Spark versus Flink: Understanding Performance in Big Data Analytics Frameworks论文总结
Spark versus Flink: Understanding Performance in Big Data Analytics Frameworks论文总结
- Abstract
- I. INTRODUCTION
- II. CONTEXT AND BACKGROUND
-
- A. Apache Spark
- B. Apache Flink
- C. Zoom on the Differences between Flink and Spark
- IV. THE IMPORTANCE OF PARAMETER CONFIGURATION
-
- A. Task Parallelism
- B. Shuffle Tuning
- C. Memory Management
- D. Data Serialization
- V. METHODOLOGY AND EXPERIMENTAL SETUP
- VI. RESULTS AND DISCUSSION
-
- A. Evaluating the Aggregation Component (Word Count)
- B. Evaluating Text Search (Grep)
- C. Shuffle, Caching and the Execution Pipeline (Tera Sort)
- D. Bulk Iterations Performance (K-Means)
- E. Graph Processing (Page Rank and Connected Components)
- VII. RELATED WORK
- VIII. SUMMARY OF INSIGHTS AND CONCLUSION
Abstract
Spark 和 Flink 是两个 Apache 托管的数据分析框架,它们使用直接无环图模式促进多步骤数据管道的开发。
尽管已经有广泛的研究致力于改进和评估此类分析框架的性能,但其中大多数都将平台与 Hadoop 作为基准,考虑到根本不同的设计原则,这是一种相当不公平的比较。
本文旨在通过直接评估 Spark 和 Flink 的性能,在这方面带来一些公平。
我们的目标是识别和解释不同架构选择和参数配置对感知的端到端性能的影响。
我们的主要发现是,这两个框架在所有数据类型、大小和作业模式方面都没有一个优于另一个。
I. INTRODUCTION
MapReduce [2] 模型及其开源实现 Hadoop [3] 被工业界和学术界广泛采用,这要归功于一个简单而强大的编程模型,它向用户隐藏并行任务执行和容错的复杂性。这个非常简单的 API 有一个重要的警告,它强制应用程序用 map 和 reduce 函数来表达。
但是,大多数应用程序不适合此模型,并且需要更通用的数据编排,独立于任何编程模型。
例如,图分析和机器学习中使用的迭代算法,它们对相同的数据执行几轮计算,原始 MapReduce 模型不能很好地服务。
为了解决这些限制,出现了第二代分析平台,试图统一大数据处理的格局。
Spark [4] 引入了弹性分布式数据集 (RDD) [5],这是一组内存数据结构,能够跨一组节点缓存中间数据,以有效地支持迭代算法。
出于同样的目标,Flink [6] 最近提出了原生闭环迭代算子 [7] 和一个基于成本的自动优化器,它能够对算子重新排序并更好地支持流式传输。
网络优化的目标是端到端吞吐量 [13] 或并行流 [14]。
存储优化利用复杂的内存缓存 [5]、[15]。
我们介绍了一种通过运营商执行计划与资源利用之间的相关性来分析此类平台性能的方法。
然后,我们使用这种方法来研究几个批处理和迭代处理基准的性能,着眼于可扩展性和易于配置。
我们将重点关注 Spark 和 Flink 作为代表性的数据分析框架。我们提供了 Spark 和 Flink 之间深入、直接的性能比较,因为之前的工作通常将这些框架与 Hadoop 进行基准测试,考虑到其关键设计选择(例如使用磁盘、缺乏优化器等),对于后者来说这是一个不公平的比较。
我们的第二个目标是评估对所有数据源、工作负载和环境 [16] 使用单一引擎是否可行,以及研究依赖智能优化器的框架在现实生活[17]。
我们的贡献总结如下:
- 将运营商执行计划与资源利用率和参数配置相关联,引入了一种方法来了解大数据分析框架中的性能。
- 这些实验涉及用于批处理和迭代处理的六个代表性工作负载。实验是在 Grid’5000 [18] 测试平台上进行的,具有多达 100 个节点的各种集群大小。
- 分析了各种架构选择并确定了它们对性能的影响,我们说明了限制并讨论了两个框架在用户和开发人员的一组外带中 (take-aways) 的易于配置。
第二节介绍 Spark 和 Flink,强调它们的架构差异
第三节给出了工作负载的描述
第四节强调了正确参数配置对性能的影响
第五节详细介绍了我们的实验方法
第六节介绍了结果以及详细的分析
第七部分调查了相关工作
第八部分列出了我们的见解并总结了这项研究
II. CONTEXT AND BACKGROUND
Spark 和 Flink 使用直接无环图 (DAG) 模式促进了多步数据管道的开发。
在更高的层次上,两个引擎都实现了一个描述应用程序高级控制流的驱动程序,它依赖于两个主要的并行编程抽象:(1)描述数据的结构和(2)对这些数据的并行操作。
虽然数据表示不同,但 Flink 和 Spark 都实现了相似的数据流运算符(例如 map、reduce、filter、distinct、collect、count、save),或者可以使用 API 来获得相同的结果。
A. Apache Spark
Spark 构建在 RDD(跨多个节点分区的只读、弹性对象集合)之上,RDD 保存了出处信息(称为沿袭),并且可以在失败的情况下通过祖先 RDD 的部分重新计算来重建。
默认情况下,每个 RDD 都是惰性的(即仅在需要时计算)和短暂的(即,一旦它实际实现,它将在使用后从内存中丢弃)。
由于在计算过程中可能会重复需要 RDD,因此用户可以将它们显式标记为持久,这会将它们移动到持久对象的专用缓存中。
RDD 上可用的操作似乎总体上模拟了 MapReduce 范式的表达能力,
但是,有两个重要的区别:
- (1)由于它们的惰性,map 只会在 reduce 之前处理,在一个阶段中累积所有计算步骤
- (2) RDDs可以被缓存以备后用,这大大减少了在涉及多个reduce操作的更复杂的工作流中与底层分布式文件系统交互的需要。
B. Apache Flink
Flink 建立在 DataSets数据集(特定类型元素的集合,在其上定义了隐式类型参数的操作)、Job Graphs作业图和Parallelisation Contracts并行化合约(PACTs)[19] 之上。
- 作业图表示具有任意任务的并行数据流,这些任务消耗和产生数据流。
- PACT 是二阶函数,它在其相关的用户定义(一阶)函数 (UDF) 的输入/输出数据上定义属性;这些属性进一步用于并行化 UDF 的执行并应用优化规则 [8]。
C. Zoom on the Differences between Flink and Spark
与 Flink 相比,Spark 的用户可以控制 RDD 的两个非常重要的方面:持久性(即基于内存或磁盘)和跨节点的分区方案 [5]。事实证明,这种对中间数据存储方法的细粒度控制对于具有不同 I/O 要求的应用程序非常有用。
另一个重要区别与迭代处理有关。
- Spark 将迭代实现为常规的 for 循环,并通过循环展开来执行它们。这意味着对于每次迭代,都会安排和执行一组新的任务/操作符。每次迭代都对保存在内存中的前一次迭代的结果进行操作。
- Flink 以循环数据流的形式执行迭代。这意味着一个数据流程序(及其所有操作符)只被调度一次,并且数据从迭代的尾部反馈到它的头部。不是很懂
Flink 的 API 提供了两个专用的迭代运算符来指定迭代:
- 1)bulk iterations批量迭代,在概念上类似于循环展开,以及
- 2)delta iterations增量迭代,增量迭代的一种特殊情况,其中解决方案集由阶跃函数而不是完全重新计算。 Delta 迭代可以显着加速某些算法,因为每次迭代中的工作随着迭代次数的增加而减少。
在本文中,我们旨在全面了解 Flink 和 Spark,最终将回答以下问题:这些不同的架构选择如何影响性能?
III. WORKLOADS
尽管最初开发它们是为了通过有效的迭代支持来增强面向批处理的 Hadoop,但目前 Spark 和 Flink 反过来用于批处理和迭代处理。
- Batch workloads批处理工作负载。我们选择了三个实现一次性处理的基准:Word Count, Grep(UNIX 工具程序;可做文件内的字符串查找),Tera Sort排序。这些具有代表性的工作负载用于多个现实生活中的应用程序,无论是科学应用程序(例如在 LHC [24] 上为监控数据编制索引)还是基于 Internet(例如在 Google、Amazon [25]、[26] 上进行搜索)。
- Iterative workloads迭代工作负载。我们选择了三个评估循环缓存的基准:K-Means、Page Rank 和 Connected Components。这些工作负载在机器学习算法 [27] 和社交图处理(在 Facebook [28] 或 Twitter [29])中很常见。
表一列出了每个工作负载使用的最重要的算子,包括基本的核心算子和每个框架的图形库实现的具体算子。

表 I:每个工作负载中使用的运算符:字数 (WC)、Grep (G)、Tera 排序 (TS)、K-Means (KM)、页面排名 (PR)、连接组件 (CC)。
带有 F 或 S 注释的运算符分别仅特定于 Flink 或 Spark,其他运算符对两个框架都是通用的。
- Word Count
字数是通过计算每个单词出现的总数来衡量文章质量的简单指标。它非常适合评估每个框架中的聚合组件,因为 Spark 和 Flink 都使用 map side combiner 来减少中间数据。 - Grep
Grep 是搜索纯文本数据集的常用命令。在这里,我们使用它来评估过滤器转换和计数操作。 - Tera Sort
Tera Sort 是一种排序算法,适用于测量两个引擎的 I/O 和通信性能。 - K-Means
K-Means 是一种用于数据挖掘的无监督方法,用于对具有高相似性的数据元素进行分组。 - Page Rank
Page Rank 是一种图算法,它根据引用对一组元素进行排名。 - Connected Components
Connected Components 给出了图的一个重要的拓扑不变量。
Page Rank 和 Connected Components 都可用于评估缓存和数据流水线性能。
IV. THE IMPORTANCE OF PARAMETER CONFIGURATION
参数配置的重要性
这两个框架都公开了各种执行参数,预先配置了默认值并允许进一步定制。对于每个工作负载,我们发现需要不同的参数设置来提供最佳性能。
在配置 Flink 和 Spark 方面存在显着差异,就易于调整以及授予对框架和底层资源的控制而言。
我们已经确定了一组 4 个最重要的参数,这些参数对整体执行时间、可伸缩性和资源消耗有重大影响。
他们管理任务并行性、随机阶段的网络行为、内存和数据序列化。
A. Task Parallelism
并行度设置的含义和默认值在两个框架中是不同的。
Spark 的默认并行度参数(spark.def.parallelism)是指各种转换返回的 RDD 中的默认分区数。
Flink 的默认并行参数(flink.def.parallelism)允许使用所有可用的执行资源(任务槽)。
在 Flink 中,数据的分区对用户是隐藏的,并行度设置可以自动初始化为可用内核的总数。
B. Shuffle Tuning
配置 Flink 和 Spark 的一个区别在于网络缓冲区的强制设置,用于在通过网络传输或分别接收之前存储记录或传入数据。
我们启用了 Spark 的 shuffle 文件合并属性,以提高具有大量 reduce 任务的 shuffle 的文件系统性能。
将 Spark 洗牌管理器的实现初始化为 tungsten-sort,这是一种基于内存高效排序的洗牌。这是为了与使用基于排序的聚合组件的 Flink 进行公平比较。
C. Memory Management
Spark 中,执行程序的所有内存都分配给 Java 堆(spark.executor.memory)。
Flink 允许一种混合方法,结合堆内和堆外内存分配。
D. Data Serialization
数据序列化
Flink 窥探用户数据类型(通过类型描述符的 TypeInformation 基类)并利用这些信息实现更好的内部序列化;因此,不需要配置。
在 Spark 中,序列化(spark.serializer)默认使用 Java 方法完成,但可以将其更改为 Kryo 序列化库 [34],它可以更高效,以换取 CPU 周期的速度。
V. METHODOLOGY AND EXPERIMENTAL SETUP
方法与实验设置
为了了解先前配置对性能的影响并量化设计选择的差异,我们设计了以下方法。
对于 Flink 和 Spark,我们使用不同的参数设置绘制执行计划,并将其与资源利用率相关联。
就性能而言,在本研究中,我们专注于端到端执行时间,我们使用添加到框架源代码中的计时器和解析可用日志来收集它,并在上下文中对其进行分析强和弱的可扩展性。
我们将 Flink 和 Spark 部署在 Grid’5000 [18] 上,这是一个大规模的多功能测试平台
对于每个实验,我们都遵循相同的循环。我们安装 Hadoop (HDFS) 并配置 Flink 和 Spark 的独立设置。我们导入分析的数据集,每个实验平均执行 5 次运行。
VI. RESULTS AND DISCUSSION
对于批处理工作负载,我们的目标是验证强和弱的可扩展性。
对于迭代工作负载,我们专注于可扩展性、缓存和流水线性能。
A. Evaluating the Aggregation Component (Word Count)
评估聚合组件(字数)
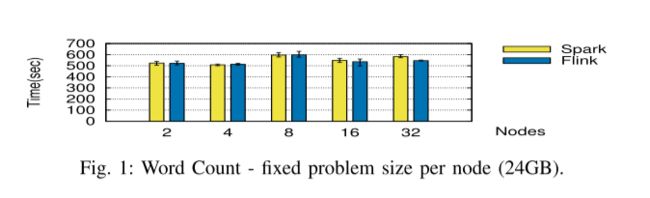
我们首先使用每个节点的固定问题大小(图 1)和表 II 中详述的参数配置运行基准测试,然后使用固定数量的节点和增加的数据集(图 2)。

-
Weak Scalability.
我们在图 1 中观察到,两个框架在添加节点时都可以很好地扩展,对于少量节点(2 到 8 个)显示出相似的性能。对于更大的数字(16 和 32),Flink 的性能稍好一些。即使为了公平起见,由于使用了 Java 序列化程序,我们为 Spark 配置了更多内存,也会发生这种情况。

-
Strong Scalability.
对于大型数据集和固定数量的节点(图 2),这一观察得到了进一步证实,Flink 的性能不断优于 Spark 10%。 -
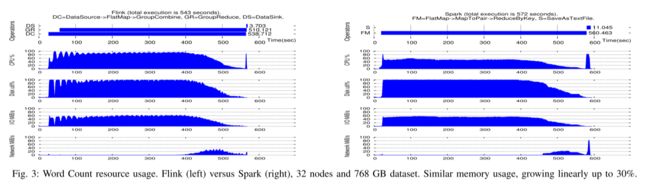
Resource Usage.
图 3 展示了算子执行计划与 32 个节点的资源使用之间的相关性。对于这个工作负载,Flink 和 Spark 都是 CPU 和磁盘绑定的。对于 Flink,我们注意到一个反循环的磁盘利用率(即与 CPU 使用率相关:CPU 增加到 100%,而磁盘下降到 0%),这可以通过使用基于排序的组合器进行分组来解释,在内存缓冲区中收集记录并在缓冲区填满时对缓冲区进行排序。在 CPU 方面,Flink 似乎比 Spark 更高效,并且使用相应操作保存结果所需的时间也更少,有助于减少端到端执行时间。
-
Discussion.
Flink 的聚合组件(基于排序的组合器)看起来比 Spark 的更高效,建立在其改进的自定义托管内存和面向类型的数据序列化之上。
B. Evaluating Text Search (Grep)
评估文本搜索(Grep)
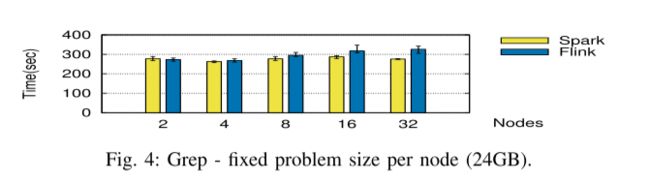
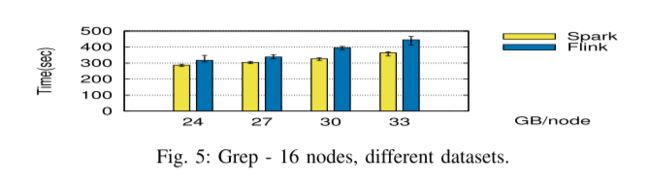
下一个基准测试在相同的场景中进行评估:每个节点的固定问题大小(图 4)和用于增加数据集的固定节点数(图 5),具有与表 II 相同的参数。
-
Weak and Strong Scalability.
当增加节点数量时,我们注意到 Spark 的执行得到了改进,大型数据集(16 和 32 个节点)的时间减少了 20%。 Spark 的优势在更大的数据集上也得以保留。 -
Resource usage.
为了理解这种性能差距,我们放大了图 6 中观察到的网络和磁盘使用率的主要差异。Flink 当前对 filter → count 运算符的实现导致后期资源使用效率低下。

-
Discussion.
对于在同一数据集上应用多个过滤层的复杂工作流,Spark 可以更多地利用其对 RDD(磁盘或内存)的持久性控制,并进一步减少执行时间。当前的 Flink 实现中缺少这个重要特性。
C. Shuffle, Caching and the Execution Pipeline (Tera Sort)
Shuffle、缓存和执行管道(Tera Sort)
我们以每个节点(32GB)的固定数据大小(最多 64 个节点)运行此基准测试,然后针对最多 100 个节点的固定数据集(3.5TB)(表 III 中的参数设置)。


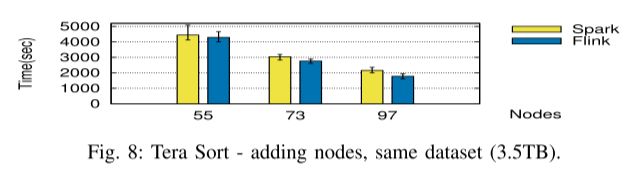
-
Weak Scalability.
我们注意到尽管 Flink 的平均性能优于 Spark,但与 Spark 相比,它也显示出每个实验结果之间的高差异。由于 Flink 的流水线性质,这种差异可能是由于 Flink 执行中的 I/O 干扰所致。 -
Strong Scalability.
Flink 的优势在于随着更大的集群而增加(图 8),这可以通过减少按每个节点排序的数据集导致的更少 I/O 干扰来解释。 -
Resource usage:
图 9 展示了算子执行计划与在具有 55 个节点的集群上对 3.5 TB 数据进行排序的资源使用之间的相关性。
一些重要的观察可以区分 Flink 和 Spark 的执行。首先,Flink 将执行流水线化,因此它在单个阶段中可视化,而在 Spark 中,阶段之间的分离非常清晰。

-
Discussion.
这个工作负载清楚地说明了 Flink 中智能优化器实现的执行管道的重要性。重新排序运算符可以更有效地使用资源并大大减少执行时间。
D. Bulk Iterations Performance (K-Means)
批量迭代性能(K-Means)
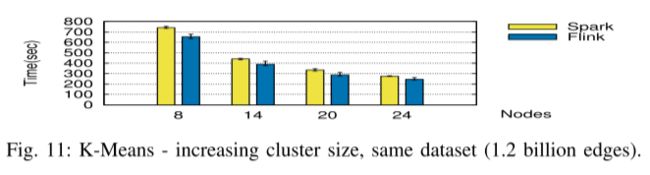
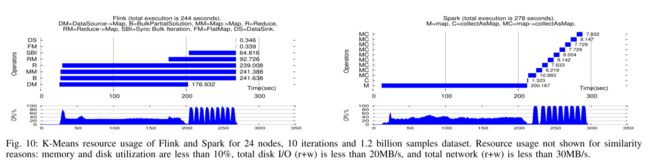
虽然 Spark 和 Flink 在添加节点(最多 24 个)时都可以优雅地扩展,但我们注意到 Flink 的批量迭代运算符及其管道机制比在 Spark 中实现的迭代的循环展开执行要好 10% 以上。
如图 10 所示,两个框架具有相似的资源使用情况,在加载数据点和处理迭代时受 CPU 限制。
E. Graph Processing (Page Rank and Connected Components)
图处理
我们选择了 3 个具有代表性的图数据集(分别来自 Twitter 和 Friendster 的小型 [36] 和中型 [37] 社交图,以及大型 [38] 一个,这是对公众可用的最大超链接图),详见表 IV。

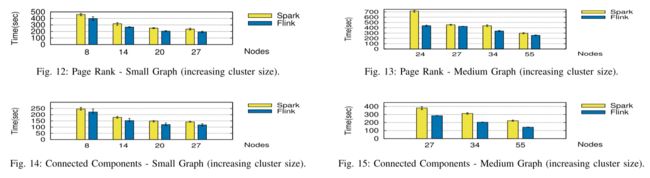
-
Small Graph.
我们注意到 Flink 在 Page Rank(图 12)和 Connected Components(图 14)方面的性能稍好一些。
Flink 更好的性能主要得益于它的批量迭代算子和它的管道特性。 -
Medium Graph:
Flink 的 Connected Components 比小图(Small Graphs)的性能要高得多(高达 30%),这主要是因为其高效的 delta 迭代算子。 -
Large Graph.
我们分别在 27、44 和 97 个节点的 3 个集群上对大图数据集进行了实验,如表 VII 所示。

表 VII:分别具有 5 次和 10 次迭代 (Iter.) 的 Page Rank (PR) 和 Connected Components (CC)。 Flink 的加载图(Load)阶段包括顶点数。
两个框架都成功地执行了具有 97 个节点的 Page Rank 和 Connected Components。 Flink 效率较低是因为并行度降低了:
我们怀疑两个问题:一个是流水线执行和 I/O 干扰,第二个是对大量网络缓冲区的低效管理。 -
Resource Usage.

我们确定了 Page Rank 的两个处理阶段:
第一个阶段是加载边和准备图形表示所必需的,而第二个阶段由迭代处理组成。
在第一阶段,Flink 和 Spark 都受 CPU 和磁盘限制,而在第二阶段,它们受 CPU 和网络限制。
Spark 在迭代期间使用磁盘来实现中间等级。
Flink 在迭代过程中使用了更多的网络,但它的管道机制和批量迭代器算子可以弥补并减少执行时间。
虽然 Flink 的 delta iterate 算子更有效地利用了 CPU,但它仍然被迫依赖磁盘来对大图进行迭代,因此 Spark 的结果更好。 -
Discussion.
Spark 需要仔细配置参数(用于并行性、分区等),这高度依赖于数据集,以获得最佳性能。
Flink 的案例中,需要确保分配足够的内存,以便其在内存中构建解决方案集的 CoGroup 算子能够成功执行。
VII. RELATED WORK
虽然广泛的研究工作致力于优化基于 MapReduce 的框架的执行,但在识别、分析和理解 Spark 和 Flink 等最新数据分析框架的性能问题方面进展相对较少。
- Execution optimization.执行优化
由于目标应用程序大多是数据密集型的,因此提高其性能的第一种方法是进行网络优化。 - Performance evaluation.绩效评估
该领域的绝大多数研究都集中在 Hadoop 框架上
总体而言,之前的大部分工作通常集中在大数据框架的一些特定的低级问题上,这些问题不一定与更高级别的设计有很好的相关性。
VIII. SUMMARY OF INSIGHTS AND CONCLUSION
VIII. SUMMARY OF INSIGHTS AND CONCLUSION
见解和结论总结
我们的主要发现表明,对于所有数据类型、大小和作业模式,并没有一个单一的框架:
对于大型图形处理,Spark 比 Flink 快约 1.7 倍,
对于批处理和小型图形工作负载,Flink的性能比 Spark 高出 1.5 倍,敏感地使用更少的资源,并且配置起来不那么繁琐。
- Memory management
内存管理在工作负载的执行中起着至关重要的作用,尤其是对于大型数据集。虽然在 JVM 中处理大量数据的常识意味着将它们作为对象存储在堆上,但这种方法有一些明显的缺点。
与 Spark 不同,Flink 不会在堆上积累大量对象,而是将它们存储在专用内存区域中,以避免过度分配和垃圾收集问题。所有操作符的实现方式都使得它们可以处理非常少的内存并且可以溢出到磁盘。 - The pipelined execution流水线执行
与 Spark 中的分阶段执行相比,流水线执行为 Flink 带来了重要的好处。流水线容错有几个问题,但 Flink 目前正朝着这个方向努力 [45]。 - Optimizations
优化是自动内置在 Flink 中的。 Spark 批处理和迭代作业必须手动优化,并通过对分区和缓存的细粒度控制来适应特定的数据集。 - Parameter configuration参数配置
参数配置在 Spark 中被证明是单调乏味的,具有与 RDD 管理相关的各种强制性设置(例如分区、持久性)
Flink 需要较少的内存阈值、并行度和网络缓冲区配置,并且不需要其序列化(因为它处理自己的类型提取和数据表示)
识别和理解不同架构组件和参数设置对资源使用以及最终对性能的影响,可能会引发对数据分析框架的新一轮研究。 Apache Beam [46] 就是这样一个例子,它提出了一个基于 Dataflow 模型 [47] 的统一框架,可用于在 Spark 和 Flink 等分离的分布式引擎上执行数据处理管道。