Uformer: A General U-Shaped Transformer for Image Restoration阅读笔记
Abstract
构建一个分层的编码-解码器,并使用Transformer block进行图像恢复。
Uformer两个核心设计:1. local-enhanced window Transformer block(使用非重叠窗口自注意力降低计算量,并在feed-forword network上使用depth-wise convolution增强捕获局部上下文的能力)2.探索三种跳跃连接方案。
1 Introduction
self-attention在获取局部依赖方面有局限性,所以在transformer block中的feed-forward network中,两个全连接层中插入一个depth-wise convolutional layer,以更好的捕获local context。
在跳跃连接中,此外,我们将从编码器向解码器传递信息的问题公式化为自我注意计算的过程:解码器中的特征扮演queries,并寻找估计它们与编码器中扮演keys和values角色特征的关系。
去噪、去雨、去模糊、去摩尔纹取得了较好的结果。
2 Related Work
Image restoration architectures
分级捕获多尺度信息的U-Net结构多用于图像恢复任务。
Vision Transformer
3 Method
3.1 Overall Pipeline
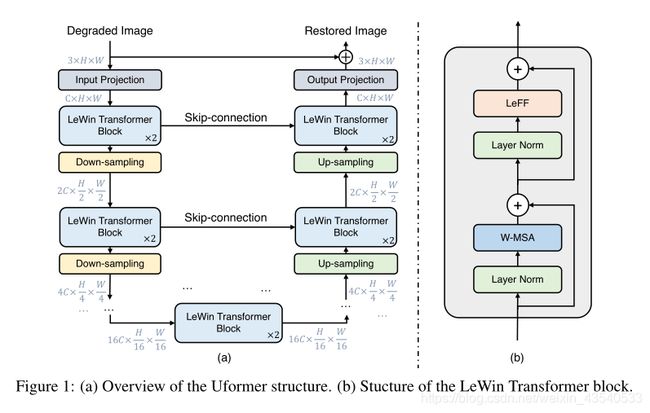
- 输入degraded image I ∈ R 3 × H × W I \in R^{3\times H\times W} I∈R3×H×W,Uformer首先用 3 × 3 3\times3 3×3的带有LeakyReLU的卷积层提取低级特征,得到 X 0 ∈ R C × H × W X_0 \in R^{C\times H\times W} X0∈RC×H×W
- 按照U-shaped structures将特征图 X 0 X_0 X0通过K个encoder stages,每个stage都包括一堆LeWin Transformer blocks和一个下采样层。
LeWin Transformer block利用自注意力机制捕获Long-range dependencies,同时使用不重叠的窗口计算注意力降低成本。在下采样层中,首先对展平后的features reshape成二维空间的feature maps,然后对齐下采样,再使用 4 × 4 4\times4 4×4,补偿为2的卷积操作将通道加倍。
- 例如,给定输入特征图 X 0 ∈ R C × H × W X_0 \in R^{C\times H\times W} X0∈RC×H×W ,第 l l l个stage的编码器输出特征图为 X l ∈ R 2 l C × H 2 l × W 2 l X_l \in R^{2^l C\times {\frac H {2^l}} \times {\frac W {2^l}}} Xl∈R2lC×2lH×2lW
编码器末端添加一堆 LeWin Transformer blocks组成的bottleneck
对于特征重建,共有K个stage,每个stage包括一个上采样层和一堆与编码器相似的LeWin Transformer blocks。使用步长为2的 2 × 2 2\times2 2×2转置卷积进行上采样,采样后,特征图的通道减少一半,尺寸增大一倍。然后将上采样后的特征和通过跳跃连接来自编码器的特征输入到LeWin Transformer模块。利用LeWin Transformer学生西恢复图像,经过K个解码器stage后,将展平的特征reshape成2D特征图,再通过一个 3 × 3 3\times3 3×3的卷积层获得残差图像 R ∈ R 3 × H × W R\in R^{3\times H\times W} R∈R3×H×W ,最后重建图像通过 I ′ = I + R I' = I + R I′=I+R 得到。
实验中,通过经验设置 K = 4 K=4 K=4并且每个stage包括两个LeWin Transformer blocks。
使用Charbonnier loss训练Uformer:
l ( I ′ , I ^ ) = ∣ ∣ I ′ − I ^ ∣ ∣ 2 + ϵ 2 l(I', \hat I) = \sqrt {||I'-\hat I||^2 +\epsilon^2} l(I′,I^)=∣∣I′−I^∣∣2+ϵ2
I ^ \hat I I^是真实图像, ϵ = 1 0 − 3 \epsilon = 10^{-3} ϵ=10−3 是一个实验常数。
3.2 LeWin Transformer Block
Transformer用于图像恢复的两个问题,计算量大,对局部信息捕获有局限性。从而提出一个locally-enhanced window(LeWin)Transformer block。
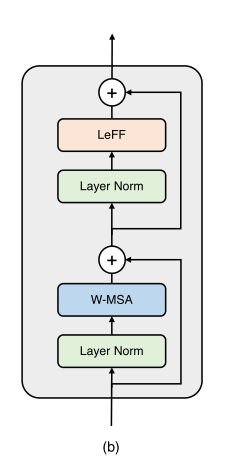
具体来说,给定第 l − 1 l-1 l−1个block的特征 X L − 1 X_{L-1} XL−1 ,通过两个核心设计来构建block,(1)基于多头注意力的非重叠窗口(W-MSA)(2)局部增强的前馈网络(LeFF),表示如下:
X l ′ = W M S A ( L N ( X l − 1 ) ) + X l − 1 X'_l=WMSA(LN(X_{l-1}))+X_{l-1} Xl′=WMSA(LN(Xl−1))+Xl−1
X l = L e F F ( L N ( X l ′ ) ) + X l ′ X_l = LeFF(LN(X'_l))+X'_l Xl=LeFF(LN(Xl′))+Xl′
Window-based Multi-head Self-Attention(W-MSA)
给定2D特征图 X ∈ R C × H × W X\in R^{C\times H\times W} X∈RC×H×W,将其分割成窗口大小为 M × M M\times M M×M不重叠的窗口,然后从每个窗口 i i i中获得展平和转置的特征图 X i ∈ R M 2 × C X^i \in R^{M^2\times C} Xi∈RM2×C ,然后对每个窗口中展平后的特征执行自注意力,假设多头数为 k k k ,头的维度为 d k = C k d_k = \frac C k dk=kC ,那么计算非重叠窗口中的第k个头部自我注意可以定义为:
X = { X 1 , X 2 , . . . , X N } , N = H W / M 2 X=\{X^1, X^2, ..., X^N\}, N=HW/M^2 X={X1,X2,...,XN},N=HW/M2
Y k i = A t t e n t i o n ( X i W k Q , X i W k K , X i W k V ) , i = 1 , … … , N , Y_k^i = Attention(X^i W_k^Q, X^i W_k^K , X^i W_k^V), i = 1, ……, N, Yki=Attention(XiWkQ,XiWkK,XiWkV),i=1,……,N,
X ^ k = { Y k 1 , Y k 2 , … , Y k M } \hat X_k = \{Y^1_k ,Y^2_k, …,Y^M_k\} X^k={Yk1,Yk2,…,YkM}
W k Q , W k K , W k V ∈ R C × d k W^Q_k, W^K_k, W^V_k \in R^{C\times d_k} WkQ,WkK,WkV∈RC×dk分别表示第k个头的queries,keys和values矩阵。 X ^ k \hat X_k X^k是第k个头的输出。
所有头 { 1 , 2 , … , k } \{1,2,…,k\} {1,2,…,k}的输出concatenated在一起,最后通过线性投影得到最后的结果。同时将相对位置编码(relative position encoding)应用于注意力模块,计算表示为:
A t t e n t i o n ( Q , K , V ) = S o f t M a x ( Q K T d k + B ) V Attention(Q,K,V)=SoftMax(\frac {QK^T} {\sqrt d_k}+B)V Attention(Q,K,V)=SoftMax(dkQKT+B)V
B B B是相对位置偏差,取自可学习变量 B ^ ∈ R ( 2 m − 1 ) × ( 2 M − 1 ) \hat B \in R^{(2m-1)\times(2M-1)} B^∈R(2m−1)×(2M−1).
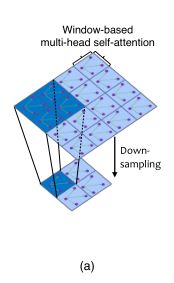
Windows-based self-attention可以显著降低计算量,例如给定特征图 X ∈ R C × H × W X\in R^{C\times H\times W} X∈RC×H×W 计算复杂度从 O ( H 2 W 2 C ) O(H^2 W^2 C) O(H2W2C)降低至 O ( H W M 2 M 4 C ) = O ( M 2 H W C ) O(\frac {HW} {M^2} M^4 C) = O(M^2 HWC) O(M2HWM4C)=O(M2HWC) ,由于将Uformer设计为分层架构,在每个stage的偶数LeWin Transformer block上使用Shifted-window strategy。
Locally-enhanced Feed-Forward Network(LeFF)
标准Transformer中的前馈网络FFN在提取local context上能力有限,然而相邻像素是图像恢复的重要参考,为克服这个问题添加一个depth-wise convolutional block到FFN上。
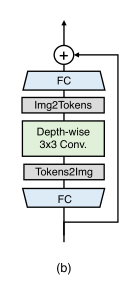
首先使用一个线性投影层,增加特征尺寸,接着将tokens reshape成2Dfeatures,然后使用 3 × 3 3\times 3 3×3的depth-wise convolution 捕获local信息,然后展平特征特征成tokens,再通过一个线性投影层,来匹配输入通道的维度。我们使用GeLU为每个线性层、卷积层之后的激活函数。
3.3 Variants of Skip-Connection
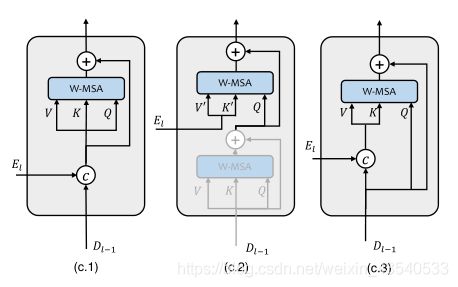
Concatenation-based Skip-connection(Concat-Skip)
如图C.1,将第 l l l个stage编码器的展平特征 E l E_l El 和第 l − 1 l-1 l−1个stage解码器的特征 D l − 1 D_{l-1} Dl−1连接,然后将concatenated后的特征融入第一个LeWin Transformer模块的W-MSA组件。
Cross-attention as Skip-connection(Cross-Skip)
根据language Transformer模型中解码器架构,设计Cross-Skip。首先,在每个编码器stage中的第一个LeWin Transformer block中添加一个额外的注意力模块,该块中的第一个自注意力模块(阴影模块)用于从解码器特征 D l − 1 D_{l-1} Dl−1中逐像素地寻找自相似性。该block的第二个自注意力模块将编码器的特征 E l E_l El作为keys和values,然后用第一个模块的特征作为queries。
Concatenation-based Cross-attention as Skip-connection(ConcatCross-Skip)
将编码器的特征 E l E_l El和解码器的特征 D l − 1 D_{l-1} Dl−1concatenate起来作为keys和values,queries仅来自解码器。
4 Experiments
4.1 Experimental Setup
Settings 遵循Transformer的通用训练策略
使用AdamW优化器,momentum terms of (0.9, 0.999),衰减权重为0.02。水平翻转随机增加样本,并将图像旋转90,180,270度。使用余弦衰减策略将学习率降低到 1 e − 6 1e{-6} 1e−6, 初试学习率为 2 e − 4 2e{-4} 2e−4,设置LeWin Transformer block中的window尺寸为 8 × 8 8\times8 8×8。更多实验数据在补充材料中可以找到。
其余略。
5 Conclusions
略