CNN卷积神经网络总结
1 DNN和CNN
1.1 DNN(Deep Neural Networks,深度神经网络)
DNN是一个全连接的深度神经网络,也可以用作图像识别,在mnist上的表现也很不错,可以参考这篇文章。鉴于为了介绍CNN和DNN的区别,在这篇文章中都叫做全连接神经网络。全连接神经网络中,每相邻的两层网络之间的节点都是相互有边相连。上一层的每个神经元均要链接下一层的每个神经元,于是一般将每一层的神经元排成一排,如图所示:

而对于卷积神经网络,相邻的两个网络层之间只有部分节点相连,为了方便展示神经元的维度,一般会展示成三维矩阵的形式。如图所示:
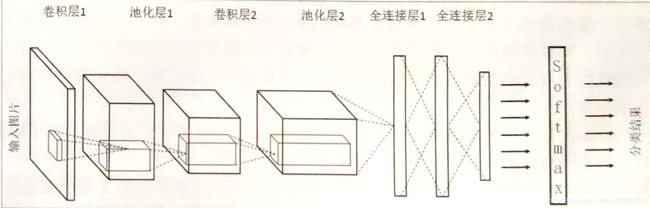
对于输入输出而言,卷积神经网络与全连接神经网络十分大同小异。输入是图像的原始像素,输入的三维矩阵的长和宽分别是图片的长宽像素数,高是图像的通道数,对于黑白的图像来说,通道数就是1,对于RGB的图像来说,通道数就是3。输入的矩阵中间经过一系列的卷积池化等操作进入全连接层,以softmax为例,输出为各个分类的概率大小。
卷积神经网络与全连接神经网络最主要的区别就是网络层与层神经元之间的链接方式不同。全连接神经网络的链接方式是层与层之间的每个神经元均相互连接,而卷积神经网络的相邻的两个网络层之间只有部分节点相连。
卷积神经网络在图像领域的效果十分突出,上面也提到了,全连接神经网络对于MNIST数据集的识别效果也十分好,那么,为什么要引入CNN,或者使用CNN的好处是什么?
最简单的回答就是,全连接神经网络无法很好的处理复杂的图片数据(这里复杂的图片数据指的是,像素高,颜色通道多的图片),因为使用全连接神经网络最大的一个问题就是,全连接神经网络的参数太多。任意两个神经元相连就会产生一个参数。例如MNIST数据集的输入神经元有28*28=784个,假设数据为28*28像素的单通道图像数据,有一个单隐层且隐层神经元有500个的全连接神经网络,此时参数就有28*28*1*500+500 = 392500个参数,参数多达将近40万个;如果把数据换为CIFAR-10的数据,32*32像素且有RGB3个通道,仍然是有一个单隐层且隐层神经元有500个的全连接神经网络,32*32*3*500+500,参数多达将近150万个,对于一个简单的网络结构,就有如此多的参数会使神经网络训练十分慢,而且参数过多相比数据量不足,很容易导致过拟合。因此引入了卷积神经网络,使用另一种方式减少层与层之间的连接,大大减少参数数量。
1.2 简述CNN结构(Convolutional Neural Networks,卷积神经网络)
上面的图展示了CNN的网络结构图,可以看到有五个部分组成,分别是输入层、输出层、卷积层、池化层、全连接层。下面简单概述了一下各个层在网络中是做什么的。
1.2.1 输入层
输入层是整个神经网络的输入,在处理图像任务时,输入层往往是图片的像素矩阵,部分输入神经元连接在下一层的一个神经元上,执行卷积的操作。CNN不光可以处理图像任务,也可以处理文本数据(TextCNN)或者其他结构类型的数据,当处理文本数据的时候,输入层就是文本embedding矩阵。
1.2.2 卷积层
卷积层是卷积神经网络的核心,卷积层中每一个节点的输入只是上一层神经网络中的一个小的部分,或者说是一个小的方块,通常大小为3*3或者5*5。卷积会让上一层的矩阵变得更深,而矩阵的大小(长和宽)的变化则不一定,理论上会变小,但是由于padding操作的存在,卷积对上层矩阵的大小的影响变得不确定。后面详细说padding。
1.2.3 池化层
池化层不会对矩阵的深度产生影响,但是会使矩阵变小。对于图片数据来说,可以理解为把一个像素高的图片变成了一个像素低的图片。这样做可以进一步缩小后续全连接层中神经元的数量,减少参数。对于池化层来说,相当于是把一个区域的像素块变成了一个像素,听上去好像这种方法不会起作用,甚至可能让模型效果变差,因为这种操作就损失了信息,但是实际上不是这样,通过池化操作可以提高后面全连接层的效率,减少参数数量,降低过拟合,使模型的效果变得更好。
换个思路想想,池化层所作的事是把一个区域的像素变成一个像素表示,这样肯定损失了信息,但是直觉上,这张照片分辨率变得低,就像马赛克一样,但是对于人眼来说,只要这个马赛克不是很严重,还是可以隐约看出这个图片是什么,对于神经网络也一样,通过降低图片的分辨率来提高模型的性能,还不会对模型的效果造成太大损失。而池化层是一定会对信息造成损失的,但是损失的信息其实是不太重要的那部分,自然就提高模型的效率。
1.2.4 全连接层
在经过多轮卷积和池化操作之后,图像原始像素信息已经被抽象成了信息含量更高的特征。因此也可以将卷积和池化看做是一个在提特征的操作,通过卷积层和池化层,模型自动去提取特征。有意思的是,至于怎么去提取特征,是根据数据训练出来,神经网络就会自动的根据数据来提取对模型分类有作用的特征。
1.2.5 Softmax层
最后这一层就是全连接层了,softmax用于多分类。最后一层不一定只能用softmax,只是在这个图中例子,使用了softmax。可以理解为,前面的卷积和池化在提特征,全连接层才是在真正的处理任务。也可以理解为使用卷积和池化提取模型中的特征。然后将提取好的特征输入到全连接网络中,这样就实现了卷积神经网络。如果把卷积和池化都看做为输入层的话,其实卷积神经网络就是一个全连接神经网络,前面卷积和池化的作用只不过是忽略为了原始数据中没用或者作用不明显的数据特征,使特征空间变小,方便后面全连接层的计算。
2 CNN的细节
2.1 局部感受野、权值共享
卷积神经网络的核心思想就是局部感受野、是权值共享和pooling层,以此来达到简化网络参数并使得网络具有一定程度的位移、尺度、缩放、非线性形变稳定性。
-
局部感受野:全连接神经网络处理MNIST时,像素之间是没有联系的,仅仅对像素做了线性排列,而实际上图片的空间上是局部联系的,每一个里面的像素共同决定了这个局部里面的特征,因此应该把图片划分成小块每个小块共同表示为特征,然后输入到神经元中每个神经元不需要对全部的图像做感受,只需要感受局部特征即可,然后在更高层将这些感受得到的不同的局部神经元综合起来就可以得到全局的信息了,这样可以减少连接的数目。实际上不是对图片进行划分,而是”滚动”向前的,每个小块之间又重叠,重叠部分的大小由stride决定。
-
权值共享:不同神经元之间的参数共享可以减少需要求解的参数,使用多种滤波器去卷积图像就会得到多种特征映射。权值共享其实就是对图像用同样的卷积核进行卷积操作,也就意味着第一个隐藏层的所有神经元所能检测到处于图像不同位置的完全相同的特征。其主要的能力就能检测到不同位置的同一类型特征,也就是卷积网络能很好的适应图像的小范围的平移性,即有较好的平移不变性(比如将输入图像的猫的位置移动之后,同样能够检测到猫的图像)
2.2 卷积操作
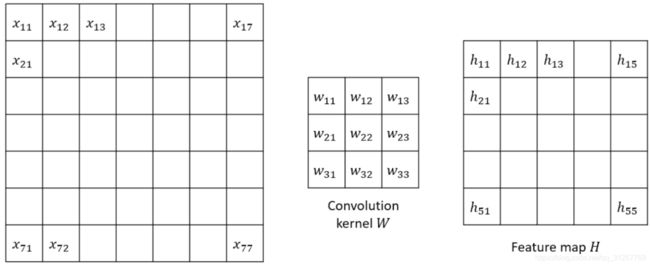
上图中左侧的就是待卷积的矩阵,中间的kernal就是卷积核,也有叫做filter过滤器的,右边的矩阵是原始矩阵经过卷积核卷积后得到的feature map矩阵。
具体卷积的操作将卷积核这个大小的区域在原始矩阵上从左到右从上到下这样移动,每移动一次就将当前覆盖的区域中的每个元素与卷积核对应位置的元素相乘再求和,最终得到一个值,填入feature map对应位置上,对原始矩阵完成卷积操作后就得到了右边的feature map,如下图。

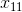 ~
~![]() 这九个元素依次与卷积核对应位置元素相乘再相加后得到的值就是
这九个元素依次与卷积核对应位置元素相乘再相加后得到的值就是![]() ,每完成一次卷积就将卷积核的位置移动一次,从左到右从上到下,然后进行下一次卷积,对input X完成整个矩阵的卷积操作就得到了feature map H。
,每完成一次卷积就将卷积核的位置移动一次,从左到右从上到下,然后进行下一次卷积,对input X完成整个矩阵的卷积操作就得到了feature map H。
Strid:strid可以理解为步长,也就是卷积核对应的位置区域移动的步长。当strid=1时,就是上图的卷积操作。
2.3 Padding操作
在卷积过程中,有一些常见的问题:
- 每次卷积完矩阵都会缩小。
- 边缘的像素不受重视。
首先,只有当卷积核大小为1*1,且strid=1时,卷积后矩阵的大小不变。而1*1的卷积核通常用来升维或降维,或者是加入非线性的激励函数,增加网络的表达能力。并不能起到提特征的作用。
其次,再对一个矩阵完成全部的卷积操作时,边缘的值只会被计算到一次或几次,远少于中心的值被计算到的位置,中心的值往往被计算到的次数是卷积核的大小,例如3*3的卷积核,当原始的矩阵大小大于5*5时,中心的元素可以被计算3*3=9次,边角的元素只能被计算1~3次。
为了解决这个问题,引入了padding操作。就是将原始的矩阵四周填充上元素,这样使原始的矩阵变大,会使原始矩阵卷积后不再变小或者减小变小的速度,能够承受更多次的卷积。而且也会增加边缘元素被计算的次数,上面两个问题都被解决。一般来说,会在矩阵周围扩充0,这样卷积时对应位置相乘再相加,0不会对feature map造成影响。
same convolution就是使用padding操作,使卷积后的feature map大小不变,设卷积核大小为f*f,padding就在原始矩阵四周各扩充(f-1)/2,将原矩阵m*n维度扩充为[n+(f-1)/2]*[m+(f-1)/2]。
2.4 3-d convolution
上面所说的都是2维卷积,如果变成3维的卷积应该如何做?
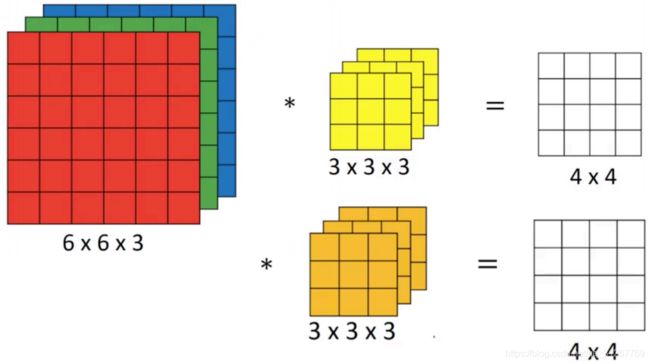
首先从2d到3d来说,原始矩阵再第三个维度上有了n个大小相同的矩阵。在图片识别领域往往第三个维度是channal通道数,比如RGB三个颜色通道。暂且对所有的3d张量的第三维都叫做通道。当做3d卷积时,前两维的大小设置还是和2d的一样,第三维的大小卷积核必须与原始矩阵相同,因为做卷积时要计算对应位置上的乘积并相加。
注意,一组卷积核对3d矩阵做3d卷积后得到的是一个2d feature map。因为是将多个channal的卷积后的值相加,最后得到的是2维。而多组卷积核对原始向量做卷积得到的feature map才是3维的。(或者理解为,一组卷积核对3d矩阵做3d卷积后得到的是一个3d feature map,但是channal数为1。多组卷积核得到的feature map的channal数为n)。
- 卷积核的channal数等于前一层矩阵的channal数
- 后一层的channal数等于卷积核的组数
- 每组卷积核的大小维度相同
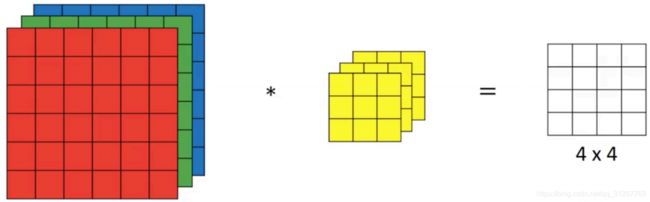
结合以上的padding、Strid、convolution、kernal组数,可以计算出每次对一个矩阵完成卷积后得到的feature map的大小,假设原矩阵n*m*c,kernal f*f*c,padding p,strid s,kernal组数g:
![[(\frac{n-f+2p}{s})+1]*[(\frac{m-f+2p}{s})+1]*g](http://img.e-com-net.com/image/info8/9fd97fd81a3a43b3a5c6baabf334174a.gif)
2.5 Pooling
pooling与卷积很相似,也是滑动一个窗口,然后在这个窗口上执行一个函数,只不过卷积的“函数”是给一个“权重”矩阵做线性组合。而pooling的“函数”与卷积不同,往往是对窗口内取均值或者取最大值。pooling作用于不重叠的部分,这里是与卷积的主要区别。也就是说strid的大小等于滑动窗口的大小。

pooling常见的操作是对窗口区域内取均值或者是最大值,将一个窗口内的特征用一个特征值代替,这样可以进一步缩小矩阵的大小。pooling层往往紧跟在卷积层后面。
pooling层的作用?
- 卷积层可以发现图片的局部特征,对图像的特征的提取,pooling层的作用是对特征的进一步提取和整合,得到新的特征
pooling层为什么可以起作用?
- 在卷积层中,由于窗口是重叠滑动,所以在卷积后的feature map中存在大量的冗余特征和无用特征,而这些特征对模型的效果没有很大帮助,并且会大大降低模型的训练速度。
- pooling层是对不同位置特征的聚合统计,对卷积后的特征进行了进一步的抽象,使得特征的密度更高,的确会损失一部分信息。
- pooling层与卷积层的本质区别是卷积层在提取特征时计算了静态或者动态的权重,也就是卷积核。而pooling没有计算任何额外的值,仅仅是提取了统计特征。
最后加一个关于卷积和池化很直觉的解释。假设对于一个手写识别的任务,去识别一个单通道图片,图片上有一个字母A。使用卷积层和pooling层多次叠加,无论是A写在图片的任意位置,或者形状有微小变化总是可以识别正确。卷积层在滑动窗口时有大量重叠,因此总是可以提出图片中有关A的全部特征,而pooling层对卷积后的feature map提取统计特征,会忽略图片中空白的部分,多次卷积和池化操作后,一定可以提取出A的全部特征。即使不同字体或者镂空,在完成卷积和池化后提取到的特征应该是相差不多的,因此总是可以成功识别。这也与pooling的平移不变性有关。
3 问题总结
- 卷积核的大小常为奇数。一是padding的原因,如果卷积核是奇数,就可以从图像的两边对称的padding。第二点是奇数的卷积核有中心点可以方便的确定位置。但是并不绝对,完全可以根据实际情况选取卷积核的size。
- 对于全连接神经网络来说,卷积的部分更像是一个提特征的部分,真正用于计算结果的还是全连接层。
- 卷积与互相关