Transformer 自注意力机制 及完整代码实现
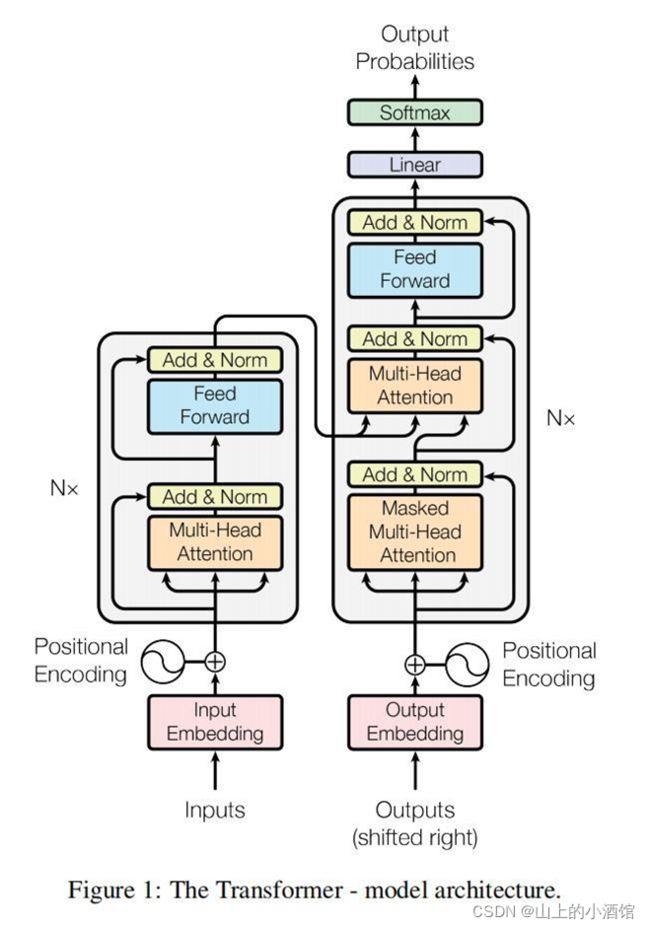
词嵌入(Word Embedding)
将输入单词用 One-Hot 形式编码成序列向量,向量长度就是预定义的词汇表中拥有的单词量。One-Hot 形式编码看似简洁,但缺点是稀疏,对于较大的字典会很长,浪费资源。更重要的是无法体现两个有关系的词之间的联系。因此,另一种词的表示方式,使得具有相近意思的词有相近的表示,即Word Embedding。设计一个可学习的权重矩阵W,将词向量与这个矩阵点乘,即得到词的表示。
假设like=[1,0,0,0],love=[0,0,0,1]。
权重矩阵W=[[w00,w01,w02],[w10,w11,w12],[w20,w21,w22],[w30,w31,w32]]
将词向量与权重矩阵W点乘结果为[w00,w01,w02]和[w30,w31,w32] ,在网络学习过程中权重矩阵的参数会不断进行更新,直至越来越相似。另外,还起到了降维的效果。
编码器的每个句子是长为seq_len的语言序列,每个单词(汉字)可化长为d_model=512的向量,输入为batch*512*seq_len(x1,x2,…xn)。编码器可以看到整个输入的句子,将信息(时序)做一次汇聚(多个自注意力),提取特征。输出为batch*512*seq_len(z1,z2,…zn)
解码器收到解码指令(start of scentence),开始解码,先做subsequence_mask,看不到当前时刻后的信息(一个单词一个单词翻译),然后进行自注意力机制,然后拿出Q并编码器输出的K进行相似度计算(权重),此时注意力attention不是自注意力,因为K、V来自编码器的输出。
(1)数据构建、分别建立词库、模型参数:词向量d_model=512;线性层中间d_ff=2048;d_q=d_k=d_v=64;每个头维数n_layer=64;n_heads=8;
(2)自建库MyDataSet,加载数据Data.DataLoader
(3)位置编码PositionalEncoding:将位置信息与词向量相加,加入了位置信息。
x=x+self.pe[:x.size(0),:]
(4)Pad_mask:序列(句子),不够长时用pad填补。为了让pad的位置不参与权重计算,将pad=0的位置设为true。
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1)#判断是否为0,是0则为True,True则masked,并扩一个维度。# 例如:seq_k = [[1,2,3,4,0], [1,2,3,5,0]],-->[[F,F,F,F,T]][F,F,F,F,T]
return pad_attn_mask.expand(batch_size, len_q, len_k) # [batch_size, len_q, len_k](5)subsequence_mask:一次只翻译一个词
subsequence_mask = np.triu(np.ones(attn_shape), k=1) # 生成一个上三角矩阵(6)ScaleDotProductAttention:
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k)
scores.masked_fill_(attn_mask, -1e9) # mask is True.的位置补一个很小的负数,softmax后为0。
attn = nn.Softmax(dim=-1)(scores) # 对最后一个维度(v)做softmax,得到权重
context = torch.matmul(attn, V) # context: [batch_size, n_heads, len_q, d_v];(7)MultiHeadAttention:多头注意力,投影
#input_Q(n*512)* W_Q (512*512)=Q(n*512(64*8))分成八个头
#QKV的线性投影层,不改变QKV的形状。
self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False)
# Q: [batch_size, n_heads, len_q, d_k]。
Q = self.W_Q(input_Q).view(batch_size, -1, n_heads, d_k).transpose(1, 2)
# 因为是多头,所以mask矩阵要扩充成4维的
# attn_mask: [batch_size, seq_len, seq_len] -> [batch_size, n_heads, seq_len, seq_len];
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)
context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask)#点积相似度(8)PoswiseFeedForwardNet:两个线性层,512-2048-512
(9)EncoderLayer(一层注意力层、一层前馈网络)
# 第一个enc_inputs * W_Q = Q(8*64)
# 第二个enc_inputs * W_K = K
# 第三个enc_inputs * W_V = V
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs,
enc_self_attn_mask)
enc_outputs = self.pos_ffn(enc_outputs)#前馈网络,多层感知机(10)DncoderLayer(两层注意力层、一层前馈网络)
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs,
dec_self_attn_mask) # 这里的Q,K,V全是Decoder自己的输入
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs,
dec_enc_attn_mask) # Attention层的Q(来自decoder) 和 K,V(来自encoder)
dec_outputs = self.pos_ffn(dec_outputs) # [batch_size, tgt_len, d_model](11)Encoder(传入编码器输入,传出编码器输出)e
nc_outputs = self.src_emb(enc_inputs)#词向量
enc_outputs = self.pos_emb(enc_outputs.transpose(0, 1)).transpose(0, 1)#位置信息
# 上一个block的输出enc_outputs作为当前block的输入
for layer in self.layers:
enc_outputs, enc_self_attn = layer(enc_outputs, enc_self_attn_mask)(12)Decoder(传入三个参数:编码器输出、编码器输入、解码器输入。返回解码器输出。
"""
code by Tae Hwan Jung(Jeff Jung) @graykode, Derek Miller @dmmiller612, modify by shwei
Reference: https://github.com/jadore801120/attention-is-all-you-need-pytorch
https://github.com/JayParks/transformer
"""
# ====================================================================================================
# 数据构建
import math
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.utils.data as Data
device = 'cpu'
# device = 'cuda'
# transformer epochs
epochs = 100
# epochs = 1000
# 这里我没有用什么大型的数据集,而是手动输入了两对德语→英语的句子
# 还有每个字的索引也是我手动硬编码上去的,主要是为了降低代码阅读难度
# S: Symbol that shows starting of decoding input
# E: Symbol that shows starting of decoding output
# P: Symbol that will fill in blank sequence if current batch data size is short than time steps
sentences = [
# 德语和英语的单词个数不要求相同
# enc_input dec_input dec_output
['ich mochte ein bier P', 'S i want a beer .', 'i want a beer . E'],
['ich mochte ein cola P', 'S i want a coke .', 'i want a coke . E']
]
# 德语和英语的单词要分开建立词库
# Padding Should be Zero
src_vocab = {'P': 0, 'ich': 1, 'mochte': 2, 'ein': 3, 'bier': 4, 'cola': 5}
src_idx2word = {i: w for i, w in enumerate(src_vocab)}
src_vocab_size = len(src_vocab)
tgt_vocab = {'P': 0, 'i': 1, 'want': 2, 'a': 3, 'beer': 4, 'coke': 5, 'S': 6, 'E': 7, '.': 8}
idx2word = {i: w for i, w in enumerate(tgt_vocab)}
tgt_vocab_size = len(tgt_vocab)
src_len = 5 # (源句子的长度)enc_input max sequence length
tgt_len = 6 # dec_input(=dec_output) max sequence length
# Transformer Parameters
d_model = 512 # Embedding Size(token embedding和position编码的维度)
d_ff = 2048 # FeedForward dimension (两次线性层中的隐藏层 512->2048->512,线性层是用来做特征提取的),当然最后会再接一个projection层
d_k = d_v = 64 # dimension of K(=Q), V(Q和K的维度需要相同,这里为了方便让K=V)
n_layers = 6 # number of Encoder of Decoder Layer(Block的个数)
n_heads = 8 # number of heads in Multi-Head Attention(有几套头)
# ==============================================================================================
# 数据构建
def make_data(sentences):
"""把单词序列转换为数字序列"""
enc_inputs, dec_inputs, dec_outputs = [], [], []
for i in range(len(sentences)):
enc_input = [[src_vocab[n] for n in sentences[i][0].split()]] # [[1, 2, 3, 4, 0], [1, 2, 3, 5, 0]]
dec_input = [[tgt_vocab[n] for n in sentences[i][1].split()]] # [[6, 1, 2, 3, 4, 8], [6, 1, 2, 3, 5, 8]]
dec_output = [[tgt_vocab[n] for n in sentences[i][2].split()]] # [[1, 2, 3, 4, 8, 7], [1, 2, 3, 5, 8, 7]]
print(enc_input)
enc_inputs.extend(enc_input)
dec_inputs.extend(dec_input)
dec_outputs.extend(dec_output)
print(enc_inputs)
return torch.LongTensor(enc_inputs), torch.LongTensor(dec_inputs), torch.LongTensor(dec_outputs)
enc_inputs, dec_inputs, dec_outputs = make_data(sentences)
class MyDataSet(Data.Dataset):
"""自定义DataLoader"""
def __init__(self, enc_inputs, dec_inputs, dec_outputs):
super(MyDataSet, self).__init__()
self.enc_inputs = enc_inputs
self.dec_inputs = dec_inputs
self.dec_outputs = dec_outputs
def __len__(self):
return self.enc_inputs.shape[0]
def __getitem__(self, idx):
return self.enc_inputs[idx], self.dec_inputs[idx], self.dec_outputs[idx]
loader = Data.DataLoader(MyDataSet(enc_inputs, dec_inputs, dec_outputs), 2, True)
# ====================================================================================================
# Transformer模型
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout=0.1, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
"""
x: [seq_len, batch_size, d_model]
"""
x = x + self.pe[:x.size(0), :]
return self.dropout(x)
def get_attn_pad_mask(seq_q, seq_k):
# pad mask的作用:在对value向量加权平均的时候,可以让pad对应的alpha_ij=0,这样注意力就不会考虑到pad向量
"""这里的q,k表示的是两个序列(跟注意力机制的q,k没有关系),例如encoder_inputs (x1,x2,..xm)和encoder_inputs (x1,x2..xm)
encoder和decoder都可能调用这个函数,所以seq_len视情况而定
seq_q: [batch_size, seq_len]
seq_k: [batch_size, seq_len]
seq_len could be src_len or it could be tgt_len
seq_len in seq_q and seq_len in seq_k maybe not equal
"""
batch_size, len_q = seq_q.size() # 这个seq_q只是用来expand维度的
batch_size, len_k = seq_k.size()
# eq(zero) is PAD token
# 例如:seq_k = [[1,2,3,4,0], [1,2,3,5,0]]
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # [batch_size, 1, len_k], True is masked
return pad_attn_mask.expand(batch_size, len_q, len_k) # [batch_size, len_q, len_k] 构成一个立方体(batch_size个这样的矩阵)
def get_attn_subsequence_mask(seq):
"""建议打印出来看看是什么的输出(一目了然)
seq: [batch_size, tgt_len]
"""
attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
# attn_shape: [batch_size, tgt_len, tgt_len]
subsequence_mask = np.triu(np.ones(attn_shape), k=1) # 生成一个上三角矩阵
subsequence_mask = torch.from_numpy(subsequence_mask).byte()
return subsequence_mask # [batch_size, tgt_len, tgt_len]
# ==========================================================================================
class ScaledDotProductAttention(nn.Module):
def __init__(self):
super(ScaledDotProductAttention, self).__init__()
def forward(self, Q, K, V, attn_mask):
"""
Q: [batch_size, n_heads, len_q, d_k]
K: [batch_size, n_heads, len_k, d_k]
V: [batch_size, n_heads, len_v(=len_k), d_v]
attn_mask: [batch_size, n_heads, seq_len, seq_len]
说明:在encoder-decoder的Attention层中len_q(q1,..qt)和len_k(k1,...km)可能不同
"""
scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(d_k) # scores : [batch_size, n_heads, len_q, len_k]
# mask矩阵填充scores(用-1e9填充scores中与attn_mask中值为1位置相对应的元素)
scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is True.
attn = nn.Softmax(dim=-1)(scores) # 对最后一个维度(v)做softmax
# scores : [batch_size, n_heads, len_q, len_k] * V: [batch_size, n_heads, len_v(=len_k), d_v]
context = torch.matmul(attn, V) # context: [batch_size, n_heads, len_q, d_v]
# context:[[z1,z2,...],[...]]向量, attn注意力稀疏矩阵(用于可视化的)
return context, attn
class MultiHeadAttention(nn.Module):
"""这个Attention类可以实现:
Encoder的Self-Attention
Decoder的Masked Self-Attention
Encoder-Decoder的Attention
"""
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False) # q,k必须维度相同,不然无法做点积
self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False)
self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False)
self.fc = nn.Linear(n_heads * d_v, d_model, bias=False)
def forward(self, input_Q, input_K, input_V, attn_mask):
"""
input_Q: [batch_size, len_q, d_model]
input_K: [batch_size, len_k, d_model]
input_V: [batch_size, len_v(=len_k), d_model]
attn_mask: [batch_size, seq_len, seq_len]
"""
residual, batch_size = input_Q, input_Q.size(0)
# 下面的多头的参数矩阵是放在一起做线性变换的,然后再拆成多个头,这是工程实现的技巧
# B: batch_size, S:seq_len, D: dim
# (B, S, D) -proj-> (B, S, D_new) -split-> (B, S, Head, W) -trans-> (B, Head, S, W)
# 线性变换 拆成多头
# Q: [batch_size, n_heads, len_q, d_k]
Q = self.W_Q(input_Q).view(batch_size, -1, n_heads, d_k).transpose(1, 2)
# K: [batch_size, n_heads, len_k, d_k] # K和V的长度一定相同,维度可以不同
K = self.W_K(input_K).view(batch_size, -1, n_heads, d_k).transpose(1, 2)
# V: [batch_size, n_heads, len_v(=len_k), d_v]
V = self.W_V(input_V).view(batch_size, -1, n_heads, d_v).transpose(1, 2)
# 因为是多头,所以mask矩阵要扩充成4维的
# attn_mask: [batch_size, seq_len, seq_len] -> [batch_size, n_heads, seq_len, seq_len]
attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1, 1)
# context: [batch_size, n_heads, len_q, d_v], attn: [batch_size, n_heads, len_q, len_k]
context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask)
# 下面将不同头的输出向量拼接在一起
# context: [batch_size, n_heads, len_q, d_v] -> [batch_size, len_q, n_heads * d_v]
context = context.transpose(1, 2).reshape(batch_size, -1, n_heads * d_v)
# 再做一个projection
output = self.fc(context) # [batch_size, len_q, d_model]
return nn.LayerNorm(d_model).to(device)(output + residual), attn
# Pytorch中的Linear只会对最后一维操作,所以正好是我们希望的每个位置用同一个全连接网络
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.fc = nn.Sequential(
nn.Linear(d_model, d_ff, bias=False),
nn.ReLU(),
nn.Linear(d_ff, d_model, bias=False)
)
def forward(self, inputs):
"""
inputs: [batch_size, seq_len, d_model]
"""
residual = inputs
output = self.fc(inputs)
return nn.LayerNorm(d_model).to(device)(output + residual) # [batch_size, seq_len, d_model]
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, enc_inputs, enc_self_attn_mask):
"""E
enc_inputs: [batch_size, src_len, d_model]
enc_self_attn_mask: [batch_size, src_len, src_len] mask矩阵(pad mask or sequence mask)
"""
# enc_outputs: [batch_size, src_len, d_model], attn: [batch_size, n_heads, src_len, src_len]
# 第一个enc_inputs * W_Q = Q
# 第二个enc_inputs * W_K = K
# 第三个enc_inputs * W_V = V
enc_outputs, attn = self.enc_self_attn(enc_inputs, enc_inputs, enc_inputs,
enc_self_attn_mask) # enc_inputs to same Q,K,V(未线性变换前)
enc_outputs = self.pos_ffn(enc_outputs)
# enc_outputs: [batch_size, src_len, d_model]
return enc_outputs, attn
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention()
self.dec_enc_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, dec_inputs, enc_outputs, dec_self_attn_mask, dec_enc_attn_mask):
"""
dec_inputs: [batch_size, tgt_len, d_model]
enc_outputs: [batch_size, src_len, d_model]
dec_self_attn_mask: [batch_size, tgt_len, tgt_len]
dec_enc_attn_mask: [batch_size, tgt_len, src_len]
"""
# dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len]
dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs,
dec_self_attn_mask) # 这里的Q,K,V全是Decoder自己的输入
# dec_outputs: [batch_size, tgt_len, d_model], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
dec_outputs, dec_enc_attn = self.dec_enc_attn(dec_outputs, enc_outputs, enc_outputs,
dec_enc_attn_mask) # Attention层的Q(来自decoder) 和 K,V(来自encoder)
dec_outputs = self.pos_ffn(dec_outputs) # [batch_size, tgt_len, d_model]
return dec_outputs, dec_self_attn, dec_enc_attn # dec_self_attn, dec_enc_attn这两个是为了可视化的
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.src_emb = nn.Embedding(src_vocab_size, d_model) # token Embedding
self.pos_emb = PositionalEncoding(d_model) # Transformer中位置编码时固定的,不需要学习
self.layers = nn.ModuleList([EncoderLayer() for _ in range(n_layers)])
def forward(self, enc_inputs):
"""
enc_inputs: [batch_size, src_len]
"""
enc_outputs = self.src_emb(enc_inputs) # [batch_size, src_len, d_model]
enc_outputs = self.pos_emb(enc_outputs.transpose(0, 1)).transpose(0, 1) # [batch_size, src_len, d_model]
# Encoder输入序列的pad mask矩阵
enc_self_attn_mask = get_attn_pad_mask(enc_inputs, enc_inputs) # [batch_size, src_len, src_len]
enc_self_attns = [] # 在计算中不需要用到,它主要用来保存你接下来返回的attention的值(这个主要是为了你画热力图等,用来看各个词之间的关系
for layer in self.layers: # for循环访问nn.ModuleList对象
# 上一个block的输出enc_outputs作为当前block的输入
# enc_outputs: [batch_size, src_len, d_model], enc_self_attn: [batch_size, n_heads, src_len, src_len]
enc_outputs, enc_self_attn = layer(enc_outputs,
enc_self_attn_mask) # 传入的enc_outputs其实是input,传入mask矩阵是因为你要做self attention
enc_self_attns.append(enc_self_attn) # 这个只是为了可视化
return enc_outputs, enc_self_attns
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model) # Decoder输入的embed词表
self.pos_emb = PositionalEncoding(d_model)
self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)]) # Decoder的blocks
def forward(self, dec_inputs, enc_inputs, enc_outputs):
"""
dec_inputs: [batch_size, tgt_len]
enc_inputs: [batch_size, src_len]
enc_outputs: [batch_size, src_len, d_model] # 用在Encoder-Decoder Attention层
"""
dec_outputs = self.tgt_emb(dec_inputs) # [batch_size, tgt_len, d_model]
dec_outputs = self.pos_emb(dec_outputs.transpose(0, 1)).transpose(0, 1).to(
device) # [batch_size, tgt_len, d_model]
# Decoder输入序列的pad mask矩阵(这个例子中decoder是没有加pad的,实际应用中都是有pad填充的)
dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs).to(device) # [batch_size, tgt_len, tgt_len]
# Masked Self_Attention:当前时刻是看不到未来的信息的
dec_self_attn_subsequence_mask = get_attn_subsequence_mask(dec_inputs).to(
device) # [batch_size, tgt_len, tgt_len]
# Decoder中把两种mask矩阵相加(既屏蔽了pad的信息,也屏蔽了未来时刻的信息)
dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequence_mask),
0).to(device) # [batch_size, tgt_len, tgt_len]; torch.gt比较两个矩阵的元素,大于则返回1,否则返回0
# 这个mask主要用于encoder-decoder attention层
# get_attn_pad_mask主要是enc_inputs的pad mask矩阵(因为enc是处理K,V的,求Attention时是用v1,v2,..vm去加权的,要把pad对应的v_i的相关系数设为0,这样注意力就不会关注pad向量)
# dec_inputs只是提供expand的size的
dec_enc_attn_mask = get_attn_pad_mask(dec_inputs, enc_inputs) # [batc_size, tgt_len, src_len]
dec_self_attns, dec_enc_attns = [], []
for layer in self.layers:
# dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
# Decoder的Block是上一个Block的输出dec_outputs(变化)和Encoder网络的输出enc_outputs(固定)
dec_outputs, dec_self_attn, dec_enc_attn = layer(dec_outputs, enc_outputs, dec_self_attn_mask,
dec_enc_attn_mask)
dec_self_attns.append(dec_self_attn)
dec_enc_attns.append(dec_enc_attn)
# dec_outputs: [batch_size, tgt_len, d_model]
return dec_outputs, dec_self_attns, dec_enc_attns
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
self.encoder = Encoder().to(device)
self.decoder = Decoder().to(device)
self.projection = nn.Linear(d_model, tgt_vocab_size, bias=False).to(device)
def forward(self, enc_inputs, dec_inputs):
"""Transformers的输入:两个序列
enc_inputs: [batch_size, src_len]
dec_inputs: [batch_size, tgt_len]
"""
# tensor to store decoder outputs
# outputs = torch.zeros(batch_size, tgt_len, tgt_vocab_size).to(self.device)
# enc_outputs: [batch_size, src_len, d_model], enc_self_attns: [n_layers, batch_size, n_heads, src_len, src_len]
# 经过Encoder网络后,得到的输出还是[batch_size, src_len, d_model]
enc_outputs, enc_self_attns = self.encoder(enc_inputs)
# dec_outputs: [batch_size, tgt_len, d_model], dec_self_attns: [n_layers, batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [n_layers, batch_size, tgt_len, src_len]
dec_outputs, dec_self_attns, dec_enc_attns = self.decoder(dec_inputs, enc_inputs, enc_outputs)
# dec_outputs: [batch_size, tgt_len, d_model] -> dec_logits: [batch_size, tgt_len, tgt_vocab_size]
dec_logits = self.projection(dec_outputs)
return dec_logits.view(-1, dec_logits.size(-1)), enc_self_attns, dec_self_attns, dec_enc_attns
model = Transformer().to(device)
# 这里的损失函数里面设置了一个参数 ignore_index=0,因为 "pad" 这个单词的索引为 0,这样设置以后,就不会计算 "pad" 的损失(因为本来 "pad" 也没有意义,不需要计算)
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.SGD(model.parameters(), lr=1e-3, momentum=0.99) # 用adam的话效果不好
# ====================================================================================================
losses = []
for epoch in range(epochs):
for enc_inputs, dec_inputs, dec_outputs in loader:
"""
enc_inputs: [batch_size, src_len]
dec_inputs: [batch_size, tgt_len]
dec_outputs: [batch_size, tgt_len]
"""
enc_inputs, dec_inputs, dec_outputs = enc_inputs.to(device), dec_inputs.to(device), dec_outputs.to(device)
# outputs: [batch_size * tgt_len, tgt_vocab_size]
outputs, enc_self_attns, dec_self_attns, dec_enc_attns = model(enc_inputs, dec_inputs)
loss = criterion(outputs, dec_outputs.view(-1)) # dec_outputs.view(-1):[batch_size * tgt_len * tgt_vocab_size]
print('Epoch:', '%04d' % (epoch + 1), 'loss =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
losses.append(loss.data.item())
#loss曲线
import matplotlib; matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
plt.xkcd()
plt.xlabel('Epoce')
plt.ylabel('loss')
plt.plot(losses)
plt.show()
def greedy_decoder(model, enc_input, start_symbol):
"""贪心编码
For simplicity, a Greedy Decoder is Beam search when K=1. This is necessary for inference as we don't know the
target sequence input. Therefore we try to generate the target input word by word, then feed it into the transformer.
Starting Reference: http://nlp.seas.harvard.edu/2018/04/03/attention.html#greedy-decoding
:param model: Transformer Model
:param enc_input: The encoder input
:param start_symbol: The start symbol. In this example it is 'S' which corresponds to index 4
:return: The target input
"""
enc_outputs, enc_self_attns = model.encoder(enc_input)
dec_input = torch.zeros(1, 0).type_as(enc_input.data)
terminal = False
next_symbol = start_symbol
while not terminal:
# 预测阶段:dec_input序列会一点点变长(每次添加一个新预测出来的单词)
dec_input = torch.cat([dec_input.to(device), torch.tensor([[next_symbol]], dtype=enc_input.dtype).to(device)],
-1)
dec_outputs, _, _ = model.decoder(dec_input, enc_input, enc_outputs)
projected = model.projection(dec_outputs)
prob = projected.squeeze(0).max(dim=-1, keepdim=False)[1]
# 增量更新(我们希望重复单词预测结果是一样的)
# 我们在预测是会选择性忽略重复的预测的词,只摘取最新预测的单词拼接到输入序列中
next_word = prob.data[-1] # 拿出当前预测的单词(数字)。我们用x'_t对应的输出z_t去预测下一个单词的概率,不用z_1,z_2..z_{t-1}
next_symbol = next_word
if next_symbol == tgt_vocab["E"]:
terminal = True
# print(next_word)
# greedy_dec_predict = torch.cat(
# [dec_input.to(device), torch.tensor([[next_symbol]], dtype=enc_input.dtype).to(device)],
# -1)
greedy_dec_predict = dec_input[:, 1:]
return greedy_dec_predict
# ==========================================================================================
# 预测阶段
enc_inputs, _, _ = next(iter(loader))
for i in range(len(enc_inputs)):
greedy_dec_predict = greedy_decoder(model, enc_inputs[i].view(1, -1).to(device), start_symbol=tgt_vocab["S"])
print(enc_inputs[i], '->', greedy_dec_predict.squeeze())
print([src_idx2word[t.item()] for t in enc_inputs[i]], '->',
[idx2word[n.item()] for n in greedy_dec_predict.squeeze()])
python的学习还是要多以练习为主,想要练习python的同学,推荐可以去看,他们现在的IT题库内容很丰富,属于国内做的很好的了,而且是课程+刷题+面经+求职+讨论区分享,一站式求职学习网站,最最最重要的里面的资源全部免费。
牛客网 - 找工作神器|笔试题库|面试经验|实习招聘内推,求职就业一站解决_牛客网求职之前,先上牛客,就业找工作一站解决。互联网IT技术/产品/运营/硬件/汽车机械制造/金融/财务管理/审计/银行/市场营销/地产/快消/管培生等等专业技能学习/备考/求职神器,在线进行企业校招实习笔试面试真题模拟考试练习,全面提升求职竞争力,找到好工作,拿到好offer。 https://www.nowcoder.com/link/pc_csdncpt_ssdxjg_python
https://www.nowcoder.com/link/pc_csdncpt_ssdxjg_python
他们这个python的练习题,知识点编排详细,题目安排合理,题目表述以指导的形式进行。整个题单覆盖了Python入门的全部知识点以及全部语法,通过知识点分类逐层递进,从Hello World开始到最后的实践任务,都会非常详细地指导你应该使用什么函数,应该怎么输入输出。
牛客网(牛客网 - 找工作神器|笔试题库|面试经验|实习招聘内推,求职就业一站解决_牛客网)还提供题解专区和讨论区会有大神提供题解思路,对新手玩家及其友好,有不清楚的语法,不理解的地方,看看别人的思路,别人的代码,也许就能豁然开朗。
快点击下方链接学起来吧!
牛客网 - 找工作神器|笔试题库|面试经验|实习招聘内推,求职就业一站解决_牛客网
参考:
参考
Reference: https://github.com/jadore801120/attention-is-all-you-need-pytorch https://github.com/JayParks/transformer
Transformer论文逐段精读【论文精读】_哔哩哔哩_bilibili https://www.bilibili.com/video/BV1pu411o7BE?spm_id_from=333.999.0.0
https://www.bilibili.com/video/BV1pu411o7BE?spm_id_from=333.999.0.0