Pytorch系列之——模型保存与加载、finetune
模型保存与加载
- 序列化与反序列化
- 模型保存与加载的两种方式
- 模型断点续训练
按理来说我们训练好一个模型是为了以后可以更方便的去使用它,当我们训练模型是模型是被存储在内存当中的,而内存中数据一般不具有这种长久性的存储的功能,但硬盘可以长期的存储数据,所以在我们训练好模型之后,我们需要将模型从内存中转移到硬盘上进行长期存储。这就是模型的保存与加载,也可以称之为序列化与反序列化,下面介绍为什么模型的保存与加载可以被称为序列化与反序列化呢?
序列化与反序列化主要描述的是内存与硬盘之间的一个转换关系,训练好的模型在内存中是以对象的形式存储的,如果在硬盘中则是以二进制序列的形式进行存储的。
那么序列化就是指将以对象形式存储在内存中的模型再以二进制的形式存储在硬盘中,在pytoch实现中就是将模型对象转换成二进制数据再存储在硬盘中。很显然,反序列化相对应的就是指将存储在硬盘中的二进制序列化数据再重新以模型对象的形式存储至内存中,这二者是相互对应的两个操作:
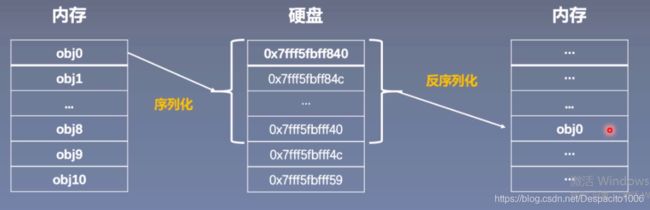
Pytorch中的序列化与反序列化
-
torch.save
主要参数: -
obj:对象
-
f:输出路径
-
torch.load
主要参数: -
f:文件路径
-
map_location:指定存放位置,cpu or gpu
法一:保存整个Module
torch.save(net,path)
法二:保存模型参数
state_dict=net.state_dict()
torch.save(state_dict,path)
 首先需要对模型进行保存,这里以LeNet2为例说明,分别对整个模型进行保存,以及仅对模型参数进行保存:
首先需要对模型进行保存,这里以LeNet2为例说明,分别对整个模型进行保存,以及仅对模型参数进行保存:
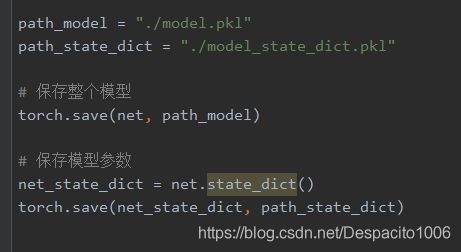 可以看到,程序第一、二行分别是设置保存整个模型和保存模型参数的路径,之后使用torch.save对整个模型进行保存,以及调用state_dict()方法获取模型参数并对其进行保存。
可以看到,程序第一、二行分别是设置保存整个模型和保存模型参数的路径,之后使用torch.save对整个模型进行保存,以及调用state_dict()方法获取模型参数并对其进行保存。
之后是torch.load(),对模型或模型参数进行加载:
 这里是设置之前保存的模型的文件路径,并调用load()方法对保存的整个模型进行加载;
这里是设置之前保存的模型的文件路径,并调用load()方法对保存的整个模型进行加载;
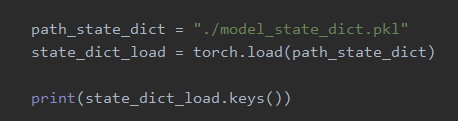
这里是设置之前保存的模型参数的文件路径,并调用load()方法对保存的模型参数进行加载,注意这里我们获取的是模型参数字典的键值(比如’features.0.weight’,‘features.0.bias’…等);
 从上面的代码可以看到我们在加载保存的模型参数时,需要事先创建一个和保存模型(参数)时结构一样的模型(LeNet2),之后采用load_state_dict()方法将保存的模型参数存储在新创建的模型中。
从上面的代码可以看到我们在加载保存的模型参数时,需要事先创建一个和保存模型(参数)时结构一样的模型(LeNet2),之后采用load_state_dict()方法将保存的模型参数存储在新创建的模型中。
常用的小技巧——checkpoint:
 checkpoint断点续训练可以解决我们因为某种原因导致模型训练终止而可能需要重新训练、重复训练的这一个问题,这对于大型模型来说是比较耗时耗力的0因此在模型训练过程中存在一个机制,以备我们在模型训练中断之后可以继续接着这个checkpoint继续训练,而不必再from scratch从头训练了。
checkpoint断点续训练可以解决我们因为某种原因导致模型训练终止而可能需要重新训练、重复训练的这一个问题,这对于大型模型来说是比较耗时耗力的0因此在模型训练过程中存在一个机制,以备我们在模型训练中断之后可以继续接着这个checkpoint继续训练,而不必再from scratch从头训练了。
pytorch中checkpoint的实现:

模型微调——finetune
- Transfer Learning & Model Finetune
- Pytorch中的Finetune
Transfer Learning:
机器学习分支,研究源域(source domain)的知识如何应用到目标域(target domain)。
 在上面这个图中,左边是一个传统的机器学习任务,在这个任务中我们是对不同的任务分别的进行学习,得到一个称之为Learning System的一个模型,三个不同任务就会得到三个不同的模型;右边的任务则不同它被划分为一个源任务和目标任务,这两个任务之间有一定的关联,首先对源任务进行学习,学习得到的我们称之为knowledge知识,而在右边的目标任务里我们会利用源任务里学习到的knowledge进行学习、进行训练,最终得到Learning System,这一过程就是迁移学习的过程(不仅用到了目标任务的内容也用到了源任务的内容)。
在上面这个图中,左边是一个传统的机器学习任务,在这个任务中我们是对不同的任务分别的进行学习,得到一个称之为Learning System的一个模型,三个不同任务就会得到三个不同的模型;右边的任务则不同它被划分为一个源任务和目标任务,这两个任务之间有一定的关联,首先对源任务进行学习,学习得到的我们称之为knowledge知识,而在右边的目标任务里我们会利用源任务里学习到的knowledge进行学习、进行训练,最终得到Learning System,这一过程就是迁移学习的过程(不仅用到了目标任务的内容也用到了源任务的内容)。
参考文献:《A Survey On Transfer Learning》
下面介绍深度学习当中的模型微调:
我们知道在深度学习神经网络中对模型的训练主要训练和学习的是模型的参数,也就是权重,这里先暂时不提偏差,而通常将模型的权重称作为“知识”,在不同任务上学习的“知识”是可以进行迁移的,把这些“知识”迁移到新任务中,这样就完成了一个transfer learning。通常在新任务中可用于训练模型的数据量较小,不足以去训练一个较大的模型,因此就可以采用model finetune的方式来辅助我们在新任务中去训练一个较好的模型,让我们的模型训练的更快。

通常来说,一个神经网络模型由于其特性而可以被划分成两大部分,前一部分是特征提取器,后一部分是分类器;类似地,模型的参数也可以由此进行划分,用于特征提取的部分一般认为是不同任务之间有共性的地方,我们可以原封不动地进行迁移,而分类器部分通常跟具体的任务有关,所以这个是需要根据不同的任务进行更改的。(通常改变的是最后的输出层)
模型微调步骤:
- 获取预训练模型参数
- 加载模型(load_state_dict)
- 修改输出层
模型微调训练方法:
- 固定预训练的参数(requires_grad=False;lr=0)
- Features Extractor较小学习率(params_group)
finetune案例
Finetune Resnet-18 用于二分类
蚂蚁蜜蜂二分类数据
训练集:各120~张 验证集:各70~张
数据链接:https://download.pytorch.org/tutorial/hymenoptera_data.zip
模型链接:https://download.pytorch.org/models/resnet18-5c106cde.pth

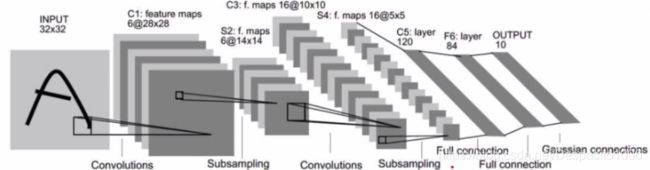
这是ResNet-18的模型架构,通常将这里的’conv1’,‘bn1’,‘relu’,'maxpool’视为一组操作,它们的作用就是对图像进行特征提取操作;之后又是四个basicblock基本的残差块儿,‘layer1’,‘layer2’,‘layer3’,‘layer4’,它们的作用也是特征提取;重要的是最后的fc全连接层,它有1000个神经元因为这个ResNet-18是在ImageNet数据集上训练的,这里是1000类的分类任务,但由于我们目前要做的是个二分类,因此在fc层这里需要进行更改,将1000个神经元改为2个神经元。
 这个是使用预训练的ResNet-18模型进行训练的,可以看到只需加载一个已经训练好的resnet18-5c106cde.pth文件,之后因为我们认为卷积层部分是特征提取部分这部分是通用的所以我们不对它们进行更改,因此冻结卷积层,我们需要更改的是最后一层输出层,将其类别数更改为2,这时我们仍需获取预训练模型的最后一层,获取该层网络层的输入in_features,以及新任务的类别数classes,并将它们输入到新创建的Linear层中,即可完成迁移学习的过程。
这个是使用预训练的ResNet-18模型进行训练的,可以看到只需加载一个已经训练好的resnet18-5c106cde.pth文件,之后因为我们认为卷积层部分是特征提取部分这部分是通用的所以我们不对它们进行更改,因此冻结卷积层,我们需要更改的是最后一层输出层,将其类别数更改为2,这时我们仍需获取预训练模型的最后一层,获取该层网络层的输入in_features,以及新任务的类别数classes,并将它们输入到新创建的Linear层中,即可完成迁移学习的过程。

之后我们需要采用模型微调的训练方法——特征提取部分选用较小的学习率,全连接层部分选用较大的学习率,可以看到在if-else分支中,第一行代码的作用是获取全连接层的参数,第二行是使用lambda表达式确定除连接层之外也就是特征提取部分的模型参数,之后在optim.SGD方法中设置了一个参数组params_group,分别对特征提取部分的参数和全连接层的参数设置了不同的学习率。
GPU的使用
- CPU与GPU
- 数据迁移至GPU
- 多GPU并行运算
GPU in Pytorch
CPU(Central Processing Unit,中央处理器):主要包括控制器和运算器
GPU(Graphics Processing Unit,图形处理器):处理统一的,无依赖的大规模数据运算
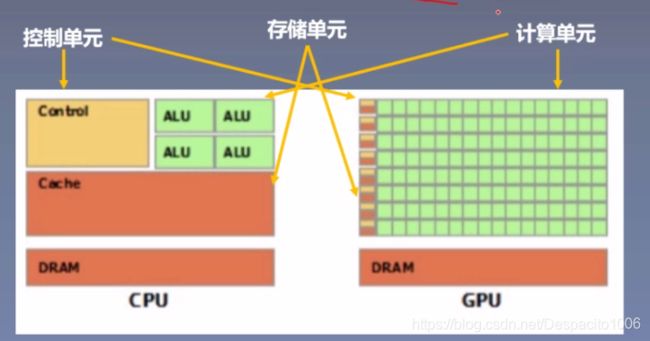
注意:pytorch中张量的运算应处于同一个处理器上,要么同时在CPU上计算,要么同时在GPU上计算。
那么在pytorch中将数据从这两个处理器上进行切换存储使用的是
to()函数:
 这里的data主要是两种数据类型:1.Tensor 2.Module
这里的data主要是两种数据类型:1.Tensor 2.Module
而针对这两个数据类型,在pytorch中存在相对应的两个to函数可以使用:

to函数:转换数据类型/设备
- tensor.to(*args,**kwargs)
- module.to(*args,**kwargs)
区别:张量不执行inplace,模型执行inplace
torch.cuda常用方法
- torch.cuda.device_count():计算当前可见可用gpu数
- torch.cuda.get_device_name():获取gpu名称
- torch.cuda.manual_seed():为当前gpu设置随机种子
- torch.cuda.manual_seed_all():为所有可见可用gpu设置随机种子
- torch.cuda.set_device():设置主gpu为哪一个物理gpu(不推荐)
推荐:os.environ.setdefault(“CUDA_VISIBLE_DEVICES”,“2,3”)
多gpu运算的分发并行机制
多gpu运算的分发并行机制总共有三步:
1.分发 2.并行运算 3.结果回收
torch.nn.DataParallel:
功能:包装模型,实现分发并行机制

主要参数:
- module:需要包装分发的模型
- device_ids:可分发的gpu,默认分发到所有可见可用gpu
- output_device:结果输出设备
Pytorch常见报错
由深度之眼公众号提供的Pytorch常见错误与坑汇总文档:
https://shimo.im/docs/PvgHytYygPVGJ8Hv/《Pytorch常见报错/坑汇总》
pytorch学习手册参考链接:
https://github.com/TingsongYu/PyTorch_Tutorial