Pytorch源码学习之五:torchvision.models.densenet
0. 基本知识
DenseNet论文地址
DenseNet加强了每个Dense Block内部的连接,每层输出与之前所有层进行concat连接,使用三个Dense Block的网络示意图如下:

每个Block之间使用Transition(BN+ReLU+Conv+AvePool),最后使用全连接层作为分类器.
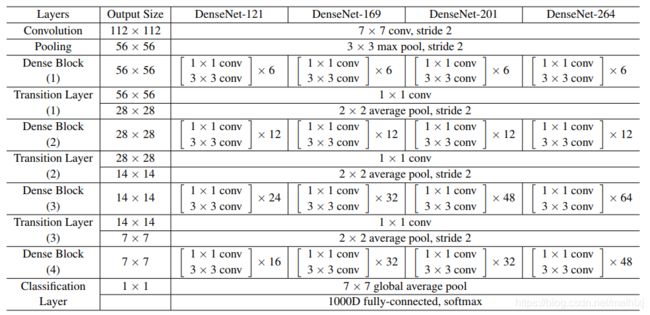
torchvision实现的DenseNet网络结构同论文,如下:
1.torchvision源码
以下为torchvision实现的DenseNet的源码,具体源码可见
torchvision.models.densenet
import re
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.hub import load_state_dict_from_url
from collections import OrderedDict
__all__ = ['DenseNet', 'densenet121', 'densenet169', 'densenet201', 'densent161']
model_urls = {
'densenet121': 'https://download.pytorch.org/models/densenet121-a639ec97.pth',
'densenet169': 'https://download.pytorch.org/models/densenet169-b2777c0a.pth',
'densenet201': 'https://download.pytorch.org/models/densenet201-c1103571.pth',
'densenet161': 'https://download.pytorch.org/models/densenet161-8d451a50.pth',
}
class _DenseLayer(nn.Sequential):
def __int__(self, num_input_features, growth_rate, bn_size, drop_rate):
super(_DenseLayer, self).__init__()
self.add_module('norm1', nn.BatchNorm2d(num_input_features)), #BN
self.add_module('relu1', nn.ReLU(inplace=True)), #ReLU
self.add_module('conv1', nn.Conv2d(num_input_features, bn_size * growth_rate,
kernel_size=1, stride=1, bias=False)), #1x1 conv
self.add_module('norm2', nn.BatchNorm2d(bn_size * growth_rate)), #BN
self.add_module('relu2', nn.ReLU(inplace=True)), #ReLU
self.add_module('conv2', nn.Conv2d(bn_size * growth_rate, growth_rate,
kernel_size=3, stride=1, padding=1, bias=False)), #3x3 conv
self.drop_rate = drop_rate
def forward(self, x):
new_features = super(_DenseLayer, self).forward(x)
if self.drop_rate > 0:
new_features = F.dropout(new_features, p=self.drop_rate, training=self.training )
return torch.cat([x, new_features], 1) #x已经包含了之前cat的channel,仅需将最新的channel进行cat
class _DenseBlock(nn.Sequential):
def __init__(self, num_layers, num_inputs_features, bn_size, growth_rate, drop_rate):
super(_DenseLayer, self).__init__()
for i in range(num_layers):
layer = _DenseLayer(num_inputs_features + i * growth_rate, growth_rate,
bn_size, drop_rate) #该block中第i层的channel数为num_inputs_features + i * growth_rate
self.add_module('denselayer%d' % (i + 1), layer) #每次累加growth_rate个channel数
class _Transition(nn.Sequential):
def __init__(self, num_input_features, num_output_features):
super(_Transition, self).__init__()
self.add_module('norm', nn.BatchNorm2d(num_input_features)) #BN
self.add_module('relu', nn.ReLU(inplace=True)) #ReLU
self.add_module('conv', nn.Conv2d(num_input_features, num_output_features,
kernel_size=1, stride=1, bias=False)) #1x1 conv
self.add_module('pool', nn.AvgPool2d(kernel_size=2, stride=2)) # 2x2 average pool, stride 2
class DenseNet(nn.Module):
def __init__(self, growth_rate=32, block_config=(6, 12, 24, 16),
num_init_features=64, bn_size=4, drop_rate=0, num_classes=1000):
super(DenseNet, self).__init__()
self.features = nn.Sequential(OrderedDict([
('conv0', nn.Conv2d(3, num_init_features, kernel_size=7, stride=2,
padding=3, bias=False)), #7x7 conv stride=2
('norm0', nn.BatchNorm2d(num_init_features)), #BN
('relu0', nn.ReLU(inplace=True)), #ReLU
('pool0', nn.MaxPool2d(kernel_size=3, stride=2, padding=1)), #3x3 maxpool, stride=2
]))
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = _DenseBlock(num_layers=num_layers, num_inputs_features=num_features,
bn_size=bn_size, growth_rate=growth_rate, drop_rate=drop_rate)#Dense Block (1-4)
self.features.add_module('denseblock%d' % (i+1), block)
num_features = num_features + num_layers * growth_rate #每个block增加num_layers * growth_rate层
if i != len(block_config) - 1: #非最后一个block,要加上Transition Layer
trans = _Transition(num_input_features=num_features,
num_output_features=num_features // 2)
self.features.add_module('transition%d' % (i + 1), trans)
num_features = num_features // 2 #Transition Layer层输出channel为输入的1/2
self.features.add_module('norm5', nn.BatchNorm2d(num_features)) #BN
self.classifier = nn.Linear(num_features, num_classes) #全连接层分类器
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
features = self.features(x)
out = F.relu(features, inplace=True)
out = F.adaptive_avg_pool2d(out, (1,1)).view(features.size(0), -1) #全连接层之前的 global average pool
out = self.classifier(out)
return out
def _load_state_dict(model, model_url, progress):
pattern = re.compile(
r'^(.*denselayer\d+\.(?:norm|relu|conv))\.((?:[12])\.(?:weight|bias|running_mean|running_var))$')
state_dict = load_state_dict_from_url(model_urls, progress=progress)
for key in list(state_dict.keys()):
res = pattern.match(key)
if res:
new_key = res.group(1) + res.group(2)
state_dict[new_key] = state_dict[key]
del state_dict[key]
model.load_state_dict(state_dict)
def _densenet(arch, growth_rate, block_config, num_init_features, pretrained, progress, **kwargs):
model = DenseNet(growth_rate, block_config, num_init_features, **kwargs)
if pretrained:
_load_state_dict(model, model_urls[arch], progress)
return model
def densenet121(pretrained=False, progress=True, **kwargs):
return _densenet('densenet121', 32, (6, 12, 24, 16), 64, pretrained, progress, **kwargs)
def densenet161(pretrained=False, progress=True, **kwargs):
return _densenet('densenet161', 48, (6, 12, 36, 24), 96, pretrained, progress, **kwargs)
def densenet169(pretrained=False, progress=True, **kwargs):
return _densenet('densenet169', 32, (6, 12, 32, 32), 64, pretrained, progress, **kwargs)
def densenet201(pretrained=False, progress=True, **kwargs):
return _densenet('densenet201', 32, (6, 12, 48, 32), 64, pretrained, progress, **kwargs)
2. 一些有趣的用法
2.1 继承nn.Sequential
这里在定义_DenseLayer, _DenseBlock,_Transition时,继承nn.Sequential而非nn.Module,基本用法与nn.Module相同,需要写__init__和forward两个函数,前者用来搭建网络,后者用前向传播.
class _DenseLayer(nn.Sequential):
def __init__(self, num_input_features, growth_rate, bn_size, drop_rate):
super(_DenseLayer, self).__init__()
...
def forward(self, x):
new_features = super(_DenseLayer, self).forward(x) #注意这里的继承
...
不同之处在于搭建网络结构试,采用self.add_module(name, module)将单层添加到容器.
self.add_module('norm1', nn.BatchNorm2d(num_input_features)),
self.add_module('relu1', nn.ReLU(inplace=True)),
...
for i in range(num_layers): #通过循环自动命名
layer = ...
self.add_module('denselayer%d' % (i + 1), layer)
2.2 平均池化层
nn.AvgPool2d(kernel_size=2, stride=2) #平均池化
# kernel_size: the size of the window
# stride: the stride of the window
# padding: implicit zero padding to be added on both sides
# ceil_mode:True=向上取整,默认向下取整
2.3 torch.nn.functional.dropout
torch.nn.functional.dropout(input, p, training, inplace)
# p:probability of an element to be zeroed, 默认0.5
# training:是否采用dropout
# inplace: if True, will do this operation in-place,默认False
2.4 torch.nn.functional.adaptive_avg_pool2d
torch.nn.functional.adaptive_avg_pool2d(input, output_size)
out = F.adaptive_avg_pool2d(out, (1,1)).view(features.size(0), -1) #全连接层之前的 global average pool