mahout算法源码分析之Collaborative Filtering with ALS-WR 并行思路
Mahout版本:0.7,hadoop版本:1.0.4,jdk:1.7.0_25 64bit。
mahout算法源码分析之Collaborative Filtering with ALS-WR 这个算法的并行主要就应该是ParallelALSFactorizationJob这里的并行了,下图是这个Job的大部分操作:
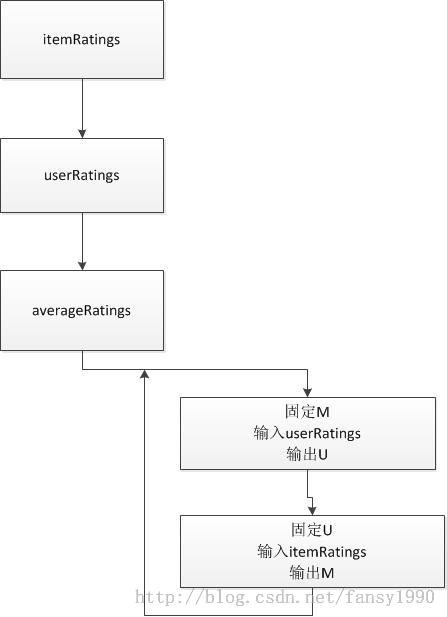
这里分析并行就是看每个job任务是否可以出现多个map或者reduce即可。
(1)首先分析前面三个itemRatings,对应的输入是原始文件,如果原始文件很大的话,那么这个任务可以建立多个mapper和reducer;这个是没有问题的;
(2)第二个userRatings,这个输入是前面itemRatings的输出,如果前面的输出太大的话,那么这个userRatings的输入mapper个数也可以多个;
(3)第三个averageRatings,这个输入同样是前面的itemRatings的输出,那么分析就和userRatings一样了,同样可以并行;
(4)其实最主要的就是这个for循环了,如果这个可以并行,那么就全部都可以并行了。看到这里的itemRatings输入,所以for循环里面的第二个job不用考虑是否可以并行了,肯定是可以了。那么第一个userRatings呢?当然如果userRatings输出数据很多的话,那么这个job同样是可以并行化的。所以当数据很大的时候就会产生多个mapper(默认64M一个mapper),那么就可以并行了。但是这里有个问题,就是当数据很大的时候,其中的U和M不会很大么,这两个是要放入内存的,太大的话肯定是会影响程序运行效率的。那么就拿movie数据来对比分析下:原始数据的trainingSet是9.92M,得到的itemRatings是8.67M,得到的userRatings是7.92M,得到的M矩阵是633K,得到的U矩阵是1.01M。所以对于U矩阵来说当原始数据比较大的时候,这个矩阵也是比较大的,放入内存中也不是很适合,同时这里的numFeature设置为20,如果这个参数设置为50的话,那么U和M就会更大,这个要是要考虑的。mahout官网上说这个算法由于含有循环,所以性能不够好。
其实这里还有一个比较简单的方法来测试for循环阶段建立多个mapper,建立下面的代码:
package mahout.fansy.als.test;
import mahout.fansy.als.ParallelALSFactorizationJobFollow;
public class TestParallelALSFactorizationJobFollow {
/**
* 测试ParallelALSFactorizationJobFollow
* 看是否在for循环里面得到两个mapper?
* @throws Exception
*/
public static void main(String[] args) throws Exception {
String[] arg=new String[]{"-jt","ubuntu:9001","-fs","ubuntu:9000",
"-i","hdfs://ubuntu:9000/test/input/user_item",
"-o","hdfs://ubuntu:9000/test2/output",
"--lambda","0.065","--numFeatures","3","--numIterations","3",
"--tempDir","hdfs://ubuntu:9000/test2/temp"
};
ParallelALSFactorizationJobFollow.main(arg);
}
}
同时,把hadoop集群的hadoop-core-1.0.4.jar 更新下,使用 http://download.csdn.net/detail/fansy1990/6375301这里的类进行如下更新:
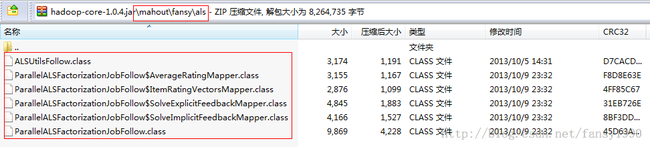
注意路径,这个自己新建即可。
然后直接运行上面的测试程序,就可以在50030界面看到两个mapper的job了,如下:
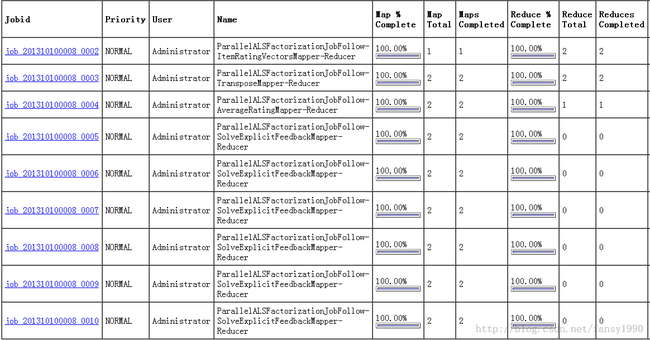
总体来说,这个算法的性能应该不如itembased collaborative filtering 算法,所以,下个mahout算法源码分析系列就分析 itembased collaborative filtering。
分享,成长,快乐
转载请注明blog地址:http://blog.csdn.net/fansy1990