CVPR2021-RSTNet:自适应Attention的“看图说话”模型
0
写在前面
由于强大的建模能力,Transformer结构被用在一系列CV、NLP、Cross-modal的任务中。但是基于grid特征,用Transformer结构处理Image Captioning任务时,会存在两个问题。
因为Transformer最开始被提出时是用来处理序列信息的,所以grid特征需要flatten之后才能送入到Transformer的Encoder中,这就导致了特征的二维相对位置信息被破坏;第二,由于有的单词是跟图片内容紧密相关的,而有的单词(比如 with)跟图片相关性不大,因此模型在生成单词的时候同等的关注视觉信息就会导致sub-optimal的问题。
为了解决这两个问题,作者提出了GA和AA两个模块,并将这两个模块嵌入到Transformer中形成RSTNet,在COCO数据集达到了SOTA的性能。
Image Captioning任务是什么?
Image Captioning 任务的定义是给定一幅图片,生成用来描述图片内容的文本。一个AI系统不仅需要对图片进行识别,也需要理解和解释看到的图片内容,并且能够像人一样描述出图片中的对象之间的关系。
1
论文和代码地址

论文:https://openaccess.thecvf.com/content/CVPR2021/html/Zhang_RSTNet_Captioning_With_Adaptive_Attention_on_Visual_and_Non-Visual_Words_CVPR_2021_paper.html
代码:https://github.com/zhangxuying1004/RSTNet
2
Motivation

Image Captioning任务在特征使用方面,经历了grid→region→grid的过程,本文作者采用了grid特征,但是由于本文采用的结构是一个transformer-based的模型,而transformer又是针对序列任务提出的,所以在transformer中使用grid特征就需要把特征flatten(如上图a所示)
这就会导致一个问题,原来二维的图像特征变成一维的序列特征,空间信息丢失,造成sub-optimal的问题,因此作者提出了Grid-Augmented(GA) module,用grid之间的相对位置信息来增强特征的视觉表示。
Transformer能够捕捉视觉特征和序列之间的关系。然而,并非caption中的所有单词都是视觉单词,因此对所有单词都都相同程度的关注就会导致sub-optimal的问题(如上图b所示,很明显man是一个视觉单词,所以在生成的句子的时候应该更加关注这类单词,而with这种单词跟图像内容并没有什么关系,只需要根据语言的bias就可以学习到,所以这类单词在生成的时候就并不需要特别关注 )。
基于这个现象,作者提出了Adaptive Attention(AA) module,用来衡量视觉信息和语言上下文信息对于生成细粒度caption的贡献。
最终,作者将这两个模块嵌入到了Transformer中,得到RSTNet,在MS COCO数据上,在线上和线下测试中,达到了SOTA的性能。
3
方法
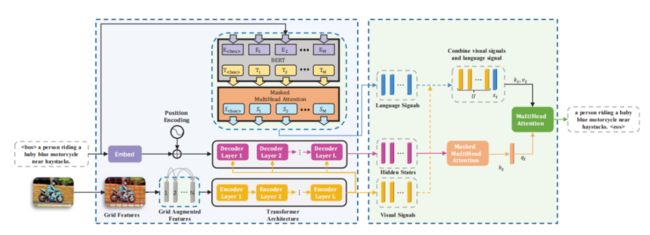
上图为RSTNet的总体结构,视觉特征用GA模块增强视觉表示,语言signal是用预训练的BERT模型提取,AA模块用来衡量视觉和语言的signal对于预测词语时的重要性。
3.1. Grid Feature Representation
对于给定的 个grid,以前的transformer就是直接将他们flatten,然后送入到encoder中,但是这么做会损失二维的位置信息,因此作者提出了GA模块,来建模相对位置关系。
首先,作者对每个grid都计算了一对二维的相对位置,其中 为左上角的相对位置坐标, 为右下角的相对位置坐标。然后根据左上角和右下角的相对位置坐标就可以计算相对中心坐标 :

然后就可以获得第i个grid和第j个grid的相对位置信息:

3.2. Language Feature Representation

为了提取语言signal,作者采用了一个预训练的BERT的模型,考虑到只能在测试阶段访问部分生成的句子信息,作者在BERT模型之上添加了一个类似于Transformer的mask注意模块。模型结构如上图所示。
这个过程用公式可以表示为:

作者用交叉熵损失函数来fine-tuning这个语言模型。在进行特征提取的时候,将所有参数冻结,mask注意模块的输出作为RSTNet中语言特征的表示。
3.3. Relationship-Sensitive Transformer (RSTNet)
3.3.1. Encoder
Encoder中的特征提取与Transformer中相似,grid特征首先被flatten,然后用FC将通道维度embedding到512,后面接上Transformer的Encoder结构(Self-Attention+FFN),Self-ATtention过程的公式表示如下:

3.3.2. Grid Augmented (GA) Module
GA模块用于增强grid特征的相对位置表示,因此,在Self-Attention的
Scaled Dot-Product Attention之后,作者还加入上面计算的相对位置表示,用公式可以表示为:
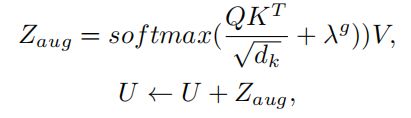
其中 为相对位置的信息编码信息。
3.3.3. Decoder
语言的序列信息,首先通过word embedding来处理,然后加入位置编码,然后与Encoder最后一层输出的特征进行融合,用来预测生成的序列,用公式可以表示为:

该解码过程可以看作是在部分生成的句子的序列特征的指导下合并视觉信息的过程,以得到当前单词的hidden state的过程。然而,当前的单词可能是一个非视觉化的单词(比如with),在这种情况下生成预测单词,语言上下文信息应该比视觉信号发挥更重要的作用。因此作者提出了AA模块。
3.3.4. Adaptive Attention (AA) Module
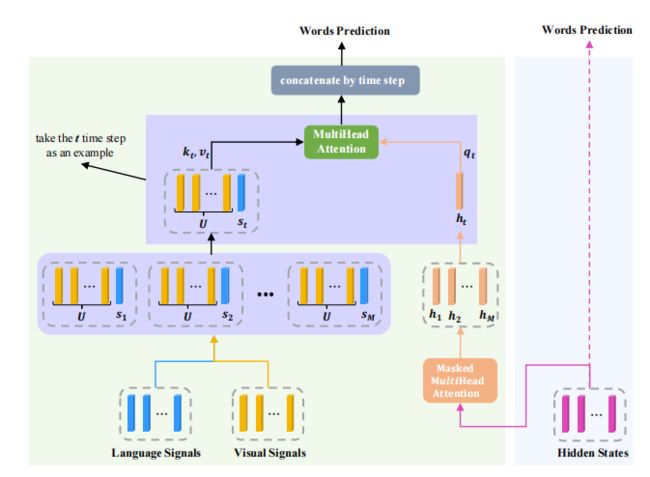
作者在Transformer Decode之上构建了自适应注意模块,传统的Transformer直接根据hidden state进行单词的预测,本文作者将在预测时候将language signal,visual signal和hidden state进行了融合,用来预测生成的单词(如上图所示),具体计算如下所示:
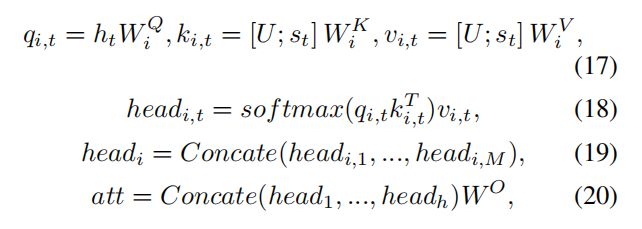
3.4. Visualness
基于adaptive attention,作者提出了一个属性visualness 。
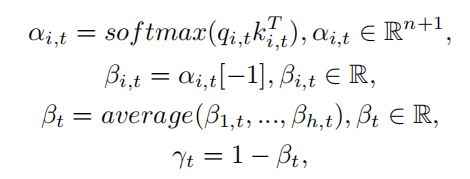
定量地衡量了第t个单词的可视化性程度。

如上图所示Visualness分数高的词大多是可以被可视化的词,Visualness分数低的词大多是与图片内容不是相关的词语。
4
实验
4.1. 消融实验
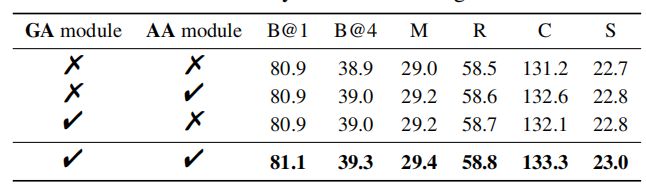

上表为GA模块和AA模块在不同backbone(上面为ResNeXt101,下面为ResNeXt152)的消融实验,可以看出GA模块和AA模块对于性能的提升都有促进作用。
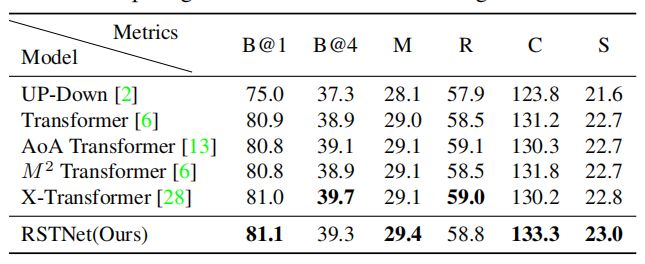
4.2. Offline Evaluation

如上表所示,相比于其他方法,RSTNet在大多数指标上都能SOTA。
4.3. Comparison with strong baselines
为了消除特征的影响,作者在相同特征下也做了实验,可以看出RSTNet在相同特征下也能取得比较好的性能。
4.4. Online Evaluation
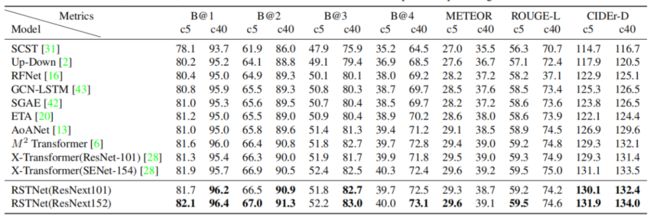
在COCO线上的测试中,RSTNet在大多数指标上也能SOTA。
4.5. Qualitative Analysis

从上图可以看出,相比于Baseline,RSTNet生成的句子会更加准确一些。
5
总结
作者发现Transformer在image captioning任务上处理grid特征,会有两个缺点。第一,grid特征的二维相对位置信息被破坏了;第二,模型在生成单词的时候并不一定需要关注视觉特征。
因此,作者提出了GA和AA两个模块来解决这个问题,并将这两个模块嵌入到Transformer中形成RSTNet,在COCO数据集上达到了SOTA的性能。

备注:TFM

Transformer交流群
Transformer等最新资讯,若已为CV君其他账号好友请直接私信。
在看,让更多人看到 