KNN算法python自实现
KNN的工作原理:给定一个已知标签类别的训练数据集,输入没有标签的新数据后,在训练数 据集中找到与新数据最邻近的k个实例,如果这k个实例的多数属于某个类别,那么新数据就属于这个类 别。
根据电影的打斗镜头和接吻镜头为属性,判断电影类别
import pandas as pd
%matplotlib inline
#构建字典
rowdata={'电影名称':['合约爱情','大约在冬季','前任3','叶问','唐人街探案','战狼2'],
'打斗镜头':[1,5,12,108,112,115],
'接吻镜头':[101,89,97,5,9,8],
'电影类型':['爱情片','爱情片','爱情片','动作片','动作片','动作片']
}
#转化为dataframe
data=pd.DataFrame(rowdata)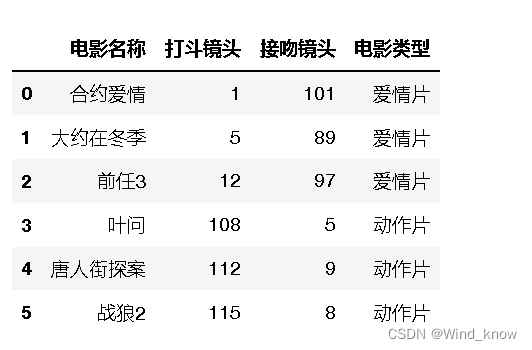
#新数据
new_data = [24,67]
##计算已知类别数据集中的点与当前点之间的距离
# 利用series广播功能,列数据分别与新数据相减后,再平方,然后再按列求和,最后再开根,得到每个数据与新数据的欧氏距离
d=(((data.iloc[:,1:3]-new_data)**2).sum(1))**0.5
d=list(d)
d 
#构造新的dataframe
dist_1=pd.DataFrame({
"distance":d,
"labels":data['电影类型']# 最好用dataSet.iloc[:, 3]) 方便代码可移值
})
dist_1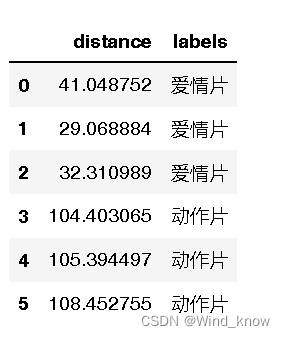
dist_1.sort_values(by='distance')#默认升序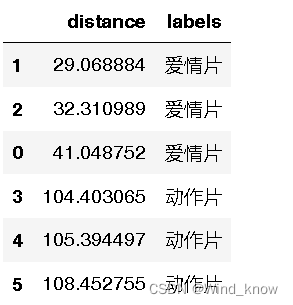
#选取距离最近(小)的k个点 设置k=4
dr=dist_1.sort_values(by='distance')[:4]
dr
# 确定前k个点所在类别的出现频率
re=dr['labels'].value_counts()
re 
# 选择频率最高的类别作为当前点的预测类别
result=[]
result.append(re.index[0])
result
KNN简单好用,容易理解,精度高,可用于数值型数据和离散型数据 无数据输入假定 适合对稀有事件进行分类,但样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少),可理解性比较差,无法给出数据的内在含义。
k-近邻算法没有进行数据的训练,直接使用未知的数据与已知的数据进行比较,得 到结果。因此,可以说,k-近邻算法不具有显式的学习过程。