148/article/details/113999206】

Chunk servers
文件被分割成16到64MB的块(chunks),然后每个chunk都被备份两到三次,将副本chunk存储到不同的rack(子节点)
Master node主节点
维护存储了文件地址的元数据(metadata),主节点可能也会有备份
Client library for file access用户访问文件
查询主节点,随后直接访问chunk server读取数据
关于可靠性reliable的保障:
- Data kept in “chunks” spread across machines
- Each chunk replicated on different machines
- Seamless recovery无缝恢复 from disk or machine failure
“Bring computation directly to the data”:将计算任务直接挂载在负责存储该块数据的chunk server上,免去了主从数据分发的延迟,是一种结合了分布式存储结构和分布式计算的理念
6.3. (重要)MapReduce: Distributed computing programming model
design for:
– Easy parallel programming并行计算
– Invisible management of hardware and software failures软硬件容错
– Easy management of very-large-scale data大规模数据管理
常见的包括MapReduced(谷歌提出的设计理念),Hadoop(Apache开源项目),Spark,Flink,
6.3.1. MapReduce共三步:
- Map,用户定义
map方法映射每组数据(指#6.2. chunk),将每组数据进行处理映射为可并行计算的格式 data chunk →{k1:v1,k2:v2…}- mapper对每个元素应用了该映射方法
- 一个Map任务整合了多个mapper,实现并行计算
- 映射方法输出键值对
- Group,系统将以上键值对排序,合并相同键的键值对,然后输出单键对应的值列表{k1:v1,k2:v2…}→[k1:{v1,…},k2:{v2,…},…]
- Reduce,用户定义
reduce方法,对上述键-值列表 进行操作[k1:{v1,…},k2:{v2,…},…] → output data
流程图如下,注意当ABC线程的任务全部完成后,DE线程的Group任务才可以进行。Group过后,同一个k只会分发到一个线程中

判断题
- Each mapper/reducer must generate the same number of output key/value pairs as it receives on the input. (Wrong) 输入规模都不同,输出规模当然不同
- The output type of keys/values of mappers/reducers must be of the same type as their input. (Wrong) mapper和reducer一个将存储数据变成可计算数据,一个将可计算数据变成存储数据
- The inputs to reducers are grouped by key. (True) reducer之前是grouper,grouper将相同的key合并,他们的value被整合进一个列表
- It is possible to start reducers while some mappers are still running . (Wrong)Group任务需要等所有Map任务结束,而Reducer在Group之后
计数例子:

6.4. Spark: Extends MapReduce
Spark与前文MapReduce区别
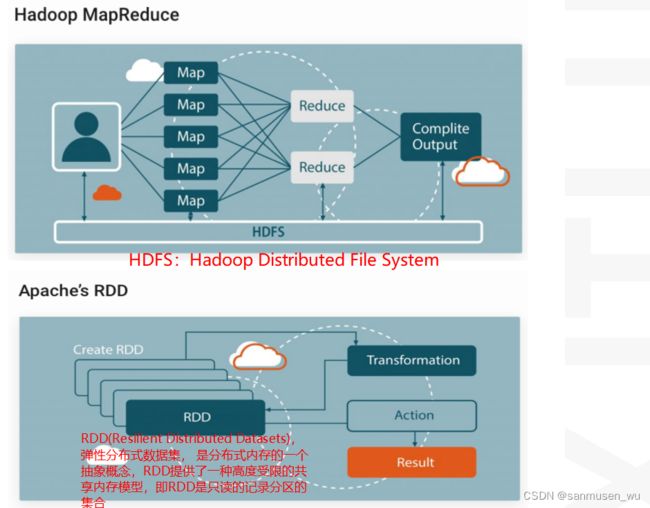
Hadoop Distributed File System(HDFS):
+就是#6.2.分布式文件存储存储
Resilient Distributed Dataset (RDD):
弹性分布式数据集
+Partitioned collection of records,不同于HDFS仅仅将文件划分为多个chunks,RDD将文件存储为只读键值对的形式(因此想要改变数据只能创建新的RDD),同时逻辑上进行分区,存储在内存中,也可checkpoint持久化存储。可在集群中共享(快速)。RDD可由Hadoop创建,也可由其他RDD堆栈创建。最适用于对数据集中的所有元素做统一操作的情形。
Create RDD→Transformation→RDD→Action→Result
Transformation:
+可以从RDD或Hadoop构建新RDD,常用操作:map,filter,join,union,intersection,distinct
+Lazy evaluation: 直到action需要这块RDD数据之前,都不进行transform
Action
应用于RDD,返回值或导出数据,常用操作:count,collect,reduce,save
计数示例:
RDD File →flatMap→单词列表→map→[(word,1),…]→reduceByKey(map + reduce)→[(word,count),…]→save→File

Lec7 Feature Engineering
众多数据存储格式(照片,音频)都可以提取出Features,然后存入机器学习数据库,进行模型训练
7.1. Case study
Click Prediction用户点击广告预测 - Data Model - ML-Ready Dataset - Data Cleaning - Aggregating统计 - Pivoting 分类列转one-hot
7.2. Numerical Features
通常数学模型很容易理解,但特征工程确实是必要的。可以是浮点数, 更容易估算缺失数据,分布distribution和缩放scale对某些模型很重要
对于丢失某些数据的行,可以删除该行,更好的策略是从已知数据推断(#2.3)
- Binarization把离散或连续值变成二类值

- Binning 将数值放进不同的桶中,分为固定宽度桶(Fixed-width binning)和自适应桶(Adaptative or Quantile位数 binning)
- Log transformation 对每个数进行log计算,能够smooth long-tailed data
- Min-max scaling

- Standard(Z)Scaling. 标准化之后,平均数为0,方差为1
- Interaction Features:对于线性模型,可以将feature组合使其能够非线性拟合 y = w 0 + w 1 x 1 + w 2 x 2 + w 3 x 1 2 + w 4 x 1 x 2 + w 5 x 2 2 y = w_0+w_1 x_1+ w_2 x_2 + w_3 x_1^2 +w_4 x_1 x_2+ w_5 x_2^2 y=w0+w1x1+w2x2+w3x12+w4x1x2+w5x22

7.3. Categorical Features
几乎总是需要一些处理才能适合模型,如何种类多会使数据非常稀疏,难以估算丢失的数据
- One-Hot Encoding 把一列有m种类型的分类数据变成m列数值类型数据
- Feature hashing 把字符串哈希成定长的哈希值,然后放进n列中(可能会有冲突
- Bin-counting 不使用实际的分类值,而是在历史数据上使用该类别的全局统计。适用于线性和非线性算法,可能会产生冲突(不同类别的编码相同),小心溢出。下图不适用实际的id值,而使用view数量或点击次数代表

7.4. Temporal Features
Time Zone,许多国家许多时区,Daylight Saving Time夏令时
- Time binning,按照区间划分,比如5点到8点属于Early Morning
- Trendlines,用过去一周或过去一个月代表实际时间点
7.5. Spatial Features
- Spatial variables encode a location in space:GPS,Street Addresses,ZipCodes,Countries
- Derived features:用户距离酒店的距离
7.6. Textual Features
- Natural Language Processing(Clean,Remove,Root,Tokenize,Enrich)
- Text vectorization 将每个文档表示为向量空间中的特征向量,其中每个位置表示一个单词(token),期值是在文档中的相关性。

Cosine Similarity:用夹角表示俩向量相关性,
a ⃗ ⋅ b ⃗ = ∣ ∣ a ⃗ ∣ ∣ ∣ ∣ b ⃗ ∣ ∣ c o s θ \vec a \cdot \vec b=||\vec a||||\vec b||cos\theta a⋅b=∣∣a∣∣∣∣b∣∣cosθ
c o s θ = a ⃗ ⋅ b ⃗ ∣ ∣ a ⃗ ∣ ∣ ∣ ∣ b ⃗ ∣ ∣ cos\theta=\frac{\vec a \cdot \vec b}{||\vec a||||\vec b||} cosθ=∣∣a∣∣∣∣b∣∣a⋅b
7.7. Feature Selection
减少模型复杂度和训练时间
- Filter methods 过滤方法
例如,在每个特征和响应变量之间关联相互信息 - Wrapper methods包装方法
试图优化最佳特征子集(例如”Stepwise Regression逐步回归) - Embedded methods 嵌入式方法
作为模型训练过程一部分的特征选择(例如决策树或树集合的特征重要性)
Lec8 Dimension Reduction降维
8.1. Interaction Terms and Unique Parameterizations
通过叉乘构造新feature,可以将不同维度的影响(multiplicative term)带入模型,使得线性模型可以拟合非线性边界
为了避免过拟合,有时会删去部分feature,但是这些单独feature x1,x2代表主要内容(main effects)是一定会保留下来的
需要构造多少新feature?
对于23列的dataframe:two-way interactions: p ( p − 1 ) 2 = 253 \frac{p(p-1)}{2}=253 2p(p−1)=253, three-way interactions: p ( p − 1 ) ( p − 2 ) 2 ∗ 3 = 1771 \frac{p(p-1)(p-2)}{2*3}=1771 2∗3p(p−1)(p−2)=1771,一共有约百千万个组合
model unidentifiable:样本数过少,而输入特征过多
8.2. Big Data and High Dimensionality
(重要)What is ‘Big Data’:
矩形数据集有两个维度:观察数(observation行数n)和预测数(predictor列数p)。两者都可以在将问题定义为大数据问题方面发挥作用。
-
当n很大,通常不是问题,只是计算需要更久(神经网络能缓解这问题)。通过模型选择和调参以及预训练能够减少训练时间。大n通常解决不了啥
-
当p很大,通常问题很多,这个问题也叫做High Demensionality、unidentifiability、over-specified model,出现于输入维度(包含interaction)接近于样本数的情况:
- 矩阵可能不可逆not invertible(见于OLS)
- 可能存在多重共线性(Multicollinearity)
- 模型容易过度拟合
通常来说只需要n-1个参数就可以预测,(加上bias刚好n个参数)。如果p>n,参数的意义就无法定义(unidentifiable),那么多出来的那p-(n-1)个参数的值无法被准确定义。
一个解决方法是通过结合原始feature创建一个少一点的新的feature集合。构造Z,每个Zi表示所有features的值乘上一种权重(加权求和)。有几个Zi(配上相应的权重)最后转变后的feature就有多少个。假设feature为{A,B,C},权重组合为[[0.1,0.9,0],[0,0.7,0.3]],那么构建出来的两个新feature为{0.1A+0.9B,0.7B+0.3C}

8.3. Principal Components Analysis (PCA)
Principal Components Analysis (PCA) is a method to identify a new set of predictors, as linear combinations of the original ones, that captures the ‘maximum amount’ of variance in the observed data. 此外,PCA是非监督学习,优点是能够解决dimensionality引发的问题、可视化特征、改善拟合模型的计算时间, 缺点是会丢失对系数的解释性(interpretation of coefficients)而且对于模型准确率好像不怎么有用
如同#8.2. 最后提到的解决方法,PCA也是构造Zi:
- 每个Zi是原始predictor的线性组合,其向量范数(长度)为1
- Zi是成对正交(互相垂直)的
- Zi按照captured observed variance的数量降序排列
也就是说,观察到的数据在Z1方向上比在Z2方向上显示出更多的变化。为了实现降维,我们选择PCA的前m个主成分作为我们的新predictor,并根据这些预测因子表达我们的观测数据。
Top PCA components capture the most of amount of variation (interesting features) of the data

转换我们观察到的数据意味着将我们的数据集投影到由前 m 个 PCA 组件定义的空间上,这些组件是我们的新预测器。

8.3.1. (重要)Math behind PCA
Z记为一个n×p的矩阵,包含(Z1,…,Zp列),为PCA的主成向量
X记为一个n×p的矩阵,包含(X1,…,Xp列),为原始的变量(均值0,方差1,不包含intercept)
W记为p×p的矩阵,矩阵的列代表方阵 X T X X^TX XTX的特征向量,那么:
Z n × p = X n × p W p × p Z_{n\times p}=X_{n\times p}W_{p\times p} Zn×p=Xn×pWp×p
实现PCA:
- 正则化Standardize 所有predictors(X),使均值为0,方差为1
- 计算XTX的特征向量(W),按照特征值从大到小排序
- 计算矩阵乘法结果Z=XW
例子:
原始数据矩阵为,每个observation按行排列:
X = [ X 1 X 2 X 3 ] X= \begin{bmatrix} X1 & X2 & X3\\ \end{bmatrix} X=[X1X2X3]

第一步,计算每列均值:
X ˉ = [ 66 60 60 ] = [ x ˉ 1 x ˉ 2 x ˉ 3 ] \bar X= \begin{bmatrix} 66 & 60 & 60\\ \end{bmatrix}= \begin{bmatrix} \bar x_1 & \bar x_2 & \bar x_3\\ \end{bmatrix} Xˉ=[666060]=[xˉ1xˉ2xˉ3]
第二步,计算协方差矩阵covariance matrix:
这里的i指每一列向量
c o v ( X , Y ) = 1 n − 1 ∑ i = 1 n ( X i − x ˉ ) ( Y i − y ˉ ) cov(X,Y)=\frac{1}{n-1}\sum_{i=1}^{n}(Xi-\bar x)(Yi-\bar y) cov(X,Y)=n−11∑i=1n(Xi−xˉ)(Yi−yˉ)
写成矩阵形式为,这里的减法为Boardcast
c o v X = 1 n − 1 ( X − X ˉ ) T ( X − X ˉ ) covX=\frac{1}{n-1}(X-\bar X)^T(X-\bar X) covX=n−11(X−Xˉ)T(X−Xˉ)
简单来说,就是数据矩阵每个元素减去该列均值得到Xnew,然后算XnewTXnew,然后每个元素除以(行数n-1),(但为什么学校PPT是除以n,绷),记为矩阵A

这边除以n-1的实际结果是,后面为了演示方便还是使用学校结果,不过记得是除以n-1
[ 630 450 225 450 450 0 225 0 900 ] \begin{bmatrix} 630 & 450 & 225\\ 450 & 450 & 0\\ 225 & 0 & 900 \end{bmatrix} 63045022545045002250900
第三步,计算A的特征向量Eigenvector和特征值eigenvalues
A v = λ v Av=\lambda v Av=λv
d e t ( A − λ I ) = 0 det(A-\lambda I)=0 det(A−λI)=0
按照第二步学校PPT给出的结果做演示:

3×3矩阵的行列式怎么求(行列式的计算方法总结)

第四步,将特征值从大到小排列
按照上一步计算出来的特征值排一下顺序:
[ 910.06995 629.11039 44.81966 ] \begin{bmatrix} 910.06995\\ 629.11039\\ 44.81966 \end{bmatrix} 910.06995629.1103944.81966
因此,如果PCA求两个主成成分,那么分别是910和629对应的特征向量
pca=PCA().fit(X)# 求特征向量
pcaX=pca.transform(X)# 映射
8.4. PCA for Regression (PCR)
为了降维,只选取主成成分分析后的前M个PCA变量,M取多少非常重要。通常使用Cross Validation(交叉检验)来确定。
8.5. PCA for Imputation
Naive Imputation Methods 朴素插值方法:Lec7提到的用均值补null数据。下图两变量有正相关关系,而补均值会无法体现这种关系

Imputation插补的意义:
- 利用predictor之间的关系,使用其他predictor填补一个空缺的值: links
between variables - 如果发现predictor i和j对于大多数变量具有相似的值,就可以用i填补缺失的j。global similarity between individual observations
使用PCA插补的例子, 如图,1行x2列丢失了一个x2,:
1.第一步是计算这个空处如果填该列均值=0.237166
2. 然后对于整个数据集做PCA分析,投影到主成分向量上,求出在主成分向量上的投影位置project imputation into PCA space(这里是二维,对于更多维数据,需要求主成分在更高维(M)的PCA空间投影位置
3. 把空缺值更新为刚才投影点的高度(缺失值所在的维度)
4. 重复直到不再更新

In practice this method can overfit, especially in a sparse matrix with many missing values. So often a regularized PCA approach is used which shrinks the singular values of the PCA, making updates less aggressive
PCA的解释:
- 在预测变量空间中找到数据变化最大的方向(finding the directions in the predictor space along which the data varies the most
- 找到最接近数据点的低微线性表面(finds a low-dimensional linear surface which is closest to the data points
Matrix Completion:
是PCA的另外一个应用,可以用于填补随机缺失的数据。对于推荐系统非常有效(填补、预测用户没打分过的某个电影的评价,有助于为用户作推荐)
Lec 9 Model Selection and Cross Validation
9.1. Model Selection
Model selection is the application of a principled method to determine the complexity of the model, e.g., choosing a subset of predictors, choosing the degree of the polynomial model etc.
Training Error 训练误差和Test Error 测试误差:
用训练集训练模型,用测试机评估误差
过拟合overfit:Fitting to meaningless patterns in the training set过度拟合是指模型不必要地复杂的现象,即模型的某些部分捕捉了观测中的随机噪声,而不是predictor和response之间的关系。过度拟合会导致模型失去对新数据的预测能力。过拟合发生的条件:there are too many predictors; the coefficients values are too extreme
过拟合引出了交叉predictors的另一个原因:使用一个少量特征的训练集减少过拟合的可能
模型对于新数据的预测能力叫做generalization泛化,模型选择是为了选出一个高泛化能力的、避免过拟合的模型。
9.2. Using Validation
模型选择的四步:
- 把之前的训练集(数据集=训练集+测试集)再分成:训练集train和验证集valid
- 在训练集上训练不同模型,使用验证集评估效果
- 选择最好的模型
- 在测试集test上测试模型最终正确率

选择模型的方法:
• Exhaustive search
穷尽式搜索,把所有可能的模型都试一遍( O ( 2 J ) O(2^J) O(2J))
• Greedy algorithms
迭代式优化模型选择,每次都选择能把评估值更优的模型子集,重复此操作( O ( J 2 ) O(J^2) O(J2))

• Fine tuning hyper-parameters
如多项式回归中的degree,即为超参数hyper-parameter,通过对超参数的选取和分析,可以得出最好的点
• Cross validation
9.3. Using Cross Validation
问题:
使用仅仅一组validation集去选取,可能会导致一个对于验证集过拟合的模型被认为是最好的模型。对每个模型都随机取验证集则会使模型间评估标准不一,无法准确展示重要的features

K折交叉检验 K-Fold Cross Validation:
将之前所说的训练集(数据集=训练集+测试集)平均(uniformly)分成K份,每次将其中一份设为验证集,剩下的K-1份作为训练集。这样进行K次评估后,对K次评估值求均值最为最终检验值。

Python:
sklearn.model_selection.cross_validate(estimator, X, y, scoring, cv, return_train_score)
k折的大小选择:
过大的k会导致每次验证集很小,训练集比较多,最终模型预测出来的就比较准
过小的k会导致验证集比较大,训练集较小,最终模型预测能力下降
k折对于不同数据集的考虑:
- 时间序列数据(Time-series dataset),使用k折时要依据时间段划分
- 不平衡数据集(Unbalanced dataset),使用分层抽样(stratified sampling),确保正负样本都在每折里面
- 嵌套交叉检验(Nested cross-validation),超参数的调整是在用于训练的的k-1折中再次进行k折交叉检验确定的
Lec10 Models
10.1. Processes Involved in Machine Learning
Data gathering - Data Pre-Processing - Choose Model - Train Model - Test Model - Tune Model
10.2. Types of Machine Learning Algorithms
监督学习(Supervised Learning):
Classification
Regression
非监督学习(Un-Supervised Learning):
Association
Clustering
强化学习(Reinforcement Learning):
Reinforcement Learning
10.3. Popular Algorithms with Hands On Demo
10.3.1. Linear Regression
线性回归找到两个或多个独立变量(predictors)和目标值(target)之间的关系
回归模型评估标准是最小化各点到回归线的距离(平方差)
如何实现:
import库,导入数据集,可视化数据集,划分训练集和测试集,模型拟合,用训练好的模型预测,可视化回归结果,计算模型准确率

10.3.2. Logistic Regression
逻辑回归使用sigmoid曲线作为激活函数,输出的区间0-1可以认为是概率,也可设立阈值如0.5来变成二分类

流程与线性回归类似,多了一个对Feature进行StandardScaler

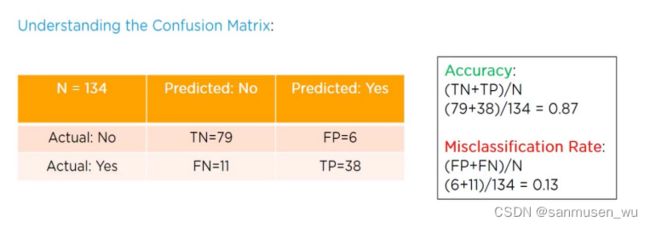
Confusion Matrix混淆矩阵:用来评估分类结果
TN:True Negative:实际为负,预测为负
FN:False Negative:实际为正,预测为负
10.3.3. Decision Tree and Random Forest

过程依旧类似(这个不用Normalize),PPT上只讲sklearn如何实现,没说具体的数节点的分裂
10.3.4. K Nearest Neighbor
K近邻,对于未知的样本,选取最近的k个已知样本,按照投票制投出未知样本label
这个模型只有超参数k,没有参数。
Lec11 Decision Trees, Bagging and Random Forest
这节具体讲了决策树
11.1. Decision Trees
11.1.1. Motivation
逻辑回归只适用于数据集在向量空间中分布明显的情景。并且log-odds=0(logistic函数的反函数)既 x β = 0 x\beta=0 xβ=0定义了决策边界或决策平面,对于复杂的空间分布,逻辑回归无能为力。此时的决策边界十分复杂,此时期望得到一种模型,具有以下特点:
- 可由人类解释
- 具有足够复杂的决策边界
- 决策边界是局部线性的,决策边界的每个组成部分都易于数学描述

11.1.2. Decision Trees
Flow charts whose graph is a tree (connected and no cycles) represents a model called a decision tree. 树的内部节点表示属性测试, 下一级的分支由属性值决定, 叶子节点表示类分配(怎么感觉这个图都和305一模一样,每一个内部节点都可以单独用决策边界表示,每个内部节点通常划分一个feature,通常每一层也划分同一个feature
11.1.3. Classification Trees
给定训练集,分类决策树模型需要:
- 生成具有轴对称线性边界的特征空间的最优分区
- 其中,在执行预测时,基于该分区中数据点的最大类(贝叶斯分类器)为每个区域提供一个类标签(也就是谁占最多这块归谁),最终叶子节点输出标签

学习流程如下:
- 从一个空的决策树(未分割的feature空间)开始。
- 选择要拆分的最佳predictor,并选择拆分的最优阈值(threshold),也就是知道这个节点要根据哪个feature和哪个决策边界分类。
- 在每个新节点上重复,直到满足停止条件,也就是要设定什么时候停止增长

停止条件:
- 设定决策树的最大深度 max_depth(通过交叉检验
- Pruning剪枝:cost complexity pruning,在得到完整决策树后,构建许多决策树的子树,然后评估这些子树
11.1.4. Regression Trees
回归问题的决策树,适用于连续型数据
学习流程和分类决策树类似,不过分割依据变成了尽可能使MSE(模型整体的预测误差)减小。叶子节点的输出值通常是该区域内该类点的均值
- 从一棵空的决策树开始(未划分的特征步调)
- 选择一个预测变量 j 在其上分割并选择一个阈值 tj分裂使得新区域Region的加权平均 MSE 尽可能小
a r g m i n i , t j { N 1 N M S E ( R 1 ) + N 2 N M S E ( R 2 ) } argmin_{i,t_{j}}\{\frac{N_1}{N}MSE(R_1)+\frac{N_2}{N}MSE(R_2)\} argmini,tj{NN1MSE(R1)+NN2MSE(R2)}
a r g m i n i , t j { N 1 N V a r ( y ∣ x ∈ R 1 ) + N 2 N V a r ( y ∣ x ∈ R 2 ) } argmin_{i,t_{j}}\{\frac{N_1}{N}Var(y|x\in R_1)+\frac{N_2}{N}Var(y|x\in R_2)\} argmini,tj{NN1Var(y∣x∈R1)+NN2Var(y∣x∈R2)} - 在新节点上重复,直到符合停止条件

通过剪枝pruning或限制最大深度避免过拟合
树的优缺点:
+Trees are very easy to explain to people. In fact, they are even easier to explain than linear regression!
+Some people believe that decision trees more closely mirror human decision-making than do the regression and classification approaches seen in previous lectures.
+Trees can be displayed graphically, and are easily interpreted even by a non-expert (especially if they are small).
+Trees can easily handle qualitative predictors without the need to create dummy variables.
-Unfortunately, trees generally do not have the same level of predictive accuracy as some of the other regression and classification approaches seen in previous lectures.
-Additionally, trees can be very non-robust(非健壮的). In other words, a small change in the data can cause a large change in the final estimated tree.
11.2. Bagging
Bootstrap Aggregating=Bagging
将一个大小为m的训练集有放回的构建多个训练集(bootstrap sample),每个训练集大小也为m。然后用这些训练集构建模型,结合多个模型的结果做最终预测,提高准确率(解决高方差的问题high variance,高方差/过拟合:模型可以做出预测,但只对训练集附强相关的输入有效),以上操作也就是构建分类器集合(Ensembles of Classifiers)
- voting:分类问题:输出plurality of the models(最多的那个标签), 回归问题:输出所有子模型输出的平均值
对于高方差模型,通常的解决方法:
- (Bootstrap) we generate multiple samples of training data, via bootstrapping. We train a full decision tree on each sample of data. 创建多个训练集子集,同一模型
- (Aggregate) for a given input, we output the averaged outputs of all the models for that input. 。同一数据,创建多个模型
Bagging的好处:
- 高表现力——通过使用完整的树,每个模型都能够学习复杂的函数和决策边界。
- 低方差——假设我们选择了足够多的树,对所有模型的预测进行平均可以减少最终预测的方差。

Bagging不足:
- 如果树太大,还是会过拟合
- 如果树太小,会欠拟合,综合这两点,需要对树大小做交叉检验
- 较低的解释性(Interpretability)
Out-of-Bag Error(OOB):Bagging是集群方法的例子(ensemble method),集群既通过构建多个子模型来构建一个整体模型,计算out-of-bag error:
——对于训练集中的一个数据点,计算包含这个点的samples对应的模型们的预测值的平均值最为该点预测值p,然后求这个值p与真实标签的误差或方差,称为point-wise out-of-bag error。所有数据点的point-wise out-of-bag error的均值叫做ensemble的out-of-bag error.

Bagging的可改进之处:
如果有一个和结果强相关的predictor,那么每个基学习器都会根据这个predictor学习,使得整个estimator结果和单一学习器无差别
11.3. Random Forests
随机森林是对决策树使用了bagging思想的模型。
为了减少树之间的相关性:
- 每个树都只训练完整训练集的 bootstrap sample。
- 对于每个树的每个割,我们从这个树的sample里随机选取J个prediictors作为这次割的features集合,然后从中选出最优的predictor和最优割。
如何调参(超参数,以及历史经验:
- 每次割的时候选择的predictors集合大小,分类一般选 N j \sqrt{N_j} Nj,回归一般选 N 3 \frac{N}{3} 3N
- ensemble集群的基分类器数量
- 最小的叶子节点大小(提前停止增长树,减少计算量)
当predictor数量过多,而relevant predictors过少,随机森林的表现不好。由于每次割的时候选取到强相关的predictor几率太小,导致没法算出有效的决策边界,每个基分类器都是weak models
通常,增加树的数量不会增加集群的过拟合风险。通过根据偏差和方差分解泛化误差,我们看到增加树的数量会产生与单棵树一样稳健的模型。然而,如果树的数量太多,那么集群中的树就可能会变得更相关,增加方差。
Lec 12 Boosting
上一节说到单个决策树过大时偏差小方差大(单个决策树过简单时偏差大),因此可以使用集群的思想用多个完整的决策树(也就是随机森林)然后算平均预测来减小方差。
如果考虑:
- 数据集不平衡?
- 采样点有权重之分?
- 分类数据?
- 遗失数据?
- 为什么不使用misclassification error?
Boosting思想:
”其中Boost也被称为增强学习或提升法,是一种重要的集成学习方法,它能够将预测精度仅仅比随机猜测略高的多个弱学习器增强为预测精度很高的强学习器。这是在直接构造强学习器较为困难的情况下,为学习算法提供了一种有效的新思路和新方法。“
【https://blog.csdn.net/qq_38890412/article/details/120360354】
将简陋的模型逐步变成为一个健硕的模型
12.1. Gradient Boosting
12.1.1. Set-up and intuition
逐渐将weak model更新:
- 对于N个样本的训练集{((x1,y1),…,(xN,yN)},训练一个简单的模型T(0)作为T。,然后对T计算残差(残差是因变量的观测值与根据估计的回归方程求出的预测值之差),残差为{r1,…,rN}

- 对于现有的残差集{((x1,r1),…,(xN,rN)},再训练一个简单模型T(1)
- 更新 T = T + λ T ( 1 ) T=T+\lambda T^{(1)} T=T+λT(1)
- 再次计算T的残差,更新残差为 r n = r n − λ T i ( x n ) r_n=r_n-\lambda T^i(x_n) rn=rn−λTi(xn)
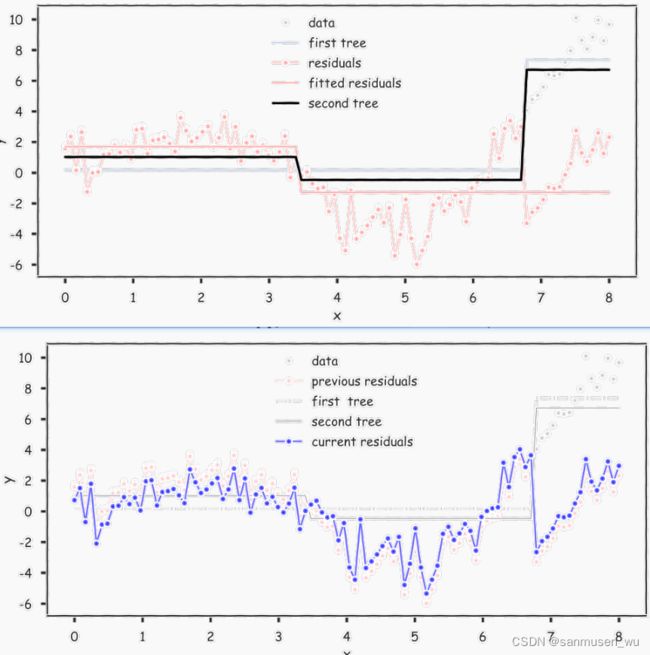
- 重复2-4操作直到符合停止条件, λ \lambda λ称为学习率
12.1.2. Connection to Gradient Descent
为什么Gradient Boosting有效:
- 每个简单模型对集群模型T做出的贡献是随着每次添加,残差在不断减小 r n − λ T ( i ) ( x n ) r_n-\lambda T^{(i)}(x_n) rn−λT(i)(xn)
梯度下降的回顾:
In optimization, when we wish to minimize a function, called the objective function, over a set of variables, we compute the partial derivatives of this function with respect to the variables.
If the partial derivatives are sufficiently simple, one can analytically find a common root - i.e. a point at which all the partial derivatives vanish; this is called a stationary point.
If the objective function has the property of being convex, then the stationary point is precisely the min.

为什么梯度下降有效?
如果方程为凸的,迭代方法将会把x尽可能地移动到最小值的地方,通过在斜率最大的路径上不断移动。
Gradient Boosting与梯度下降不同的地方是,我们已经知道了最优情况发生在何处——当集群的预测值等于label yn时(将MSE作为Loss function),此外,The predictions in the sequences do not depend on the predictors(意思应该是不像反向传播一样,这次的反向传播需要正向传播的数值来计算,所以对于Boosting,学习的序列前后无依赖,所以就不用求梯度下降了,转而使用残差(residual)作为梯度下降的近似效果,于是就有了前面根据残差进行训练的过程。
12.1.3. The Algorithm
通过对比以上两个东西,我们可以参照梯度下降对于学习率的研究来设定学习率。
何时终止训练?
- 限制迭代次数,但是没法预知我们是否已经达到了最优
- 当下降的十分微弱时停止
学习率太小学的太慢,学习率太快无法准确收敛(the algorithm may ‘bounce’ around the optimum and never get sufficiently close):
- 如果学习率是常数,则用交叉检验
- 如果动态学习率, λ = h ( ∣ ∣ ∇ f ( x ) ∣ ∣ ) \lambda=h(||\nabla f(x)||) λ=h(∣∣∇f(x)∣∣),梯度大时学习率大,反之亦然
12.2. AdaBoost
为什么对分类问题不使用分类误差作为Cost function然后梯度下降:

对于分类问题,当我们想要梯度下降时发现分类误差作为Cost function这东西不可微(not differentiable)
但是指数损失函数是可微的

由此得来的更新方程:
y ^ n ← y ^ n + λ w n y n \hat y_n \leftarrow \hat y_n+\lambda w_ny_n y^n←y^n+λwnyn
类似于gradient boosting,我们使用一个新的模型来近似wnyn,也就是 { ( x 1 , w 1 y 1 ) , . . . , ( x N , w N y N ) } \{(x_1,w_1y_1),...,(x_N,w_Ny_N)\} {(x1,w1y1),...,(xN,wNyN)}作为数据集训练一个weak model取其参数,可以发现我们需要抉择w,也就是原始label的权重
AdaBoost过程:
-
选取一个初始权重w,为 1 N \frac{1}{N} N1
-
在第i步,使用上一步更新的权重 { ( x 1 , w 1 y 1 ) , . . . , ( x N , w N y N ) } \{(x_1,w_1y_1),...,(x_N,w_Ny_N)\} {(x1,w1y1),...,(xN,wNyN)}作为训练集,训练一个简单分类器

-
更新权重, w n = w n e x p ( − λ ( i ) y n T ( i ) ( x n ) ) Z w_n=\frac{w_nexp(-\lambda^{(i)}y_nT^{(i)}(x_n))}{Z} wn=Zwnexp(−λ(i)ynT(i)(xn)),其中Z是权重集合的归一化常数,被分类错误的样本被赋予了更高权重

-
更新参数 T ← T + λ ( i ) T ( i ) T \leftarrow T+\lambda^{(i)} T^{(i)} T←T+λ(i)T(i)
-
重复2到4步直到结束,所有过程中的弱分类器被组合起来成一个强分类器,根据每个弱分类器的分类准确率来设定弱分类器对最后分类结果的贡献(对于分类准确率比较高的弱分类器,对它的结果给予比较大的权重)。

学习率可以通过以下求出来:
a r g m i n λ 1 N ∑ n = 1 N e x p [ − y n ( T + λ ( i ) T ( i ) ( x n ) ) ] argmin_\lambda \frac{1}{N}\sum_{n=1}^{N}exp[-y_n(T+\lambda^{(i)}T^{(i)}(x_n))] argminλN1∑n=1Nexp[−yn(T+λ(i)T(i)(xn))]
求得每轮最优学习率:
λ ( i ) = 1 2 l n 1 − ϵ ϵ \lambda^{(i)}=\frac{1}{2}ln\frac{1-\epsilon}{\epsilon} λ(i)=21lnϵ1−ϵ
ϵ = ∑ n = 1 N w n ⨿ ( y n ≠ T ( i ) x n ) \epsilon=\sum_{n=1}^{N}w_n\amalg (y_n\neq T^{(i)}x_n) ϵ=∑n=1Nwn⨿(yn=T(i)xn)
Increasing the number of trees can lead to overfitting?
| 优化方法 | |
|---|---|
| bagging | the trees are grown independently on random samples of the observations. Consequently, the trees tend to be quite similar to each other. Thus, bagging can get caught in local optima and can fail to thoroughly explore the model space. |
| random forests | the trees are once again grown independently on random samples of the observations. However, each split on each tree is performed using a random subset of the features, thereby decorrelating the trees, and leading to a more thorough exploration of model space relative to bagging. |
| boosting | we only use the original data, and do not draw any random samples. The trees are grown successively, using a “slow” learning approach: each new tree is fit to the signal that is left over from the earlier trees, and shrunken down before it is used. |
这节PPT后面有个题,可以做下
Lec13 Recommendation Systems
【http://blog.csdn.net/pipisorry/article/details/49205589】
推荐系统由来:
网络使产品信息的传播成本几乎为零——从稀缺到丰富——产生了“长尾”现象(人们越关注的东西越流行,而不怎么流行的东西形成的市场在尾部无限大
推荐的种类:
- 手动编辑 – 收藏夹列表 – “基本”项目列表
- 简单聚合 – 前 10 名、最受欢迎、最近上传的内容
- 为个人用户量身定制 – 亚马逊、Netflix、……
Formal Model:
X=set of Customers
S=set of Items
Utility function: X × S → R X \times S \rightarrow R X×S→R
R=set of ratings
Utility Matrix(效用矩阵):

1):收集矩阵中已知的排名评分(手段:直接询问用户(问卷)/从用户的操作上得知(加购收藏))
2):从已知的推断( extrapolation)未知的评分——主要尝试找出未知的高分作品(问题:效用矩阵是稀疏的,已知的评分占很少一部分,且有冷启动(Cold start)问题——新上映的电影甚至没有评分!)(手段:Content-based,Collaborative,Latent factor based)
3):评估推断算法——如何评估(见后文)
13.1. Content-based Recommendation Systems
主要思想:对于用户x,找出与x之前打高分的物品相似的东西,推荐给x

如何衡量物品(就是定feature以及重要的feature:
+创建Item profile,其内是各种feature,对于电影而言就是时长作者标题类型转为数字或one-hot
+文本可以使用使用TF-IDF(Term frequency * Inverse Doc Frequency)判断一个词的权重(一般来说,某个词在较少的文档中出现较多次,则说这个词比较有特征
TF-IDF:
fij=frequency of term (feature) i in doc (item) j
TFij= f i j m a x k f k j \frac{f_{ij}}{max_kf_{kj}} maxkfkjfij
ni=number of docs that mention term i
N=total number of docs
IDFi= l o g N n i log \frac{N}{n_i} logniN
TF-IDF score: w i j = T F i j × I D F i wij=TF_{ij} \times IDF_i wij=TFij×IDFi
如何衡量用户:
+创建User Profiles,记录用户互动过的物体的profiles来构建用户的profile
+Weighted average of rated item profiles 或 (Variation) Normalize weights using average rating of user
example:
(Boolen Utility Matrix,加权平均方式,无评分类型数据)假如评估电影,且现在只有一个导演作为feature。假设用户A看过五个电影,其中两个是导演M拍的,三个是导演N拍的。
| M | 1 | 1 | 0 | 0 | 0 |
|---|---|---|---|---|---|
| N | 0 | 0 | 1 | 1 | 1 |
那么用户A的profile就是items profile的加权均值,导演M的权重是0.4, 导演N的权重是0.6。
(Star Rating,varaiant方式,有评分数据)现在有评分作为feature,A给导演M的两部电影打分3和5分,给导演N的电影打分1,2和4。
| M | 3 | 5 | 0 | 0 | 0 |
|---|---|---|---|---|---|
| N | 0 | 0 | 1 | 2 | 4 |
那么现在A的profile中,先给A评过的分做归一化(normalize),【0,2 | -2,-1,1】,A对导演M的最终评分为(0+2)/2=1,对导演N的评分为(-2-1+2)/3=-2/3
如何预测:
给定一个user profile x和某个item profile i,用这两个向量在空间中的夹角余弦值( x ⋅ i ∣ ∣ x ∣ ∣ ⋅ ∣ ∣ i ∣ ∣ \frac{x \cdot i}{||x||\cdot ||i||} ∣∣x∣∣⋅∣∣i∣∣x⋅i)评估用户对这个item的喜好程度,称为cosine similarity
Content-based优缺点:
+不需要其他用户数据,无物品的冷启动问题
+能够按个人喜好推荐
+能够推荐小众,不热门的物品
+能够提供explanation
-寻找那些适合的feature很难
-无法尝试为用户推荐他目前兴趣圈之外的东西
-无法用别的用户的数据帮助推荐
-新用户的user profile不确定
13.2. Collaborative Filtering
考虑其他用户对某个用户的推荐的影响
13.2.1. 如何度量与用户x相似的其他用户(User-user collaborative filtering):
如图:similarity matrics

对于用户x,找到与用户x相似的其他用户群体N,根据N的兴趣圈推荐东西给x。
用户A,B,C,D
similarity计算结果可以代表距离越近的数据点越相似
- Jaccard similarity:
sim(A,B)= ∣ r A ∩ r B ∣ / ∣ r A ∪ r B ∣ |r_A \cap r_B|/|r_A \cup r_B| ∣rA∩rB∣/∣rA∪rB∣
这里取的是物体的交并集,比如A交C={TW, SW1},A并C={HP1, TW, SW1, SW2}
sim(A,B)=1/5 - Cosine similarity
sim(A,B)=cos(rA,rB)
sim(A, B) = 0.38> sim(A, C) = 0.32
缺点:把丢失的评分视作负相关(小于均值) - Centered consine similarity
先对每一行数据做归一化,均值0,然后算cosine

sim(A,B)=cos(rA,rB)=0.09>sim(A,C)=-0.56
也叫做Pearson Correlation Coefficient,整体公式如下:

如何预测Rating Predictions
假设对于用户x,rx是用户的rating vector,N是一个包含了k个与x十分相近的用户群,N中的用户(下面公式中称为y)都给物品i打过分,那么物品i对于用户x而言的预测分数为:
r x i = 1 k ∑ y ∈ N r y i r x i = ∑ y ∈ N s x y ⋅ r y i ∑ y ∈ N s x y # 用户 x 对物品 i 的打分估计 s x y = s i m ( x , y ) # x 与 y 的相似度 r_{xi}=\frac{1}{k}\sum_{y \in N}r_{yi}\\ r_{xi}=\frac{\sum_{y \in N}s_{xy} \cdot r_{yi}}{\sum_{y \in N}s_{xy}}\#用户x对物品i的打分估计\\ s_{xy}=sim(x,y)\#x与y的相似度 rxi=k1∑y∈Nryirxi=∑y∈Nsxy∑y∈Nsxy⋅ryi#用户x对物品i的打分估计sxy=sim(x,y)#x与y的相似度
13.2.2. 如何度量与物品i相似的其他物品( Item-item similarity collaborative filtering):
对某个用户而言,对于物品i,找到他打过分的相似的物品们(下公式中每个物品记为j),用其他物品i的分数估计物品i的分数,
r x i = ∑ j ∈ N ( i ; x ) s i j ⋅ r x j ∑ j ∈ N ( i ; x ) s i j r_{xi}=\frac{\sum_{j \in N(i;x)}s_{ij} \cdot r_{xj}}{\sum_{j \in N(i;x)}s_{ij}} rxi=∑j∈N(i;x)sij∑j∈N(i;x)sij⋅rxj
其中,
N(i;x)指对于x用户而言与物品i相似的物品集合,不包含i
s指两物品的相似程度
r指用户对物品的打分
例子:
这里需要预测?处的分数,首先先找到用户打过分的两个和?处物品非常相似的3和6

套公式
s1,3=0.41, s1,6=0.59, r1.5(用户5对于物品1的分)= 0.41 ∗ 2 + 0.59 ∗ 3 0.41 + 0.59 = 2.6 \frac{0.41*2+0.59*3}{0.41+0.59}=2.6 0.41+0.590.41∗2+0.59∗3=2.6
13.3. Evaluating Recommendation Systems
通常来说,item-item 比user-user效果好,因为用户有多种口味,而item种类单一。
Collaborative Filtering优缺点
+对于任何类型物体都有效,无需feature转化
-无法解决冷启动(cold start),需要足够多的用户来匹配
-稀疏矩阵(sparsity)问题,用户评分表是稀疏的,很难同一个用户找到相似的k个物品
-首次匹配(First rater)问题,如果某个问题从来没有被评分过,则相似值永远是0
-流行偏差(Popularity bias),小众爱好无法被推送,会尝试推送最热门的东西
解决方法:
- Add content-based methods to collaborative filtering
– Item profiles for new item problem
– Demographics to deal with new user problem - Implement two or more different recommenders and combine predictions
– Perhaps using a linear model
13.3.1. Evaluation
抹去一部分打分,作为测试集。

Root-mean-square error(RMSE),T是test set,N为Test set中分数的格子的数量,r为预测的打分,r*为实际打分
R M S E = ∑ ( x , i ) ∈ T ( r x i − r x i ∗ ) 2 N RMSE=\sqrt \frac{\sum_{(x,i)\in T}(r_{xi}-r_{xi}^*)^2}{N} RMSE=N∑(x,i)∈T(rxi−rxi∗)2
需要注意的点:
- 过分注重准确率,反而会减少对{Prediction Diversity,Prediction Context,Order of predictions}的关注
- 在实际应用中,我们关心预测高分的东西。因此,RMSE可以设计成对高分作品做出较大惩罚,来让模型预测高分作品正确率好一点。为了得到高分作品可以统计出某个用户的电影表单里前top k predictions的电影。
Lec14
Singular Value Deposition奇异值分解

这次终于彻底理解了奇异值分解(SVD)原理及应用