六、软件实现深度学习河流训练样本数据的制作(软件操作完善训练样本)——针对标签图片问题的进一步完善
这里进行到最后发现了标签的一些问题
具体问题忘了的朋友可以戳这里进行回顾
欲哭无泪
今天开会与老师同学们讨论后
1、原图白色区域不能作为河流样本存在,也就是说对于DOM图片白色的区域标签得是黑色的背景
2、那些不完整的大型河流需要进行样本的补充,线画图没有画出来的需要人工进行补充
oh漏~~~~~~
真真是返工的节奏了
接下来这一篇将要总结一下如何进行样本补救
标签的tif文件有了
原图的tif文件有了
但是发现出现了错误
该怎么办???重做一次么???
康康我是怎么尝试解决的
感觉自己开了个坑
筛选对比原图
发现我的河流线画图并不完整

这个也是我需要的河流,但是他并没有用专门的河流线来表示,也就是说6221线型就专门表示河流池塘水系,但是由于前期画图人员的一些原因
竟然用地貌土质8521来表示了池塘,8521可以表示等高线等其他地貌
所以他竟然使用塘、鱼、鱼塘等标注来表示池塘。。。。
大无语了
这种标准由于前期没有跟我们之后的进行交流
就出现了问题。。。
我们并不知道原来这也是水系
所以造成了再一次的返工
再次欲哭无泪
补全漏掉的样本——使用CAD与Arcgis配合提取需要的面状池塘
那么如何把这种水系提取出来
经过我周末的深思熟虑
首先使用CAD把8521这一种类别的线画图dwg提取出来
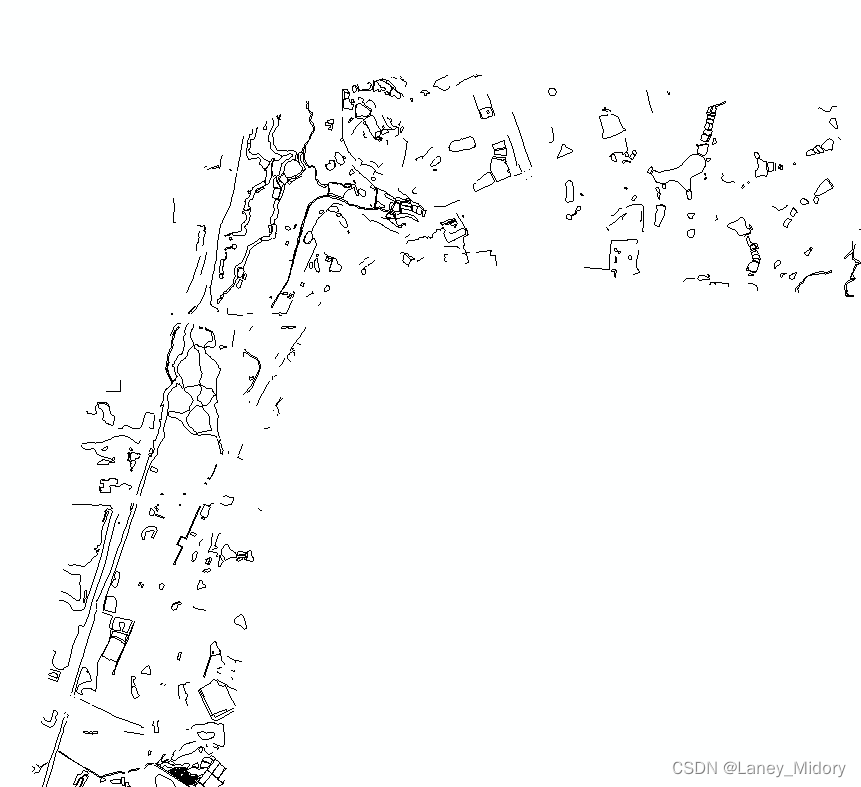
在arcgis里面打开是这样的
arcgis有一个好处就是他会直接把dwg保存为这几个类别
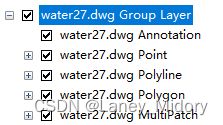
然后直接右键保存Polygon为shp文件
然后在进行筛选

保存成shp之后再倒入就直接已经是面状的了
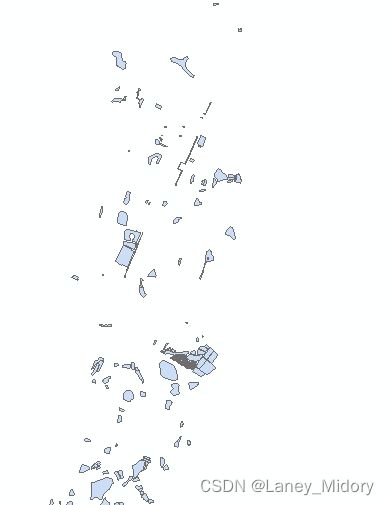
但里面并不全是我们需要的池塘
还需要对照标注进行筛选

这样就可以对照着进行筛选了
首先对标签的值进行筛选
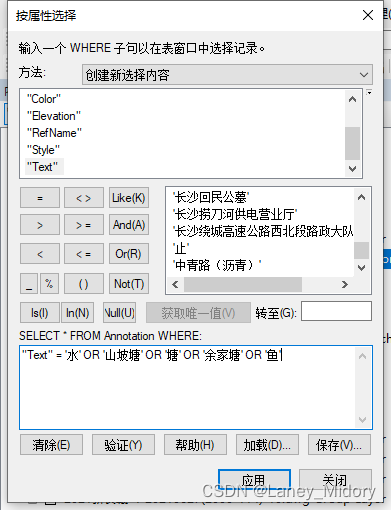
这样写会报错
要这样写

就可以筛选出我们需要的标注
在筛选时
对一些农田的定义还是不太准确
比如
这里标注的是池塘
原图是
不确定的要查看原图
对于一些封闭的线可以选择边界直接线转面
但对于一些没有封闭存在缺口的线
稍微复杂,我之前是一点点沿着线画
但摸索出来一个更简便的方法
未封闭的线如何封闭首尾端点线转面
比如下图这种情况

把dwg中的polyline单独保存成shp
因为arcgis无法直接对dwg进行编辑
这样就可以使用编辑端点的工具
双击首尾线段
有一个延续要素工具

这样就可以把端点连接到另一个端点

然后再线转面就可以得到封闭面啦
经过四天的艰苦奋斗
得到了比较完整的河流面状啦

接下来就是按照我之前的方法把样本图片做出来
不知道如何批量操作的朋友
请查看我之前的这篇博文
但在这之前让我们先研究一下如何使用代码完成下面的
由于原图的一些成像原因来修改标签
的问题
对原图中河流存在白色区域的样本进行背景化处理
问题:
河流原图存在大量的白色区域
那么对应标签应该就是黑色,而不应该是河流样本
否则会影响后续的训练
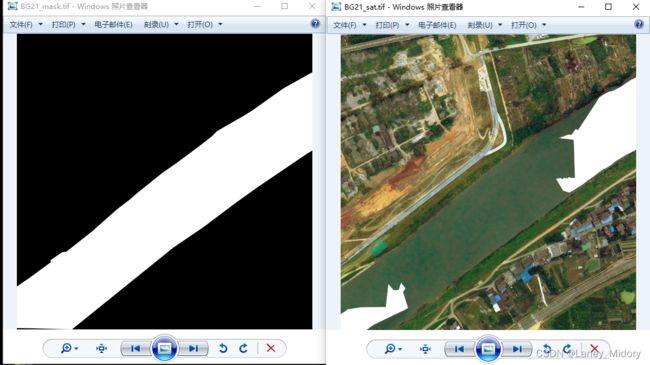
如图,原图为白色的区域
标签应该就为黑色
经过深思熟虑
我觉得这部分尝试使用代码完成
我尝试了这个博主的代码
简单易懂
这段代码总是报这样的错
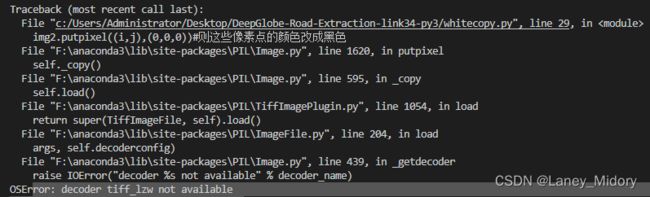
用这个方法可以解决
这个问题解决之后又报错

这就是tif图片的麻烦地方了
如果你是jpg格式应该就不会有这些问题
那我们来看看怎么解决
那么就在标签图片那里转换成RGB即可
这篇文章给了我解决的思路
img2 = img2.convert(‘RGB’)
最后输出的样本如图

最后我的代码如下
# -*- coding: utf-8 -*-
"""Created on Sat June 4 15:26:30 2022
@author:Laney_Midorycsdn:Laney_Midory
"""
from PIL import Image
i = 1
j = 1
img = Image.open("C:/Users/Administrator/Desktop/white/BF25_sat.tif")#读取系统的内照片
img2= Image.open("C:/Users/Administrator/Desktop/white/BF25_mask.tif")#读取系统的内照片
img2 = img2.convert('RGB')
width = img.size[0]#长度
height = img.size[1]#宽度
for i in range(0,width):#遍历所有长度的点
for j in range(0,height):#遍历所有宽度的点
data = (img.getpixel((i,j)))#打印该图片的所有点
#print (data)#打印每个像素点的颜色RGBA的值(r,g,b)
#print (data[0])#打印RGBA的r值
if (data[0]==255 and data[1]==255 and data[2]==255):
img2.putpixel((i,j),(0,0,0))#则这些像素点的颜色改成黑色
img2.save("C:/Users/Administrator/Desktop/new/BF25_mask.tif")
print("Finish!")
这样就需要重新把面状导出为我需要的标签和原图啦
按照我之前的博客设置出模型
运行起来特别快的得到了我需要的样本
但其实我还想改进这部分的代码
实现读取整个文件夹实现批量化的操作
筛选原图+需要修改的原图+批量修改对应标签的批量实现过程
这样再来总结一下整个流程
得到所有的样本文件后,我需要得到对应的原图
这一段筛选代码之前已经写过了
忘记了的朋友可以去查看我的这篇博文
然后就可以得到标签对应的原图
之后需要对原图存在白色区域的图片进行筛选
这一段代码没有写过
但是理论应该是相似的
如何把白色区域的图片挑选出来
最好还是人工选择吧
如果是判断存不存在白色像素块还是有些难
因为肯定是存在很多白色物体的
很容易出现误选的情况
这样判断标准不好确定
人工选择比较容易
选出来之后发现还挺多的
36张相片

那我还是批量处理吧
一张一张太累了
首先需要把这些原图对应的标签文件选出来
由于此时两者名字相同
所以得放在不同的文件夹里
这个可以直接用之前的代码移动就可以
就不说了就改成move即可

接下来就是我说的要批量修改的
直接放代码:
# -*- coding: utf-8 -*-
"""
Created on Monday June 6 23:30:57 2022
@author:Laney_Midorycsdn:Laney_Midory
"""
from PIL import Image
import os
pic_Path = r"C:\Users\Administrator\Desktop\white" # 用于获取文件名称列表
train_path = r"C:\Users\Administrator\Desktop\whitetrain" # 源文件夹
new_path = r"C:\Users\Administrator\Desktop\new" # 目标文件夹
pic_list = os.listdir(pic_Path)
# print(file_list)
train_list = os.listdir(train_path)
for file in pic_list:
i = 1
j = 1
img = Image.open(pic_Path+'\\'+file)#读取系统的内照片
img2= Image.open(train_path+'\\'+file)#读取系统的内照片
img2 = img2.convert('RGB')
width = img.size[0]#长度
height = img.size[1]#宽度
for i in range(0,width):#遍历所有长度的点
for j in range(0,height):#遍历所有宽度的点
data = (img.getpixel((i,j)))#打印该图片的所有点
#print (data)#打印每个像素点的颜色RGBA的值(r,g,b)
#print (data[0])#打印RGBA的r值
if (data[0]==255 and data[1]==255 and data[2]==255):
img2.putpixel((i,j),(0,0,0))#则这些像素点的颜色改成黑色
#img_array2[i, j] = (0, 0, 0)
#img = img.convert("RGB")#把图片强制转成RGB
#img2.save("e:/pic/testee1.jpg")#保存修改像素点后的图片
img2.save(new_path+'\\'+file)
print("Finish!")
print("Finish all pictures!")
结果图如下
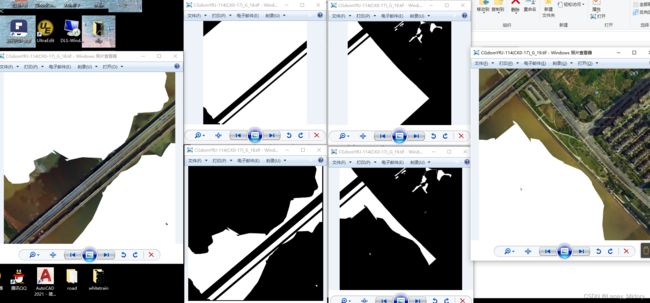 原图片是这样的
原图片是这样的

进行样本修改后是这样的

批量操作成功!!!
然后进行修改图片标签和原图的名字
然后放在同一个文件夹里

然后对其进行裁剪
裁剪成512*512的大小并移除裁剪之后全黑的标签
就完成样本的制作啦
就可以放进网络进行训练