TensorFlow 2.x
一、TensorFlow层次结构
总共五层:硬件层、内核层、低阶API,中阶API,高阶API。
低阶API:由python实现的操作符,提供封装了C++内核的低级API指令
中阶API:由python实现的模型组件。主要包括数据管道tf.data,特征列tf.feature_column,激活函数tf.nn,模型层tf.keras.layers,损失函数tf.keras.losses,评估函数tf.keras.metrics,优化器tf.keras.optimizer,回调函数tf.keras.callbacks。
高阶:由python实现的模型成品,主要为tf.keras.models提供的模型的类接口,主要包括:
模型的构建(Sequential、functional API、Model子类化)、
模型的训练(内置fit方法、内置train_on_batch方法、自定义训练循环、单GPU训练模型、多GPU训练模型、TPU训练模型)、
模型的部署(tensorflow serving部署模型、使用spark(scala)调用tensorflow模型)。

二、基础
2.1 创建张量
2.1.2 张量的创建方式
# 常数
tf.constant(value, dtype = tf.float32)
a = tf.constant([1,2], dtype = tf.float32)
# 生成间隔为delta的张量
tf.range(start, limit = end, delta = 1) # [start, end - 1]
a = tf.range(0, 50) # type(a) tensorflow.python.framework.ops.EagerTensor
# 生成间隔均匀的张量
tf.linspace(start, stop, num)
# 生成num个全0张量
tf.range(0, 10, 5) # numpy=array([0, 5], dtype=int32)
tf.linspace(0, 10, 5) # numpy=array([ 0. , 2.5, 5. , 7.5, 10. ])
tf.zeros(num)
# 生成Num个全1张量
tf.ones(num)
# 生成和input一样大小的全0张量
tf.zeros_like(input)
# 生成shape为dim,全为value的张量
tf.fill(dims, value)
import numpy as np
a = np.array(((1,2,3),(4,5,6)))
tf.zeros_like(a)
#通过tf.Variable构造一个variable添加进图中,Variable()构造函数需要变量的初始值(是一个任意类型、任意形状的tensor),这个初始值指定variable的类型和形状。通过Variable()构造函数后,此variable的类型和形状固定不能修改了,但值可以用assign方法修改。
如果想修改variable的shape,可以使用一个assign op,令validate_shape=False.
通过Variable()生成的variables就是一个tensor,可以作为graph中其他op的输入。
Tensor类重载的所有操作符都被转载到此variables中,所以可以通过对变量调用方法,将节点添加到图形中。
2.1.2 维度变换
tf.reshape():改变张量的形状
tf.squeeze():减少维度为1的维度
tf.expand_dims(input, axis):增加维度
tf.transpose(a, perm=Non):交换维度
a = tf.Variable(((1,2,3,8),(4,5,6,9)))
print('a', a.shape, a)
b = tf.reshape(b,(4,2))
print('b', b.shape, b)
c = tf.reshape(b,(2,4,1))
print('c', c.shape, c)
d = tf.squeeze(c)
print('d', d.shape, d)
e = tf.expand_dims(d,0)
print('e',e.shape, e)
f = tf.transpose(e, perm = (0,2,1))
print('f', f.shape, f)
2.1.3 合并分割
tf.concat([a,b], axis):连接张量,不会增加维度
tf.stack([a,b], axis):堆叠,会增加维度,是指在axis进行堆叠
tf.split(input, axis):分割张量
a = tf.Variable([[1,1,1,1],[1,1,1,1]])
b = tf.Variable([[0,0,0,0],[0,0,0,0]])
c = tf.concat([a,b], 0) #(4,4)
d = tf.concat([a,b], 1) #(2,8)
e = tf.stack([a,b],0) #(2,2,4)
[[[1 1 1 1]
[1 1 1 1]]
[[0 0 0 0]
[0 0 0 0]]]
f = tf.stack([a,b],1) #(2,2,4)
[[[1 1 1 1]
[0 0 0 0]]
[[1 1 1 1]
[0 0 0 0]]]
g = tf.stack([a,b], 2) #(2,4,2)
[[[1 0]
[1 0]
[1 0]
[1 0]]
[[1 0]
[1 0]
[1 0]
[1 0]]]
a1 = tf.split(g,2, axis=2)
a1,a2 = tf.split(g,2, axis=2)
a1 = tf.squeeze(a1)
a2 = tf.squeeze(a2)
tf.Tensor([[1 1 1 1]
[1 1 1 1]], shape=(2, 4), dtype=int32)
tf.Tensor([[0 0 0 0]
[0 0 0 0]], shape=(2, 4), dtype=int32)
2.1.3 Tensor和Array转换
#tf->array
array_a1 = np.array(a1)
array_a1 = a1.numpy()
# array->tf
tensor_a1 = tf.convert_to_tensor(array_a1)
2.1.4 数学运算
tf.add(a,b) # 加法 尝试了a数组,b张量,也可以计算
tf.multiply(a,b) # 逐元素乘法
tf.matmul(a,b) # 矩阵乘法
2.1.5 类型转换
tensorflow支持的模型有:tf.float16、tf.float64、tf.int8、tf.int16、tf.int32…
b = tf.Variable([[2,3,4,5],[6,7,8,9]], dtype=tf.float64)
a = tf.cast(b, dtype = tf.int32)
2.2 计算图
TensorFlow有三种计算图的构建方式:静态计算图、动态计算图以及Autograph。
TensorFlow1.0,用的是静态计算图。先使用TensorFlow的各种算子创建计算图,然后再开启一个会话Session,显式执行计算图。
TensorFlow2.0,用的是动态计算图。每使用一个算子后,该算子会被动态加入到隐含的默认计算图中立即执行得到结果,而无需开启Session。程序方便调试,但是运行效率相对低一些。 如果TensorFlow2.0要使用静态图,可以使用@tf.function装饰器,将普通python函数转换成对应TensorFlow计算图构建代码。但是需要注意
- 被
@tf.function修饰的函数应尽可能使用TensorFlow中的函数而不是Python中的其他函数。例如使用tf.print而不是print,使用tf.range而不是range,使用tf.constant(True)而不是True. - 避免在
@tf.function修饰的函数内部定义tf.Variable - 被
@tf.function修饰的函数不可修改该函数外部的列表或字典等数据结构变量
计算图由**节点(nodes)和线(edges)**组成。节点表示操作符Operator,或者称之为算子,线便是计算之间的以来:数据传递、控制依赖(即先后顺序)

@tf.function
def strjoin(x,y):
z = tf.strings.join([x, y], separator = " ")
tf.print(z)
return z
result = strjoin(tf.constant("hello"), tf.constant("world"))
print(result)
静态图、动态图性能差异测试
import timeit
x = tf.random.uniform(shape=[10, 10], minval=-1, maxval=2, dtype=tf.dtypes.int32)
def power(x, y):
result = tf.eye(10, dtype=tf.dtypes.int32)
for _ in range(y):
result = tf.matmul(x, result)
return result
print("Eager execution:", timeit.timeit(lambda: power(x, 100), number=1000))
# 将python函数转换为图形
power_as_graph = tf.function(power)
print("Graph execution:", timeit.timeit(lambda: power_as_graph(x, 100), number=1000))
# Eager execution: 5.905397668480873
# Graph execution: 1.1285493150353432
也可以使用@tf.function调用tf.function。还可以使用tf.config.run_functions_eagerly(True)关闭Function创建和运行图形能力。
在构建计算Autograph应避免在@tf.function内部定义tf.Variable。但是如果在函数外部定义的话,这个函数对外部又有变量依赖,可以用类的方式,将tf.Variable在类的初始化使用。
class DemoModule(tf.Module):
def __init__(self, init_value=tf.constant(0.0), name=None):
super(DemoModule, self).__init__(name=name)
with self.name_scope: # 相当于with tf.name_scope("demo_module")
self.x = tf.Variable(init_value, dtype=tf.float32, trainable=True)
@tf.function
def addprint(self, a):
with self.name_scope:
self.x.assign_add(a)
tf.print(self.x)
return self.x
a = DemoModule(init_value = 10)
a.addprint(10)
2.3 自动微分
自动微分主要用神经网络训练的反向传播。TensorFlow 会记住在前向传递过程中哪些运算以何种顺序发生。随后,在后向传递期间,以相反的顺序遍历此运算列表来计算梯度。
TensorFlow一般使用tf.GradientTape来记录正向计算过程,然后反向计算自动计算梯度值。
2.3.1 一阶导数求法
# 全部都要打小数点
x = tf.Variable(0.0, name = 'x', dtype = tf.float32)
a = tf.constant(1.0)
b = tf.constant(-2.0)
c = tf.constant(1.0)
with tf.GradientTape() as tape:
y = a * tf.pow(x, 2) + b * x + c
dy_dx = tape.gradient(y, x)
print(dy_dx)
# tf.Tensor(-2.0, shape=(), dtype=float32)
对常量张量求导,加watch
with tf.GradientTape() as tape:
tape.watch([a,b,c])
y = a * tf.pow(x, 2) + b * x + c
dy_dx, dy_da, dy_db, dy_dc = tape.gradient(y, [x, a, b, c])
print(dy_da)
2.3.2 二阶导数求法
# 全部都要打小数点
x = tf.Variable(0.0, name = 'x', dtype = tf.float32)
a = tf.constant(1.0)
b = tf.constant(-2.0)
c = tf.constant(1.0)
with tf.GradientTape() as tape2:
with tf.GradientTape() as tape:
y = a * tf.pow(x, 2) + b * x + c
dy_dx = tape.gradient(y, x)
dy2_dx2 = tape2.gradient(dy_dx, x)
print(dy_dx)
print(dy2_dx2)
# tf.Tensor(-2.0, shape=(), dtype=float32)
# tf.Tensor(2.0, shape=(), dtype=float32)
2.3.3 利用梯度和优化器求最小值
# 全部都要打小数点
x = tf.Variable(0.0, name = 'x', dtype = tf.float32)
a = tf.constant(1.0)
b = tf.constant(-2.0)
c = tf.constant(1.0)
optimizer = tf.keras.optimizers.SGD(learning_rate = 0.01)
for _ in range(1000):
with tf.GradientTape() as tape:
y = a * tf.pow(x, 2) + b * x + c
dy_dx = tape.gradient(y, x)
optimizer.apply_gradients(grads_and_vars=[(dy_dx,x)])
tf.print("y = ", y, "x = ", x)
# y = 0 x = 0.99999851
不想被梯度计算,可以设置
with tf.GradientTape(watch_accessed_variables=False) as tape:
pass
三、TensorFlow实现神经网络模型的一般流程
- 准备数据
- 定义模型
- 训练模型
- 评估模型
- 推理模型
- 保存模型
四、数据输入
4.1 支持格式
支持Numpy数组、Pandas,Python生成器、csv文件、文本文件、文件路径、TFrecords文件等方式构建数据管道。
如果数据很小并且适合内存,建议使用tf.data.Dataset.from_tensor_slices()从Numpy array构建数据管道。
- Dataset: 有大型数据集并且需要进行分布式训练
- Sequence: 有大型数据集并且需要执行大量在 TensorFlow 中无法完成的自定义 Python 端处理(例如,如果您依赖外部库进行数据加载或预处理)
- 通过tfrecords文件方式构建数据管道较为复杂,需要对样本构建tf.Example后压缩成字符串写到tfrecoreds文件,读取后再解析成tf.Example。但tfrecoreds文件的优点是压缩后文件较小,便于网络传播,加载速度较快。
4.2 数据集构建
4.2.1 Numpy构建数据
官方推荐使用 tf.data.Dataset.from_tensors() 或 tf.data.Dataset.from_tensor_slices() 创建数据集,Dataset支持一类特殊的操作Trainformation(打乱、生成epoch…等操作)
data.map(function):将转换函数映射到数据集每一个元素
data.batch(batch_size):构建batch
data.shuffle(buffer_size):随机打乱输入数据,从该缓冲区中随机采样元素
data.repeat():repeat的功能就是将整个序列重复多次,一般不带参数
data.prefetch(tf.data.experimental.AUTOTUNE) :预先取 数据
data.take():采样,从开始位置取前几个元素
## 举例
features = np.arange(0, 100, dtype=np.int32) # # (100,)
labels = np.zeros(100, dtype=np.int32) # (100,)
data = tf.data.Dataset.from_tensor_slices((features, labels)) # 创建数据集
data = data.repeat() # 无限期地补充数据
data = data.shuffle(buffer_size=100) # 打乱数据
data = data.batch(batch_size=4) # 批量数据
data = data.prefetch(buffer_size=1) # 预取批处理(预加载批处理,消耗更快)
for batch_x, batch_y in data.take(5):
print(batch_x.shape, batch_y.shape) # (4,) (4,)
break
如果多次调用,可以使用迭代器的方式
ite_data = iter(data)
for i in range(5):
batch_x, batch_y = next(ite_data)
print(batch_x, batch_y)
4.2.2 提升管道性能的方法
- 使用 prefetch 方法让数据准备和参数迭代两个过程相互并行。
- 使用 interleave 方法可以让数据读取过程多进程执行,并将不同来源数据夹在一起。
- 使用 map 时设置num_parallel_calls 让数据转换过程多进行执行。
- 使用 cache 方法让数据在第一个epoch后缓存到内存中,仅限于数据集不大情形。
- 使用 map转换时,先batch,然后采用向量化的转换方法对每个batch进行转换。
4.3 生成器构建数据
4.3.1 代码生成
def generate_features():
# 函数生成一个随机字符串
def random_string(length):
return ''.join(random.choice(string.ascii_letters) for m in range(length))
# 返回一个随机字符串、一个随机向量和一个随机整数
yield random_string(4), np.random.uniform(size=4), random.randint(0, 10)
data = tf.data.Dataset.from_generator(generate_features, output_types=(tf.string, tf.float32, tf.int32))
data = data.repeat() # 无限期地补充数据
data = data.shuffle(buffer_size=100) # 打乱数据
data = data.batch(batch_size=4) # 批量数据(将记录聚合在一起)
data = data.prefetch(buffer_size=1) # 预取批量(预加载批量以便更快的消耗)
# Display data.
for batch_str, batch_vector, batch_int in data.take(5):
# (4,) (4, 4) (4,)
print(batch_str.shape, batch_vector.shape, batch_int.shape)
4.3.2 keras.utils.Sequence
keras.utils.Sequence该类提供了一个简单的接口来构建 Python 数据生成器,该生成器可以感知多处理并且可以洗牌。(pytorch也有类似的类)
Sequence必须实现两种方法:
getitem:返回一个batch数据
len:整型,返回batch的数量
import tensorflow as tf
from keras.utils.data_utils import Sequence
class SequenceDataset(Sequence):
def __init__(self, batch_size):
self.input_data = tf.random.normal((640, 8192, 1))
self.label_data = tf.random.normal((640, 8192, 1))
self.batch_size = batch_size
def __len__(self):
return int(tf.math.ceil(len(self.input_data) / float(self.batch_size)))
# 每次输出一个batch
def __getitem__(self, idx):
batch_x = self.input_data[idx * self.batch_size:(idx + 1) * self.batch_size]
batch_y = self.label_data[idx * self.batch_size:(idx + 1) * self.batch_size]
return batch_x, batch_y
sequence = SequenceDataset(batch_size=64)
for batch_idx, (x, y) in enumerate(sequence):
print(batch_idx, x.shape, y.shape) # tf.float32
# 0 (64, 8192, 1) (64, 8192, 1)
break
五、搭建模型
深度学习模型一般由各种模型层组合而成,如果这些内置模型层不能够满足需求,可以通过编写tf.keras.Lambda匿名模型层或继承tf.keras.layers.Layer基类构建自定义的模型层。其中tf.keras.Lambda匿名模型层只适用于构造没有学习参数的模型层。
搭建模型有以下3种方式构建模型:
- Sequential顺序模型:用于简单的层堆栈, 其中每一层恰好有一个输入张量和一个输出张量
- 函数式API模型:多输入多输出,或者模型需要共享权重,或者模型具有残差连接等非顺序结构
- 继承Model基类自定义模型:如果无特定必要,尽可能避免使用Model子类化的方式构建模型,这种方式提供了极大的灵活性,但也有更大的概率出错
5.1 顺序建模keras.Sequential
# 有点类似list方式
model = keras.Sequential([
layers.Dense(2, activation="relu", name="layer1"),
layers.Dense(3, activation="relu", name="layer2"),
layers.Dense(4, name="layer3"),
])
# add方式
model = keras.Sequential()
model.add(layers.Dense(2, activation="relu"))
model.add(layers.Dense(3, activation="relu"))
model.add(layers.Dense(4))
# 引入keras不成功的,可以用tensorflow.keras代替
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(tf.keras.layers.Dense(2, activation="relu", input_shape=(4,)))
tf.print(model.summary())
model.add(tf.keras.layers.Dense(3, activation="relu"))
tf.print(model.summary())
model.add(tf.keras.layers.Dense(4))
tf.print(model.summary())
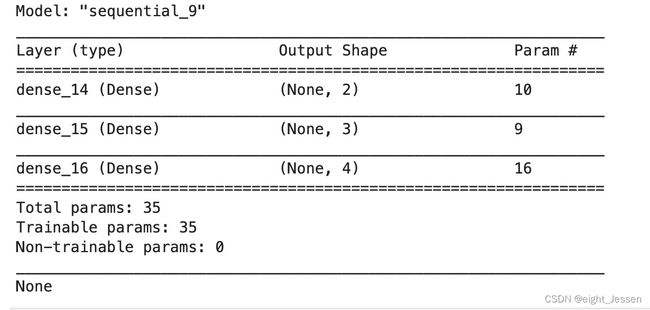
这个时候模型不知道输入shape,所以最开始模型没有权重,需要告知模型输入shape
# 在第一层添加Input
model.add(keras.Input(shape=(4,)))
model.add(layers.Dense(2, activation="relu"))
# 或者在第一层添加input_shape
model.add(layers.Dense(2, activation="relu", input_shape=(4,)))
5.2 函数式API建模
函数式API搭建模型比Sequential更加灵活,可以处理具有非线性拓扑、共享层甚至多个输入或输出的模型。
from tensorflow.keras.models import Sequential
import tensorflow.keras.layers as layers
import tensorflow.keras as keras
inputs = keras.Input(shape=(784,))
x = layers.Dense(64, activation = 'relu')(inputs)
x = layers.Dense(64, activation = 'relu')(x)
outputs = layers.Dense(10)(x)
model = keras.Model(inputs = inputs, outputs = outputs, name = "mnist_mode")
model.summary()

将模型绘制成图
keras.utils.plot_model(model, "my_first_model_with_shape_info.png", show_shapes=True)
函数式模型可以嵌套
5.3 自定义建模
TensorFlow中,模型类的继承关系为:
tf.keras.Model(模型) → \to → tf.keras.layers.Layer(层) → \to → tf.Module(模块)。
通常使用Layer类来定义内部计算块,使用Model类来定义外部模型(训练的对象)
tf.Module例子,主要用于创建模块:
class CustomDense(tf.Module):
def __init__(self, in_features, out_features, **kwargs):
super().__init__(**kwargs)
self.weight = tf.Variable(tf.random.normal([in_features, out_features]), name = 'weight')
self.bias = tf.Variable(tf.random.normal([out_features]), name = 'bias')
def __call__(self, x):
x = tf.matmul(x, self.weight) + self.bias
x = tf.nn.relu(x)
return x
model = CustomDense(in_features = 5, out_features = 10)
x = tf.random.normal(shape=(32, 5))
outputs = model(x)
print(outputs.shape)
继承tf.keras.layers.Layer例子,主要用于创建层:
# 使用CustomDense 搭建一个模型
class CustomLayer(tf.keras.layers.Layer):
# 添加 **kwargs来支持基本Keras层参数
def __init__(self, in_features, out_features, **kwargs):
super().__init__(**kwargs)
# 这将很快转移到 build ;见下代码
self.weight = tf.Variable(tf.random.normal([in_features, out_features]), name='weight')
self.bias = tf.Variable(tf.zeros([out_features]), name='bias')
# Keras 层有自己的 __call__,他然后调用 call()
def call(self, x):
x = tf.matmul(x, self.weight) + self.bias
x = tf.nn.relu(x)
return x
model = CustomLayer(in_features=5, out_features=10)
x = tf.random.normal(shape=(64, 5))
outputs = model(x)
print("CustomLayer outputs", outputs.shape) # (64, 10)
使用build的例子
class FlexibleDense(tf.keras.layers.Layer):
# 添加 **kwargs来支持基本Keras层参数
def __init__(self, out_features, **kwargs):
super().__init__(**kwargs)
self.out_features = out_features
# 创建层的状态(权重)
# 在call前会先调用 build,使得权重的形状固定下来,这样我们就不用操心输入的shape
def build(self, input_shape):
self.weight = tf.Variable(tf.random.normal([input_shape[-1], self.out_features]), name='weight')
self.bias = tf.Variable(tf.zeros([self.out_features]), name='bias')
def call(self, inputs):
return tf.matmul(inputs, self.weight) + self.bias
model = FlexibleDense(out_features=10)
x = tf.random.normal(shape=(64, 5))
outputs = model(x)
print("FlexibleDense outputs", outputs.shape) # (64, 10)
继承tf.keras.Model的例子,主要用于创建模型
class CustomModel(tf.keras.Model):
def __init__(self, in_features=5, out_features=10, **kwargs):
super().__init__(**kwargs)
self.dense_1 = CustomLayer(in_features, out_features)
self.dense_2 = CustomLayer(out_features, out_features)
def call(self, x):
x = self.dense_1(x)
x = self.dense_2(x)
return x
model = CustomLayer(in_features=5, out_features=10)
x = tf.random.normal(shape=(64, 5))
outputs = model(x)
print("CustomModel outputs", outputs.shape) # (64, 10)
keras层有很多额外的功能:
- 可选损失函数
- 对度量函数的支持
- 对可选training参数的内置支撑,用于区分训练和推断用途
get_config和from_config,允许准确配置,用于python中克隆莫模型。
keras.Model类和keras.Layer类具有相同的API,但是有以下的区别:
- Model类提供了内置的训练,
model.fit(),model.evaluate(),model.predict()API - Model类 可以通过
model.layers属性公开内层的列表。 - Model类 提供了保存和序列化 API
save()、save_weights()…
下面是VAE例子,首先是模型构建,然后模型训练
VAE模型构建
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
class Sampling(layers.Layer):
"""Uses (z_mean, z_log_var) to sample z, the vector encoding a digit."""
def call(self, inputs):
z_mean, z_log_var = inputs
batch = tf.shape(z_mean)[0]
dim = tf.shape(z_mean)[1]
epsilon = tf.keras.backend.random_normal(shape=(batch, dim))
return z_mean + tf.exp(0.5 * z_log_var) * epsilon
class Encoder(layers.Layer):
"""Maps MNIST digits to a triplet (z_mean, z_log_var, z)."""
def __init__(self, latent_dim=32, intermediate_dim=64, name="encoder", **kwargs):
super(Encoder, self).__init__(name=name, **kwargs)
self.dense_proj = layers.Dense(intermediate_dim, activation="relu")
self.dense_mean = layers.Dense(latent_dim)
self.dense_log_var = layers.Dense(latent_dim)
self.sampling = Sampling()
def call(self, inputs):
x = self.dense_proj(inputs)
z_mean = self.dense_mean(x)
z_log_var = self.dense_log_var(x)
z = self.sampling((z_mean, z_log_var))
return z_mean, z_log_var, z
class Decoder(layers.Layer):
"""Converts z, the encoded digit vector, back into a readable digit."""
def __init__(self, original_dim, intermediate_dim=64, name="decoder", **kwargs):
super(Decoder, self).__init__(name=name, **kwargs)
self.dense_proj = layers.Dense(intermediate_dim, activation="relu")
self.dense_output = layers.Dense(original_dim, activation="sigmoid")
def call(self, inputs):
x = self.dense_proj(inputs)
return self.dense_output(x)
class VariationalAutoEncoder(keras.Model):
"""Combines the encoder and decoder into an end-to-end model for training."""
def __init__(self, original_dim, intermediate_dim=64, latent_dim=32, name="autoencoder", **kwargs):
super(VariationalAutoEncoder, self).__init__(name=name, **kwargs)
self.original_dim = original_dim
self.encoder = Encoder(latent_dim=latent_dim, intermediate_dim=intermediate_dim)
self.decoder = Decoder(original_dim, intermediate_dim=intermediate_dim)
def call(self, inputs):
z_mean, z_log_var, z = self.encoder(inputs)
reconstructed = self.decoder(z)
# Add KL divergence regularization loss.
kl_loss = -0.5 * tf.reduce_mean(
z_log_var - tf.square(z_mean) - tf.exp(z_log_var) + 1
)
self.add_loss(kl_loss) # 添加损失
return reconstructed
模型训练,可以自己写训练过程,也可以使用内置的方法fit()
original_dim = 784
vae = VariationalAutoEncoder(original_dim, 64, 32)
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-3)
mse_loss_fn = tf.keras.losses.MeanSquaredError()
loss_metric = tf.keras.metrics.Mean()
(x_train, _), _ = tf.keras.datasets.mnist.load_data()
x_train = x_train.reshape(60000, 784).astype("float32") / 255
train_dataset = tf.data.Dataset.from_tensor_slices(x_train)
train_dataset = train_dataset.shuffle(buffer_size=1024).batch(64)
epochs = 2
# Iterate over epochs.
for epoch in range(epochs):
print("Start of epoch %d" % (epoch,))
# Iterate over the batches of the dataset.
for step, x_batch_train in enumerate(train_dataset):
with tf.GradientTape() as tape:
reconstructed = vae(x_batch_train)
# Compute reconstruction loss
loss = mse_loss_fn(x_batch_train, reconstructed)
loss += sum(vae.losses) # Add KLD regularization loss
grads = tape.gradient(loss, vae.trainable_weights)
optimizer.apply_gradients(zip(grads, vae.trainable_weights))
loss_metric(loss)
if step % 100 == 0:
print("step %d: mean loss = %.4f" % (step, loss_metric.result()))
## fit方法
vae = VariationalAutoEncoder(784, 64, 32)
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-3)
vae.compile(optimizer, loss=tf.keras.losses.MeanSquaredError())
vae.fit(x_train, x_train, epochs=2, batch_size=64)
自定义的kears.Model还可以和函数式API混搭训练(个人不建议,代码不优雅)
PS:自定义层
如果自定义模型层没有需要被训练的参数,一般推荐使用Lamda层实现。
mypower = layers.Lambda(lambda x:tf.math.pow(x,2))
mypower(tf.range(5))
如果自定义模型层有需要被训练的参数,则可以通过继承Layer基类实现。Layer的子类化一般需要重新实现初始化方法,Build方法和Call方法。
如果built = False,调用__call__时会先调用build方法初始化变量,并将built变量设为True 再调用call方法。这样在第二次调用__call__时将不再有变量被初始化。
另外一个需要注意的地方在于:self.built = True
built保证build() 方法只被调用一次
六 损失函数
一般来说,损失值 由 损失函数 和 正则化项 组成(Objective = Loss + Regularization)
对于keras模型,正则化项一般在各层中指定,例如使用Dense的 kernel_regularizer 和 bias_regularizer 等参数指定权重使用 L1 或者 L2 正则化项,此外还可以用kernel_constraint 和 bias_constraint 等参数约束权重的取值范围,这也是一种正则化手段。
损失函数在 model.compile 时候指定。
- 对于回归模型,通常使用的损失函数是平方损失函数 mean_squared_error,简写为 mse,类实现形式为 MeanSquaredError 和 MSE
- 对于二分类模型,通常使用的是二元交叉熵损失函数 binary_crossentropy。
- 对于多分类模型,如果label是one-hot编码的,则使用交叉熵损失函数 categorical_crossentropy。如果label是序号编码的,则需要使用稀疏类别交叉熵损失函数 sparse_categorical_crossentropy。
- 以自定义损失函数,自定义损失函数需要接收两个张量y_true,y_pred作为输入参数,并输出一个标量作为损失函数值。
6.1 自定义损失函数
6.1.1 函数实现:输入预测值和真实值,返回损失值
def custom_mean_squared_error(y_true, y_pred):
return tf.math.reduce_mean(tf.square(y_true - y_pred))
model.compile(optimizer=..., loss=custom_mean_squared_error)
6.1.2 类实现:继承tf.keras.losses.Loss
在init中初始化参数,在call中重写计算逻辑
class CustomMSE(keras.losses.Loss):
def __init__(self, regularization_factor=0.1, name="custom_mse"):
super().__init__(name=name)
self.regularization_factor = regularization_factor
def call(self, y_true, y_pred):
mse = tf.math.reduce_mean(tf.square(y_true - y_pred))
reg = tf.math.reduce_mean(tf.square(0.5 - y_pred))
return mse + reg * self.regularization_factor
model.compile(optimizer=..., loss=CustomMSE())
七、度量函数、评估函数
通常会通过度量函数来从另一个方面评估模型的好坏,可以在 model.compile 时,通过列表形式指定单/多个评估指标。
- 可以自定义评估指标。自定义评估指标需要接收两个张量y_true,y_pred作为输入参数,并输出一个标量作为评估值。
- 可以继承 tf.keras.metrics.Metric 自定义度量方法,update_state方法,result方法实现评估指标的计算逻辑,从而得到评估指标的类的实现
7.1 自定义度量
继承 tf.keras.metrics.Metric,并且实现4个类方法:
- init(self):创建状态变量
- update_state(self, y_true, y_pred, sample_weight=None):根据 y_true 和 y_pred 来更新状态变量
- result(self):使用状态变量来计算 最终结果
- reset_state(self):重新初始化状态变量
class SnrCustomMetrics(metrics.Metric):
def __init__(self, name="snr_metrics", **kwargs):
# 创建状态变量
super(SnrCustomMetrics, self).__init__(name=name, **kwargs)
self.metrics_value = self.add_weight(name="snr_value", initializer="zeros")
def update_state(self, y_true, y_pred, sample_weight=None):
"""使用目标 y_true 和模型预测 y_pred 来更新状态变量
:param y_true: target
:param y_pred: 预测值
:param sample_weight: 权重
"""
labels_pow = tf.pow(y_true, 2)
noise_pow = tf.pow(y_pred - y_true, 2)
snr_value = 10 * tf.math.log(tf.reduce_sum(labels_pow) / tf.reduce_sum(noise_pow)) / tf.math.log(10.)
if sample_weight is not None:
sample_weight = tf.cast(sample_weight, "float32")
snr_value = tf.multiply(snr_value, sample_weight)
self.metrics_value.assign_add(snr_value)
# 使用状态变量来计算最终结果
def result(self):
return self.metrics_value
# metrics 的状态将在每个epoch开始时重置。
def reset_state(self):
self.metrics_value.assign(0.0)
model.compile(optimizer=..., loss=..., metrics=[SnrCustomMetrics()])
八、优化器
深度学习优化算法大概经历了 SGD -> SGDM -> NAG ->Adagrad -> Adadelta(RMSprop) -> Adam -> Nadam 这样的发展历程。
model.compile(optimizer=optimizers.SGD(learning_rate=0.01), loss=loss)
- SGD 默认参数为纯SGD, 设置momentum参数不为0实际上变成SGDM, 考虑了一阶动量, 设置 nesterov为True后变成NAG,即 Nesterov Acceleration Gradient,在计算梯度时计算的是向前走一步所在位置的梯度
- Adagrad:考虑了二阶动量,对于不同的参数有不同的学习率,即自适应学习率。缺点是学习率单调下降,可能后期学习速率过慢乃至提前停止学习
- Adagrad:考虑了二阶动量,对于不同的参数有不同的学习率,即自适应学习率。缺点是学习率单调下降,可能后期学习速率过慢乃至提前停止学习
- Adadelta:考虑了二阶动量,与RMSprop类似,但是更加复杂一些,自适应性更强
- Adam:同时考虑了一阶动量和二阶动量,可以看成RMSprop上进一步考虑了Momentum
- Nadam:在Adam基础上进一步考虑了 Nesterov Acceleration
优化器主要使用方法有
- apply_gradients方法传入变量和对应梯度从而来对给定变量进行迭代
- 直接使用minimize方法对目标函数进行迭代优化
- 在编译时将优化器传入model.fit
# 第一种
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01)
with tf.GradientTape() as tape:
...
grads = tape.gradient(loss, model.trainable_weights) # 根据损失 求梯度
optimizer.apply_gradients(zip(grads, model.trainable_weights)) # 根据梯度 优化模型
# 第二种
@tf.function
def train(epoch=1000):
for _ in tf.range(epoch):
optimizer.minimize(loss, model.trainable_weights)
tf.print("epoch = ", optimizer.iterations)
return loss
# 第三种
model.compile(optimizer=optimizers.SGD(learning_rate=0.01), loss=loss)
九 回调函数
tf.keras的回调函数实际上是一个类,一般是在model.fit时作为参数指定,一般收集一些日志信息,改变学习率等超参数,提前终止训练过程等等
大部分时候,keras.callbacks子模块中定义的回调函数类已经足够使用了,如果有特定的需要,我们也可以通过对keras.callbacks.Callbacks实施子类化构造自定义的回调函数
- BaseLogger: 收集每个epoch上metrics平均值,对stateful_metrics参数中的带中间状态的指标直接拿最终值无需对各个batch平均,指标均值结果将添加到logs变量中。该回调函数被所有模型默认添加,且是第一个被添加的
- History: 将BaseLogger计算的各个epoch的metrics结果记录到history这个dict变量中,并作为model.fit的返回值。该回调函数被所有模型默认添加,在BaseLogger之后被添加
- EarlyStopping: 当被监控指标在设定的若干个epoch后没有提升,则提前终止训练
- TensorBoard: 为Tensorboard可视化保存日志信息。支持评估指标,计算图,模型参数等的可视化
- ModelCheckpoint: 在每个epoch后保存模型
- ReduceLROnPlateau:如果监控指标在设定的若干个epoch后没有提升,则以一定的因子减少学习率
- TerminateOnNaN:如果遇到loss为NaN,提前终止训练
- LearningRateScheduler:学习率控制器。给定学习率lr和epoch的函数关系,根据该函数关系在每个epoch前调整学习率
- CSVLogger:将每个epoch后的logs结果记录到CSV文件中
- ProgbarLogger:将每个epoch后的logs结果打印到标准输出流中
十、模型训练
一般有三种方法
- 内置fit方法,支持对numpy array,tf.data.Dataset以及 Python generator数据进行训练,并且可以通过设置回调函数实现对训练过程的复杂控制逻辑。
- 内置train_on_batch方法
- 自定义训练循环
10.1 model.fit
model.fit(
x=None, y=None, # 输入和输出
batch_size=None, # 默认32
epochs=1, # 训练epoch
verbose='auto', #日志打印
callbacks=None, # 训练期间调用的回调列表。见tf.keras.callbacks
validation_split=0.0, # 划分验证集,[0,1]
validation_data=None, # 验证集数据
shuffle=True,
initial_epoch=0, # 整数,开始训练的epoch,可以用于重训
steps_per_epoch=None)
# 返回:history,调用 history.history 可以查看训练期间损失值和度量值的记录
10.2 train_on_batch
相比较fit方法更加灵活,可以不通过回调函数而直接在batch层次上更加精细地控制训练的过程。
for epoch in tf.range(1, epoches + 1):
for x, y in ds_train:
train_result = model.train_on_batch(x, y)
for x, y in ds_valid:
valid_result = model.test_on_batch(x, y, reset_metrics=False)
10.3 自定义训练循环
自定义训练循环无需编译模型,直接利用优化器根据损失函数反向传播迭代参数,拥有最高的灵活性。
训练循环包括按顺序重复执行四个任务:
- 给模型输入batch数据以生成输出
- 通过将输出与标签进行比较来计算损失
- 使用GradientTape计算梯度
- 使用这些梯度优化变量
optimizer = keras.optimizers.SGD(learning_rate=1e-3) # 实例化一个优化器
loss_fn = keras.losses.BinaryCrossentropy() # 实例化损失函数
train_loss = keras.metrics.Mean(name='train_loss')
valid_loss = keras.metrics.Mean(name='valid_loss')
train_metric = keras.metrics.BinaryAccuracy(name='train_accuracy')
valid_metric = keras.metrics.BinaryAccuracy(name='valid_accuracy')
@tf.function
def train_step(features, labels):
with tf.GradientTape() as tape:
logits = model(features, training=True)
loss_value = loss_fn(labels, logits)
# loss_value += sum(model.losses) # 添加额外的损失
grads = tape.gradient(loss_value, model.trainable_weights)
optimizer.apply_gradients(zip(grads, model.trainable_weights))
train_loss.update_state(loss_value)
train_metric.update_state(labels, logits)
@tf.function
def valid_step(features, labels):
val_logits = model(features, training=False)
loss_value = loss_fn(labels, val_logits)
valid_loss.update_state(loss_value)
valid_metric.update_state(labels, val_logits)
epochs = 2
for epoch in range(epochs):
start_time = time.time()
for step, (x_batch_train, y_batch_train) in enumerate(train_dataset):
loss_value = train_step(x_batch_train, y_batch_train)
# 在每个epoch结束时运行验证循环
for x_batch_val, y_batch_val in val_dataset:
valid_step(x_batch_val, y_batch_val)
if epoch % 5 == 0:
print('Epoch={},Loss:{},Accuracy:{},Valid Loss:{},Valid Accuracy:{}'.format(epoch, train_loss.result(),
train_metric.result(),
valid_loss.result(),
valid_metric.result()))
train_loss.reset_states()
valid_loss.reset_states()
train_metric.reset_states()
valid_metric.reset_states()
print("运行时间: %.2fs" % (time.time() - start_time))
十一、模型评估
通过自定义训练循环训练的模型没有经过编译,无法直接使用model.evaluate(ds_valid)方法
model.evaluate(x = x_test,y = y_test)
十二、模型推理
model.predict(ds_test)model(x_test)model.call(x_test)model.predict_on_batch(x_test)
推荐优先使用model.predict(ds_test)方法,既可以对Dataset,也可以对Tensor使用。
十三、保存和加载模型
Keras模型由多个组件组成:
- 模型架构,指定模型包含的层及其连接方式
- 权重值
- 优化器及其状态(如果有)(这使您可以在离开的地方重新开始训练)
- 模型的编译信息(损失和度量,通过编译模型或通过调用 add_loss() 或 add_metric() 来定义)
可以通过 Keras API 将这些片段一次性保存到磁盘,或仅选择性地保存其中某一部分:
- 将所有内容以 TensorFlow SavedModel 格式(或较早的 Keras H5 格式)保存
- 仅保存架构/配置,通常保存为 JSON 文件
- 仅保存权重值。通常在训练模型时使用
13.1 保存和加载整个模型
- 低级API
tf.saved_model
保存模型
tf.saved_model.save(model, path_to_dir)
加载模型model = tf.saved_model.load(path_to_dir)
- 高级API
tf.keras.Model(如果模型不包含自定义子类 keras 模型,则非常推荐)
保存模型
model.save(SaveModel_path),
tf.keras.models.save_model(model, SaveModel_path)
加载模型model = tf.keras.models.load_model(SaveModel_path)
SaveModel_path = 'path/to/location'
model.save(SaveModel_path)
# 或者
tf.keras.models.save_model(model, SaveModel_path)
# 加载模型
model = tf.keras.models.load_model(SaveModel_path)
SavedModel 格式会存储类名称、调用函数、损失和权重(如果已实现,还包括配置)。调用函数会定义模型/层的计算图。
如果将 save_format=‘h5’ 传递给 save(),则模型将以H5的格式保存。
Keras H5 格式(较旧的):包含模型架构、权重值和compile()信息。它是SavedModel的轻量级替代品。
通过model.add_loss()和model.add_metric()添加的外部损失和度量 不会被保存。
自定义对象(如自定义层)的计算图不包含在保存的h5文件中。在加载时,Keras需要访问这些对象的Python类/函数来重构模型。
13.2 保存模型架构
模型的配置(或架构)指定模型包含的层,以及这些层的连接方式。如果有模型的配置,则可以使用权重的新初始化状态创建模型,而无需编译信息。
- 请注意,这仅适用于使用函数式或序列式 API 定义的模型,不适用于子类化模型。
13.2.1 get_config()和from_config()
config = model.get_config()返回一个包含模型配置的 Python 字典。
Sequential.from_config(config) (针对 Sequential 模型)或 Model.from_config(config) (针对函数式 API 模型)重建同一模型。
# -----------------层示例
layer = keras.layers.Dense(3, activation="relu")
layer_config = layer.get_config()
new_layer = keras.layers.Dense.from_config(layer_config)
# -----------------序列模型示例
model = keras.Sequential([keras.Input((32,)), keras.layers.Dense(1)])
config = model.get_config()
new_model = keras.Sequential.from_config(config)
# -----------------函数式模式示例
inputs = keras.Input((32,))
outputs = keras.layers.Dense(1)(inputs)
model = keras.Model(inputs, outputs)
config = model.get_config()
new_model = keras.Model.from_config(config)
13.2.2 to_json() 和 tf.keras.models.model_from_json()
这与 get_config / from_config 类似,不同之处在于它会将模型转换成 JSON 字符串,之后该字符串可以在没有原始模型类的情况下进行加载。它还特定于Model,不适用于Layer。
json_str = model.to_json() # 保存模型结构
model_json = tf.keras.models.model_from_json(json_str) # 恢复模型结构
本博文学习资料来源 https://www.cnblogs.com/LXP-Never/p/15917498.html#blogTitle1