Social Bots数据集总结
目录
数据集对比:
1 pronbots-2019
2 varol-icwsm
3 cresci-17
4 caverlee
5 gilani-17
6 midterm-18
7 cresci-rtbust-2019
数据集对比:
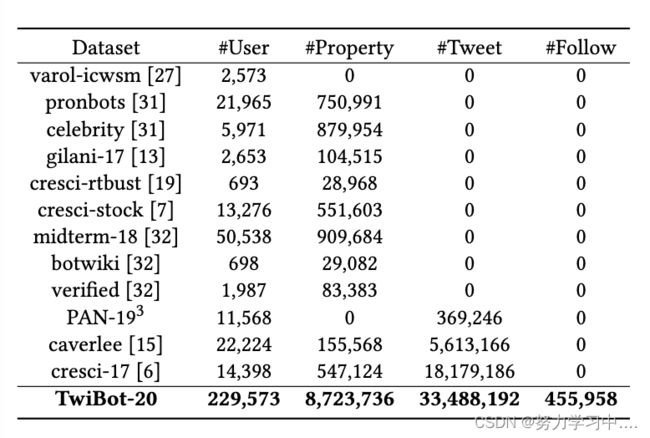
不同机器人检测基准的统计,从左到右,每个数据集中的用户数、用户属性项数、总推文数和关注关系数。
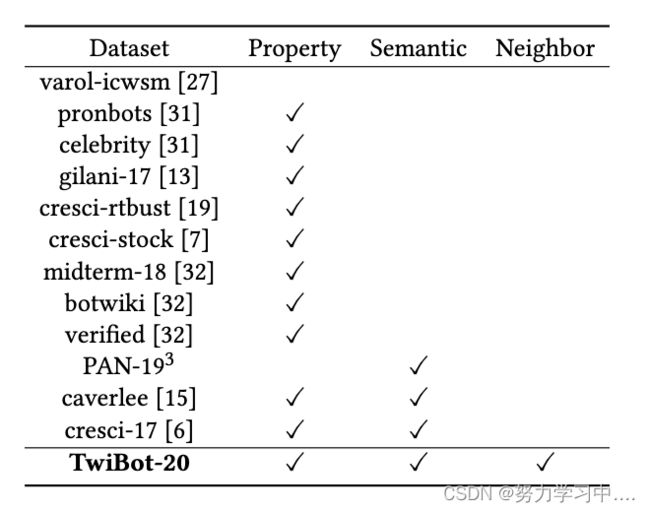
每个机器人检测数据集包含的用户信息模式,语义、属性和邻域信息。
1 pronbots-2019
源自论文:Yang, Kai‐Cheng, Onur Varol, Clayton A. Davis, Emilio Ferrara, Alessandro Flammini, and Filippo Menczer. "Arming the public with artificial intelligence to counter social bots." Human Behavior and Emerging Technologies 1, no. 1 (2019): 48-61.
论文获取链接:https://onlinelibrary.wiley.com/doi/pdfdirect/10.1002/hbe2.115?casa_token=n9uKpZEJPAQAAAAA:Q0IX1Ecana0B4p2l4d8jCCUdPRXUobtAS5h69GW4KZY4taLbkn6dMGV4SqB5UEXEOtT9wYFh0mbH https://onlinelibrary.wiley.com/doi/pdfdirect/10.1002/hbe2.115?casa_token=n9uKpZEJPAQAAAAA:Q0IX1Ecana0B4p2l4d8jCCUdPRXUobtAS5h69GW4KZY4taLbkn6dMGV4SqB5UEXEOtT9wYFh0mbH摘要:伴随着社交媒体在我们日常生活中重要性的增加,操纵在线对话和意见的努力也随之而来。欺骗性的社交机器人--旨在冒充人类的自动或半自动账户--已被成功滥用。研究人员已经通过开发人工智能(AI)工具来应对,以武装公众对抗社交机器人。这里我们回顾了关于不同类型的机器人、它们的影响和检测方法的文献。我们用印第安纳大学开发的流行的机器人检测工具Botometer的案例研究,来说明人们如何用人工智能对策互动。一项用户体验调查表明,对许多用户来说,机器人检测已经成为社交媒体体验的一个组成部分。然而,解释人工智能工具输出的障碍会导致根本性的误解。开发复杂的机器人的机器学习方法和有效的反制措施之间的军备竞赛使得有必要更新检测工具的训练数据和功能。我们再次使用Botometer案例来说明机器人分数的算法和可解释性的改进,旨在满足用户的期望。最后,我们讨论了未来人工智能的发展会如何影响恶意机器人和公众之间的斗争。
https://onlinelibrary.wiley.com/doi/pdfdirect/10.1002/hbe2.115?casa_token=n9uKpZEJPAQAAAAA:Q0IX1Ecana0B4p2l4d8jCCUdPRXUobtAS5h69GW4KZY4taLbkn6dMGV4SqB5UEXEOtT9wYFh0mbH摘要:伴随着社交媒体在我们日常生活中重要性的增加,操纵在线对话和意见的努力也随之而来。欺骗性的社交机器人--旨在冒充人类的自动或半自动账户--已被成功滥用。研究人员已经通过开发人工智能(AI)工具来应对,以武装公众对抗社交机器人。这里我们回顾了关于不同类型的机器人、它们的影响和检测方法的文献。我们用印第安纳大学开发的流行的机器人检测工具Botometer的案例研究,来说明人们如何用人工智能对策互动。一项用户体验调查表明,对许多用户来说,机器人检测已经成为社交媒体体验的一个组成部分。然而,解释人工智能工具输出的障碍会导致根本性的误解。开发复杂的机器人的机器学习方法和有效的反制措施之间的军备竞赛使得有必要更新检测工具的训练数据和功能。我们再次使用Botometer案例来说明机器人分数的算法和可解释性的改进,旨在满足用户的期望。最后,我们讨论了未来人工智能的发展会如何影响恶意机器人和公众之间的斗争。
pronbots 数据集仅包含 Twitter 机器人,其中机器人检测被视为异常值检测任务。
该数据集首先由Andy Patel(github.com/r0zetta/pronbot2)分享,然后收集用于研究(Yang et al. 2019)。
数据集展示:
[{"created_at": "Sat Mar 03 10:38:12 +0000 2018",
"user":
{"follow_request_sent": false,
"has_extended_profile": false,
"profile_use_background_image": true,
"default_profile_image": false, "id": 86166567,
"profile_background_image_url_https": "https://abs.twimg.com/images/themes/theme5/bg.gif",
"verified": false,
"translator_type": "none",
"profile_text_color": "3E4415",
"profile_image_url_https": "https://pbs.twimg.com/profile_images/967640193619644416/XDr_j8X4_normal.jpg",
"profile_sidebar_fill_color": "99CC33",
"entities":
{"description":
{"URLs":
[{"url": "https://t.co/FmXiY0uJlh",
"indices": [43, 66],
"expanded_url": "http://qo2url.info/greenhomunculus3aC8",
"display_url": "qo2url.info/greenhomunculu\u2026"}]}},
"followers_count": 42,
"profile_sidebar_border_color": "829D5E",
"id_str": "86166567",
"profile_background_color": "352726",
"listed_count": 0,
"is_translation_enabled": false,
"utc_offset": null,
"statuses_count": 101,
"description": "Candy girl. Dance \\ Dogs lover. Come to me https://t.co/FmXiY0uJlh",
"friends_count": 240,
"location": "",
"profile_link_color": "D02B55",
"profile_image_url": "http://pbs.twimg.com/profile_images/967640193619644416/XDr_j8X4_normal.jpg",
"following": false,
"geo_enabled": false,
"profile_banner_url": "https://pbs.twimg.com/profile_banners/86166567/1519538390",
"profile_background_image_url": "http://abs.twimg.com/images/themes/theme5/bg.gif",
"screen_name": "greenhomunculus",
"lang": "en",
"profile_background_tile": false,
"favourites_count": 515,
"name": "Kathy Carrington",
"notifications": false,
"url": null,
"created_at": "Thu Oct 29 21:29:14 +0000 2009",
"contributors_enabled": false,
"time_zone": null,
"protected": false,
"default_profile": false,
"is_translator": false}}2 varol-icwsm
源自论文:Varol, Onur, Emilio Ferrara, Clayton A. Davis, Filippo Menczer, and Alessandro Flammini. "Online Human-Bot Interactions: Detection, Estimation, and Characterization." ICWSM (2017)
论文链接:
https://shimo.im/files/473QyrwgrmTgj73w/ 「14871-Article Text-18390-1-2-20201228.pdf」,可复制链接后用石墨文档 App 或小程序打开
论文摘要:越来越多的证据表明,越来越多的社交媒体内容是由被称为社交机器人的自主实体产生的。在这项工作中,我们提出了一个框架来检测Twitter上的这类实体。我们利用了从公共数据和用户元数据中提取的超过十种特征:朋友、推文内容和情绪、网络模式和活动时间序列。我们通过使用一个公开的Twitter机器人数据集来衡量分类框架。这个训练数据由人工标注的活跃的Twitter用户集合来充实,其中包括人类和不同复杂程度的机器人。我们的模型产生了很高的一致性,并且可以检测出不同性质的机器人。我们的估计表明,9%到15%的活跃Twitter账户是机器人。在描述账户之间的联系时,我们观察到简单的机器人倾向于与表现出更多类似人类行为的机器人互动。对内容流的分析揭示了机器人为与不同目标群体互动而采取的转发和提及策略。使用聚类分析,我们描述了账户的几个子类,包括垃圾邮件发送者、自我宣传者和从连接的应用程序发布内容的账户。
作者手动标记了从不同 Botometer 分数采样的帐户(Varol et al. 2017)。该数据集被设计为代表不同类型的账户。
该数据集包含 2573 个 Twitter 帐户的注释。 2016年4月完成注释和数据爬取。
varolicwsm 被认为不包含用户信息的任何方面,因为它只是被认为是机器人或人类的用户 ID 列表.
数据集下载下来无法打开。
3 cresci-17
源自论文:Cresci, S., Di Pietro, R., Petrocchi, M., Spognardi, A., & Tesconi, M. (2017, April). The paradigm-shift of social spambots: Evidence, theories, and tools for the arms race. In Proceedings of the 26th International Conference on World Wide Web Companion (pp. 963-972). ACM
Cresci, S., Di Pietro, R., Petrocchi, M., Spognardi, A., & Tesconi, M. (2017). Social Fingerprinting: detection of spambot groups through DNA-inspired behavioral modeling. IEEE Transactions on Dependable and Secure Computing
论文链接:The Paradigm-Shift of Social Spambots | Proceedings of the 26th International Conference on World Wide Web Companionhttps://dl.acm.org/doi/pdf/10.1145/3041021.3055135?casa_token=46GZ6JBBDo0AAAAA:ZiRm7iBeO4Cc62rUqEuIeytKmg0O8ih18QU0zFrkUgTLbemr-ILhS27p_0UueUT05kPjQCwMsEghttps://arxiv.org/pdf/1703.04482.pdfhttps://arxiv.org/pdf/1703.04482.pdf
摘要:最近对社会媒体垃圾邮件和自动化的研究提供了新一代垃圾邮件,即所谓的社会垃圾邮件的崛起的轶事。在这里,我们第一次广泛地研究了Twitter上的这种新现象,并提供了量化的证据,证明垃圾邮件的设计出现了范式的转变。首先,我们测量了当前Twitter检测新的社交机器人的能力。随后,我们评估了人类在区分真实账户、社交垃圾邮件和传统垃圾邮件方面的表现。然后,我们对学术文献中提出的几种最先进的技术进行了比较。结果显示,无论是Twitter、人类还是最先进的应用,目前都无法准确地检测出新的社交垃圾机器人。我们的结果呼吁采取新的方法,以扭转与这一现象作斗争的趋势。最后,我们回顾了关于垃圾邮件检测的最新文献,并强调了一个基于集体行为分析的新兴的共同研究趋势。从我们广泛的实验活动和调查中得出的见解阐明了最有希望的研究方向,并为对抗新型社会垃圾机器人的军备竞赛奠定了基础。最后,为了促进对这种新现象的研究,我们向科学界公开提供了本研究中使用的所有数据集。
摘要:在线社交网络中的垃圾邮件检测是一个长期的挑战,涉及到研究和设计能够有效识别不断演变的垃圾邮件的检测技术。最近,出现了新一轮的社会垃圾机器人,它们具有类似人类的先进特性,甚至可以不被当前最先进的算法所发现。在本文中,我们表明有效的垃圾邮件检测可以通过对其集体行为的深入分析来实现,利用数字DNA技术对社交网络用户的行为进行建模。受其生物对应物的启发,在数字DNA表示中,一个数字账户的行为寿命被编码为一串字符。然后,我们为这种数字DNA序列定义了一个相似性测量。我们以数字DNA和用户群之间的相似性为基础,来描述真实账户和垃圾邮件的特征。利用这种特征,我们设计了社会指纹技术,它能够在监督和非监督的情况下区分垃圾邮件和真实账户。我们最终评估了社交指纹技术的有效性,并将其与三种最先进的检测算法进行比较。我们的方法的特点之一是可以应用现成的DNA分析技术来研究在线用户的行为,并有效地依赖于有限的轻量级账户特征。
一个由CrowdFlower贡献者注释的(i)真正的、(ii)传统的和(iii)社会性的垃圾邮件Twitter账户的数据集。以CSV格式发布。
cresci-17 数据集中的机器人帐户包含更细粒度的分类:传统垃圾邮件机器人、社交垃圾邮件机器人和虚假关注者。传统的垃圾邮件机器人是重复发布相同内容的简单机器人。社交垃圾邮件程序模仿普通用户的个人资料和行为,因此在单独检查时不会怀疑它们。但作者发现他们以协调的方式推广某些主题标签或内容。假关注者是为获得关注账户而付费的账户。
cresci-17包含2764个人类用户和7049个机器人。
数据集 cresci-17语义(语义信息是用户生成的自然语言帖子和文本,如推文和回复)和属性信息(属性信息是数字和分类的用户特征,如关注者数量和用户是否被验证);
数据集展示:
传统垃圾邮件机器人:
用户:
推文:

社交垃圾邮件机器人:


虚假关注者:
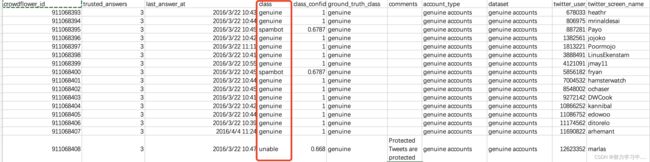
4 caverlee
源自论文:Lee, Kyumin, Brian David Eoff, and James Caverlee. "Seven Months with the Devils: A Long-Term Study of Content Polluters on Twitter." ICWSM. 2011.
论文链接:https://shimo.im/files/Wr3DVowWX6Cp56kJ/ 「14106-Article Text-17624-1-2-20201228.pdf」,可复制链接后用石墨文档 App 或小程序打开
摘要:与Twitter和Facebook等社交网站的流行同步,这些网络上不受欢迎的、破坏性的实体--包括垃圾邮件发送者、恶意软件传播者和其他内容污染者--也在崛起。受致力于确保公地成功的社会学家和专注于阻止破坏行为和预泄犯罪的犯罪学家的启发,我们提出了第一个关于社会蜜罐的长期研究,用于诱惑、剖析和过滤社交媒体中的内容污染者。具体来说,我们报告了我们在Twitter上部署60个蜜罐的七个月的经验,结果收获了36000个候选内容污染者。作为研究的一部分,我们(i)检查了被骚扰的Twitter用户,包括分析链接的有效载荷、用户在一段时间内的行为以及关注者/关注网络的动态;(ii)评估了一系列的特征,以调查自动识别内容污染者的有效性。
描述:这个社会蜜罐数据集从2009年12月30日至2010年8月2日在Twitter上收集。该数据集包含22223个内容污染者,他们在一段时间内的关注人数,2,353,473条推文,以及19276个合法用户,他们在一段时间内的关注人数,3,259,693条推文。
数据集 caverlee包含语义和属性信息;
数据集展示:
包中有六个文本文件
“content polluters.txt” contains content polluters’ profile information in the form of
“UserID
CreatedAt
CollectedAt
NumerOfFollowings
NumberOfFollowers
NumberOfTweets
LengthOfScreenName
LengthOfDescriptionInUserProfile”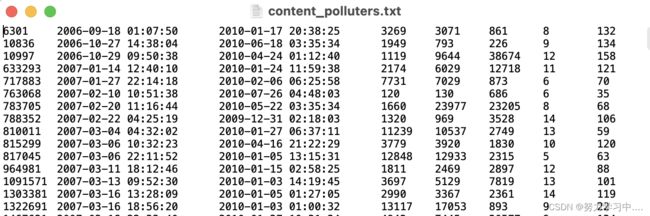
“content polluters followings.txt” contains user information in the test set in the form of(包含了测试集中的用户信息,形式为)
UserID
SeriesOfNumberOfFollowings (each num-
ber of following is separated by ,)
“content polluters tweets.txt” contains tweets in the form of(包含的推文形式为)
“UserID
TweetID
Tweet
CreatedAt”
“legitimate users.txt” contains legitimate users’ profile information in the form of (包含合法用户的个人信息,格式为)
“UserID
CreatedAt
CollectedAt
NumerOfFollowings
NumberOfFollowers
NumberOfTweets
LengthOfScreenName
LengthOfDescriptionInUserProfile” 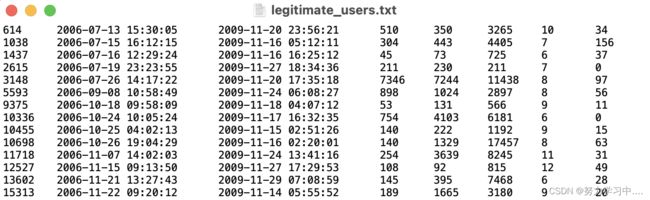
“legitimate users followings.txt” contains user information in the test set in the form of 包含测试集中的用户信息,形式为
“UserID
SeriesOfNumberOfFollowings (each num-
ber of following is separated by ,)”
“legitimate users tweets.txt” contains tweets in the form of(包含的推文形式为)
“UserID
TweetID
Tweet
CreatedAt”
5 gilani-17
源自论文:Gilani, Zafar, Reza Farahbakhsh, Gareth Tyson, Liang Wang, and Jon Crowcroft. "Of bots and humans (on twitter)." In Proceedings of the 2017 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining 2017, pp. 349-354. ACM, 2017.
论文链接:
Of Bots and Humans (on Twitter) | Proceedings of the 2017 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining 2017https://dl.acm.org/doi/pdf/10.1145/3110025.3110090?casa_token=BRFM32jilD8AAAAA:5tYn68-fHa40WKZRCfMgri0X1L7YrtF--6Vne8KdP1hkTFnxCz_9NwI06Rm7qZeCXkIcQhEMhnc摘要:最近的研究表明,机器人在在线社交网络(OSNs)中的存在十分活跃。在本文中,我们利用我们以前的工作(Stweeler)来比较分析机器人和人类在Twitter(世界上最大的OSN之一)的使用和影响。我们收集了一个大规模的Twitter数据集,并根据推文元数据定义了各种指标。使用人类注释任务,我们为数据集分配了 "机器人 "和 "人类 "的基础真实标签,并将注释与在线机器人检测工具进行比较,以进行评估。然后,我们提出了一系列问题,以辨别机器人和人类的重要行为特征,在四个流行组内和之间使用衡量标准。从比较分析中,我们得出这两个实体之间的差异和有趣的相似之处,从而为可靠的机器人分类铺平道路,并研究自动政治渗透和广告活动。
对于gilani-17数据集,使用Twitter流媒体API收集的账户根据关注者的数量被分为四个类别(Gilani等人,2017)。然后,作者从这四个类别中抽出账户,让四个本科生根据编入表格的关键信息对其进行注释。
数据集展示:


6 midterm-18
源自论文:Yang, Kai-Cheng, Onur Varol, Pik-Mai Hui, and Filippo Menczer. "Scalable and generalizable social bot detection through data selection." In Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 01, pp. 1096-1103. 2020.
论文链接:
摘要:
midterm-18数据集是根据2018年美国中期选举期间收集的政治推文进行过滤的。作者手动识别了一些积极参与选举在线讨论的普通人类用户。这些机器人账户是通过其创建和推文时间戳的可疑关联性发现的。大多数机器人账户在选举后被推特暂停,这证明了作者的标签。
数据集展示:
7 cresci-rtbust-2019
源自论文:Mazza, Michele, Stefano Cresci, Marco Avvenuti, Walter Quattrociocchi, and Maurizio Tesconi. "Rtbust: Exploiting temporal patterns for botnet detection on twitter." In Proceedings of the 10th ACM Conference on Web Science, pp. 183-192. 2019.
论文链接:
摘要: