【论文笔记】TransReID: Transformer-based Object Re-Identification
TransReID
论文地址:https://arxiv.org/abs/2102.04378
代码:https://github.com/damo-cv/TransReID
这篇笔记是按照自己本人的习惯写的(一些词语、句子喜欢用英语表示);在看这篇论文之前,最好了解下ViT。感谢指教:)
程序框图如果有人想看的话,我就整理一下= =
论文阅读
Abstract
one of the key challenges in ReID:Extracting robust feature representation.
CNN:(缺点)一次只处理一个局部邻域,由于卷积和下采样(池化、跨步卷积)操作容易造成细节信息丢失。
ReID
- 双分支学习框架——设计一个与全局分之并行的jigsaw patch module (JPM) 分支,该分支通过shift、patch shuffle重新排列patch embeddings 以此生成更鲁棒的特征;
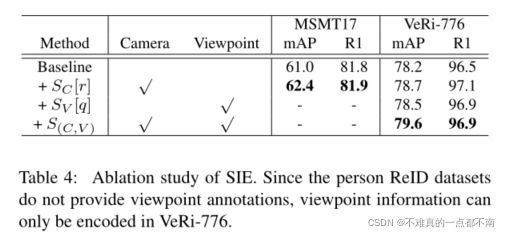
- side information embeddings (SIE):将摄像头或视角这些非视觉信息插入到learned embeddings中,以减轻它们引起的偏差。
1. Introduction
框架:CNN存在的问题→trandformer的优点→仍需改进的地方→提出TransReID
CNN存在的问题
ReID的关键:提取鲁棒、区分性的特征。
CNN-based method存在的问题:
- CNN集中关注小范围的判别区域,没有用到全局范围内的丰富结构模式rich structural patterns in a global scope;
- 含有更多细节信息detail information的细粒度特征很重要,CNN的下采样操作(池化、跨步卷积)减小了输出特征图的分辨率,影响模型对 相似外观物体的细节特征 的判别能力。
Trandformer的优点
与CNN相比,ViT、DeiT证明纯transformer模型在 图像识别的特征提取 这一方面也很有效。
由于multi-head attention的引入和下采样的移除,transformer更适合解决上面提到的两个问题,理由:
- multi-head attention捕获long range dependencies,驱使模型关注更多样的人体部位(与CNN相比);
!
- 没有了下采样,transformer能够保留更多的细节信息。
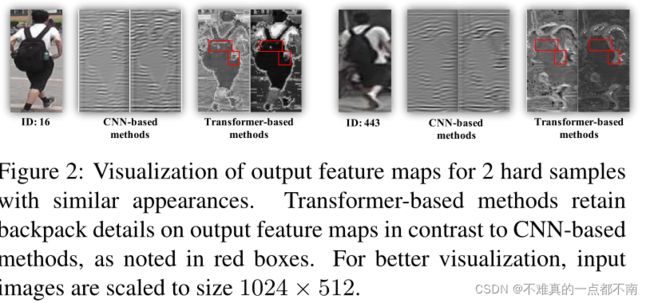
仍需改进的地方
针对ReID的一些问题(遮挡、姿势变化、相机视角),仍需做出改进。
- 局部特征local part features、侧边信息side information在CNN中被认为是增强鲁棒性基本、有效的方法。Learning part/stripe aggregated features makes it robust against occlusions and misalignments.然而,将rigid stripe part methods 从CNN模型扩展到transformer模型,由于将全局序列分成几个孤立的序列,可能会破坏long-range dependencies。
- 另外,考虑到摄像头、视角这些侧边信息(side information),应构建一个不变特征空间(an invariant feature space),减少side information引起的偏差。然而,CNN中side information的复杂设计,如果直接运用到transformer中,不能充分利用the inherent encoding capabilities of transformers。
对于transformer来说,要想解决以上问题,特定模块的设计必不可少。
提出TransReID
- 通过一些关键的适应性调整,构建了一个基于纯transformer的baseline。
- 为扩展long-range dependencies、增强特征稳健性及扰动不变性,提出jigsaw
patches module(JPM),由shift 与patch shuffle 操作组成,重新排列patch embeddings,进一步进行特征学习。在模型的最后一层,JPM与全局分支并行,JPM提取鲁棒特征。 - 引入了side information embedding(SIE)。提出了一个统一的框架,通过learned embeddings有效地整合非视觉线索——也就是encodes side information by learnable embeddings,以减小摄像头或视角导致的数据偏差。如下图,SIE可以减小相机间、相机内匹配对的相似性差异。

2. Related Work
2.1 Object ReID
相关损失函数:cross-entropy loss (ID loss) 和triplet loss
细粒度特征
Side information
2.2 Pure Transformer in Vision
ViT DeiT
3. Methods
3.1 :一些关键的改进(策略)得到baseline:Overlapping Patches+position embeddings(双线性插值)+监督学习(交叉熵损失函数+三元损失函数)
3.2 :JIM:baseline只用到全局特征→遇到遮挡、错位时需要局部特征→CNN采用局部细粒度特征→简单直接的方法不可行→提出JPM(shift+patch shuffle)
3.3:SIE
JIM、SIE以端到端方式联合训练。
3.1 Transformer-based strong baseline
两个主要阶段:特征提取+监督学习。
baseline的结构与ViT大致一致:
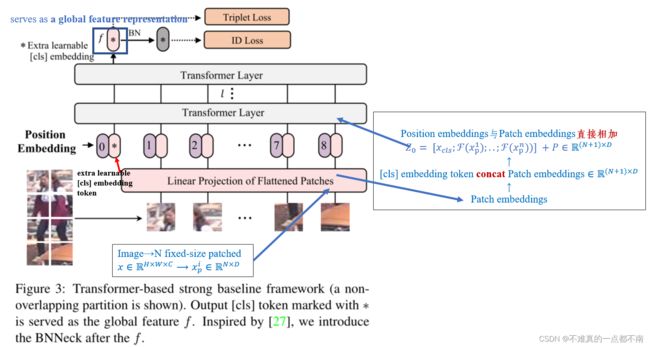
Overlapping Patches:ViT、DeiT将图像分割成不重叠的patches→patches周围的局部邻近结构信息丢失→我们使用滑动窗口来生成patches with overlapping pixels。
步长: S S S、patch的大小 P P P(一般 S S S比 P P P小),则相邻两个patch重叠区域的大小: ( P − S ) × P (P−S)×P (P−S)×P。像素 H × W H×W H×W的输入图像被分割成 N N N个patches:
N = N H × N W = [ H + S − P S ] × [ W + S − P S ] N=N_H×N_W=[\frac{H+S-P}S]×[\frac{W+S-P}S] N=NH×NW=[SH+S−P]×[SW+S−P]
补丁越多,性能越好,但计量算也更大。
Position Embeddings:与ViT相同,Position Embeddings编码相对应patches的位置信息,由于ReID任务的图像像素可能会与分类任务的图像像素不同,ImageNet中预训练的position embeddings不能直接拿来用,这里引入双线性插值。
监督学习:损失函数包括ID loss L I D L_{ID} LID——cross-entropy loss without label smooth、三元损失函数(with soft-margin) L T = l o g [ 1 + e x p ( ∣ ∣ f a − f p ∣ ∣ 2 2 − ∣ ∣ f a − f n ∣ ∣ 2 2 ) ] L_T=log[1+exp(||f_a-f_p||_2^2-||f_a-f_n||_2^2)] LT=log[1+exp(∣∣fa−fp∣∣22−∣∣fa−fn∣∣22)]
3.2 Jigsaw patches module(JPM)
transformer-based strong base line利用图像的全局信息。
但遇到遮挡、错位时,我们只能观察到物体的部分信息,CNN一般使用细粒度局部特征解决这些问题。
在transformer中,简单直接的方式是将原模型最后一层的特征 Z l − 1 = [ z l − 1 0 ; z l − 1 1 , . . . , z l − 1 N ] Z_{l-1}=[z_{l-1}^0;z_{l-1}^1,...,z_{l-1}^N] Zl−1=[zl−10;zl−11,...,zl−1N]( Z l − 1 = [ z l − 1 0 ; z l − 1 1 , . . . , z l − 1 N ] Z_{l-1}=[z_{l-1}^0;z_{l-1}^1,...,z_{l-1}^N] Zl−1=[zl−10;zl−11,...,zl−1N]=[cls]token+N个patch embedings)中的 [ z l − 1 1 , . . . , z l − 1 N ] [z_{l-1}^1,...,z_{l-1}^N] [zl−11,...,zl−1N]分k组,每组都concate [cls] token z l − 1 0 z_{l-1}^0 zl−10 。将这k个特征组送入到一层transfoemer layer中,得到输出,得到输出{ f l j ∣ j = 1 , 2... , k f_l^j|j=1,2...,k flj∣j=1,2...,k},以此学习k个局部特征。
但这一方法没有充分利用global dependencies。
JPM:shuffle the patch embeddings,先置换再分组,即shuffle=shift+patch shuffle 。另外,在训练中引入干扰帮助提高模型的稳健性。具体步骤如下:
(要记得 Z l − 1 = [ z l − 1 0 ; z l − 1 1 , . . . , z l − 1 N ] Z_{l-1}=[z_{l-1}^0;z_{l-1}^1,...,z_{l-1}^N] Zl−1=[zl−10;zl−11,...,zl−1N]=[cls]token+N个patch embedings)
- The shift operation:将 Z l − 1 = [ z l − 1 0 ; z l − 1 1 , . . . , z l − 1 N ] Z_{l-1}=[z_{l-1}^0;z_{l-1}^1,...,z_{l-1}^N] Zl−1=[zl−10;zl−11,...,zl−1N]中 除[cls] token的 N 个patches [ z l − 1 1 , . . . , z l − 1 N ] [z_{l-1}^1,...,z_{l-1}^N] [zl−11,...,zl−1N]中 前 m 个patches移到最后(shift m 步),得到将 ∗ ∗ [ z l − 1 m + 1 , z l − 1 m + 2 , . . . , z l − 1 N , z l − 1 1 , z l − 1 2 , . . . , z l − 1 m ] **[z_{l-1}^{m+1},z_{l-1}^{m+2},...,z_{l-1}^N,z_{l-1}^{1},z_{l-1}^{2},...,z_{l-1}^m] ∗∗[zl−1m+1,zl−1m+2,...,zl−1N,zl−11,zl−12,...,zl−1m]。**
- The shift operation将上面shift过的patches进一步shuffle成 k 组patches,表示为 [ z l − 1 x 1 , z l − 1 x 2 , . . . , z l − 1 x N ] [z_{l-1}^{x_1},z_{l-1}^{x_2},...,z_{l-1}^{x_N}] [zl−1x1,zl−1x2,...,zl−1xN]。
通过shift和shuffle操作,生成的局部特征 f l j f_l^j flj覆盖了来自不同部位的patches,具有全局判别能力。
总结:如下图所示,在原Vit/basline 模型transformer block模块中的最后一层( l l l层)transformer layer的基础上,增加了一个分支,变成两个分支(两个分支的输入都是上一层即 l − 1 l-1 l−1层的输出 Z l − 1 = [ z l − 1 0 ; z l − 1 1 , . . . , z l − 1 N ] Z_{l-1}=[z_{l-1}^0;z_{l-1}^1,...,z_{l-1}^N] Zl−1=[zl−10;zl−11,...,zl−1N])
- Global Branch :标准transformer block模块中的最后一层( l l l层)transformer layer,输出 Z l = [ f g ; z l 1 , . . . , z l n ] Z_{l}=[f_g;z_l^1,...,z_l^n] Zl=[fg;zl1,...,zln], f g f_g fg([cls] token)是全局特征**。**
- Jigsaw Branch:对 Z l − 1 = [ z l − 1 0 ; z l − 1 1 , . . . , z l − 1 N ] Z_{l-1}=[z_{l-1}^0;z_{l-1}^1,...,z_{l-1}^N] Zl−1=[zl−10;zl−11,...,zl−1N]进行JPM操作得到k 组patch embeddings,每组都concate [cls] token —— z l − 1 0 z_{l-1}^0 zl−10,然后被输入到另一个transformer layer中,得到k组输出结果,每组输出结果的第一个向量为局部特征 ∗ ∗ f l j **f_l^j ∗∗flj。**
- 使用全局特征和局部特征对整个模型进行训练,损失函数: L = L I D ( f g ) + L T ( f g ) + 1 k ∑ j = 1 k ( L I D ( f l j ) + L T ( f l j ) ) L=L_{ID}(f_g)+L_{T}(f_g)+\frac1k\sum_{j=1}^k(L_{ID}(f_l^j)+L_{T}(f_l^j)) L=LID(fg)+LT(fg)+k1∑j=1k(LID(flj)+LT(flj))
在推理阶段,将全局特征与局部特征进行concate 作为最终的特征表达 [ f g , f l 1 , . . . , f l k ] [f_g,f_{l}^1,...,f_{l}^k] [fg,fl1,...,flk]。如果仅使用全局特征 f g f_g fg([cls] token)会减少计算量,但是性能也会稍许下降。

3.3 Side Information Embeddings(SIE)
摄像头、视点变化,容易导致模型分辨不出不同角度的同一物体。
受Postion embeddings(encode positional information adopting learnable embeddings)启发,我们将非视觉信息整合到patch embeddings中,同样用可学习的一维embeddings保存side information。
数据集camera ID的总数量为 N C N_C NC,初始化learned side information 为 S C ∈ R N C × D S_C\in\R^{N_C×D} SC∈RNC×D,(D:embeddings dimension)。例如,如果一个图像的camera ID是 r r r,那么它的camera embedding表示为 S C [ r ] S_C[r] SC[r]。
同一副图像不同patch的Postion embeddings是不同的,但是camera embeddings是相同的。
如果可以通过视角估计算法、人工标注获得对象的视角信息,我们也可以编码视角标签为 S V [ q ] S_V[q] SV[q], S V ∈ R N V × D S_V\in\R^{N_V×D} SV∈RNV×D。
如何整合这两种信息?如果直接相加 S C [ r ] + S V [ q ] S_C[r]+S_V[q] SC[r]+SV[q],由于冗余或对抗性信息,这两个embeddings可能会相互抵消。因此,我们提出将这两个信息联合编码: S ( C , V ) ∈ R N C × N V × D S_{(C,V)}\in\R^{N_C×N_V×D} S(C,V)∈RNC×NV×D。
这样,带有camera ID是及viewpoint ID的输入序列变为 Z 0 ′ = Z 0 + λ S ( C , V ) [ r ∗ N k + q ] Z_0^{'}=Z_0+\lambda S_{(C,V)}[r*N_k+q] Z0′=Z0+λS(C,V)[r∗Nk+q], Z 0 Z_0 Z0为原始输入序列, λ \lambda λ为平衡SIE权重的超参数。
4. Experiments
4.1 Datasets

4.2 Implementation
Size:256×128(Person )、256×256(Vehicle);
Data Augmention:random horizontal flipping、 padding、 random cropping 、random erasing;
Batch Size:64 with 4 images per ID;
Optimizer:SGD with a momentum of 0.9 and the weight decay of 1e-4
Learning rate :初始0.008 with cosine learning rate decay
JPM:m= 5、 k= 4(person), m= 8、k= 4(vehicle)
评测指标:CMC、mAP
4.3 Results of Transform-based Baseline

当减小Overlapping Patches中滑动窗口的步长 S 时,baseline的性能有所提高,但推理时间会增加。
作者认为DeiT/ViT在计算效率方面仍有很大的提升空间。
4.4. Ablation Study of JPM

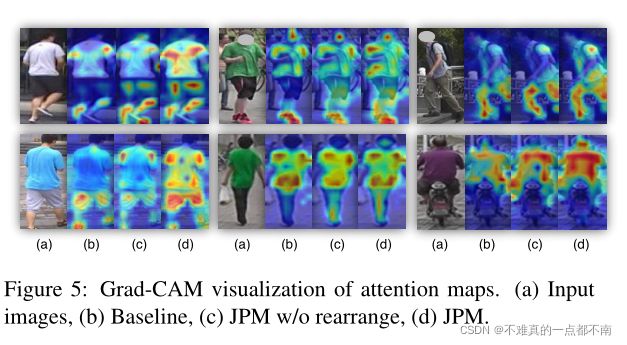
“w/o rearrange”表示patches feature被直接分割成几部分,没有重排(shift+shuffle),“w/o local”表示仅使用全局特性监督.
- 如上表所示,增加groups的数量可以提高性能,但是也会增加推理时间,为了权衡速度和性能,作者这设定k=4。
- shift 和 shuffle 操作有助于模型学习更具判别性的特征。
- 在推理阶段仅使用全局特征(训练时仍使用完整的JPM),性能下降幅度很小。如果考虑到成本,推理时可以只使用全局特征。
- 如下图所示,JPM有助于模型学习更多的 全局上下文信息和区分性区域,使模型对更有鲁棒性。
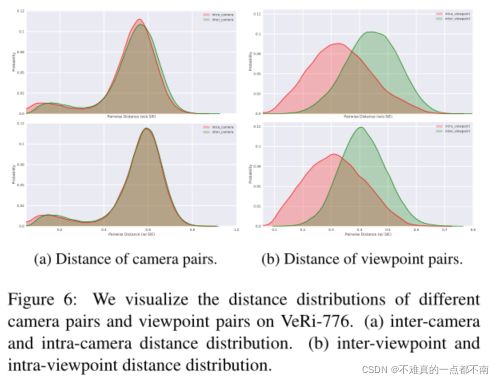
4.5 Ablation Study of SIE
- 准确率的提升
- 距离分布
- Impact of the hyper-parameter λ

4.6 Ablation Study of TransReID

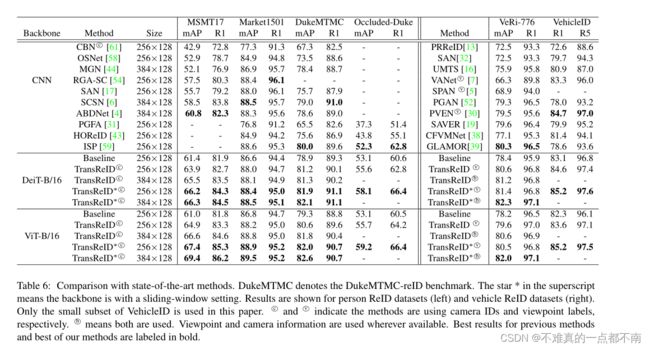
4.7 Comparison with State-of-the-Art Methods