机器学习系列 【二】感知机算法
@TOC
参考博客:https://blog.csdn.net/qq_16137569/article/details/81780195
内容说明
本篇文章主要介绍感知机算法的基本原理、优化求解方法以及python代码实现。写作目的在于帮助读者理解感知机算法的原理,也使得自己可以牢记感知机算法的相关内容。
一、感知机算法的基本原理
感知机是二分类的线性分类模型,其输入为实例的特征向量,输出为实例的类别,分别取+1+1和−1−1二值。感知机对应于输入空间(特征空间)中将实例划分为正负两类的分离超平面,属于判别模型。这还是很容易理解的,以二维平面为例,假设平面中存在着“O”和"X"两种形状的点,感知机要做的是就是找到一条直线,将两类点分割开,如下图所示。这里要注意的是,感知机只适合于线性可分的数据,所以它是一个线性模型。
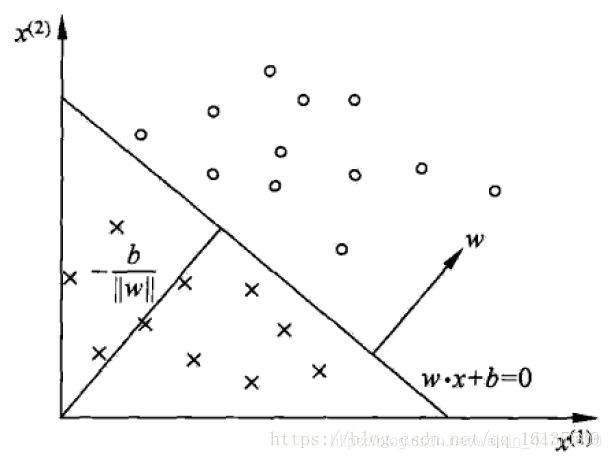
假设现在我们训练集有m个样本,每个样本对应于n维特征和一个二元类别输出:
![]()
我们现在的目标就是找到一个超平面S(为了表达简洁,后面都用向量形式了): w ⋅ x + b = 0 w ⋅ x + b = 0 w⋅x+b=0
其中w是超平面的法向量,b是超平面的截距,这个超平面将特征空间划分为两个部分:
对于 y ( i ) = − 1 y^(i)=-1 y(i)=−1的样本, w ⋅ x ( i ) + b < 0 ; w ⋅x^(i)+b<0; w⋅x(i)+b<0;
对于 y ( i ) = + 1 y^(i)=+1 y(i)=+1的样本, w ⋅ x ( i ) + b > 0 ; w ⋅x^(i)+b>0; w⋅x(i)+b>0;
从而实现分类的目的。这就是感知机模型,可以表示为从输入空间到输出空间的函数: f ( x ) = s i g n ( w ⋅ x + b ) f(x )=sign(w ⋅ x + b) f(x)=sign(w⋅x+b)其中权值 w ∈ R n 和 偏 置 b ∈ R 是 感 知 机 模 型 参 数 , 比 如 在 二 维 平 面 中 , w w\in R^n和偏置b\in R是感知机模型参数,比如在二维平面中,w w∈Rn和偏置b∈R是感知机模型参数,比如在二维平面中,w就是一个二维向量。 s i g n ( x ) sign(x) sign(x)是符号函数,即 s i g n ( x ) = { + 1 , x ≥ 0 − 1 , x ≤ 0 sign(x)=\begin{cases} +1,x\geq0 \\ -1, x\leq0 \end{cases} sign(x)={+1,x≥0−1,x≤0一旦学习到了w和b的值,我们就可以利用f(x(i))来判断新的样本属于哪一类别。
二、感知机算法的优化求解方法
1 感知机算法损失函数定义
感知机学习的目标是求得一个能够将训练集正类和负类样本点完全正确分开的分离超平面。为了确定超平面的参数 w 和 b w和b w和b,我们需要定义损失函数并将损失函数最小化。
我们自然而然能想到的一个选择是最小化误分类点的总数,即0−1损失,但这样的损失函数不是参数 w , b w,b w,b的连续可导函数,难以优化。另一个选择是最小化误分类点到超平面S的总距离,这正是感知机所采用的。
先回顾一下空间任一点 x i x^i xi到平面w⋅x+b的距离公式: ∣ w ⋅ x i + b ∣ ∣ ∣ w ∣ ∣ \frac{|w⋅x^i +b|}{||w||} ∣∣w∣∣∣w⋅xi+b∣然后对于误分类的数据点 ( x i , y i ) , 总 是 满 足 y i f ( x i ) < 0 (x^i,y^i),总是满足y^if(x^i)<0 (xi,yi),总是满足yif(xi)<0,所以误分类点到超平面S的距离为: − y i ( w ⋅ x i + b ) ∣ ∣ w ∣ ∣ \frac{-y^i(w⋅x^i +b)}{||w||} ∣∣w∣∣−yi(w⋅xi+b)记误分类点的集合为 M M M,那么所有误分类点到超平面S的总距离为:
 由于我们总能通过缩放 w , b w,b w,b使得在不改变超平面的的情况下使 ∥ w ∥ 2 = 1 ∥w∥2=1 ∥w∥2=1,为了简化损失函数,我们不妨令∥w∥2=1,于是得到了感知机的损失函数最终形式如下:
由于我们总能通过缩放 w , b w,b w,b使得在不改变超平面的的情况下使 ∥ w ∥ 2 = 1 ∥w∥2=1 ∥w∥2=1,为了简化损失函数,我们不妨令∥w∥2=1,于是得到了感知机的损失函数最终形式如下:

这个损失函数就是感知机学习的经验风险函数,显然L(w,b)L(w,b)是非负的,如果没有误分类点,损失函数值为0。误分类点越少,误分类点距离超平面越近,损失函数值就越小。
最后一句话总结,感知机学习的策略是在假设空间中选取使损失函数式(1)最小的模型参数w,bw,b,即感知机模型。
2 感知机优化求解方法
感知机学习问题就是上述损失函数式的最优化问题,可以用随机梯度下降求解。下面介绍一下感知机学习算法的求解过程:
给定训练集T,感知机学习的目标是:

其中M是训练集中误分类点的集合。感知机学习算法是误分类驱动的,具体采用SGD,首先随机选取一个超平面 w 0 , b 0 w0,b0 w0,b0,然后每次随机选取一个误分类点进行梯度下降。
损失函数的梯度为:

其中 η η η为学习率。整个过程直观的解释是,每次遇到误分类点就调整 w , b w,b w,b,使超平面向误分类点的一侧移动,以减小改误分类点与超平面间的距离,直到超平面越过该点使其被正确分类。感知机学习算法存在许多解,这不仅依赖于 w , b w,b w,b初始值的选择,也依赖于误分类点的选择顺序。为了得到唯一的超平面,需要对分离超平面增加约束条件,这就是线性支持向量机的思想。
最后提一下感知机的两点性质:
(1) 当数据集线性可分的时候,学习算法一定收敛,即可以找到一个将数据点完全正确分开的超平面,而且误分类的次数是有上界的,即经过有限次的搜索一定可以找到最优分离超平面;
(2) 当数据集不是线性可分的时候,学习算法不收敛,可能会发生震荡。
三、感知机算法的代码实现
本文使用python代码手写感知机算法,仅调用numpy库以及panda库。代码示例如下:
import numpy as np
import pandas as pd
class Percpetion():
def __init__(self):
self.rate = 0.1
self.iterations = 100
self.labels = []
self.feats = []
self.weight = 0
self.b = 0
def load_dataset(self):
data = pd.read_csv("D:\hwProject\data\data1.csv", header=None)
return data
def initialize(self, para_num):
self.weight = np.ones((para_num, 1))
self.b = 0
def train(self):
train_data = self.load_dataset()
self.feats = train_data.iloc[:, :2].values
self.labels = train_data.iloc[:, 2].values
self.initialize(len(self.feats[0]))
for i in range(self.iterations):
pred = np.dot(self.feats, self.weight) + self.b
result = (pred.reshape(len(self.labels), 1)) * (self.labels.reshape(len(self.labels), 1))
num_fault = len(np.where(result <= 0)[0])
pred1 = np.sign(pred)
pred1 = pred1.reshape(100,)
print("第%d次更新,错分类样本数为:%d" % (i, num_fault))
if num_fault == 0:
break
else:
t = np.where(pred1 != self.labels)[0][0]
print(t)
self.weight = self.weight + self.rate * self.labels[t] * (self.feats[t].reshape(len(self.feats[0]), 1))
self.b = self.b + self.rate * self.labels[t]
if __name__ =="__main__":
train_file = "D:/hwProject/data"
test_file = "/data/test_data.txt"
predict_file = "/projects/student/result.txt"
pc = Percpetion()
pc.train()