CS224n自然语言处理(一)——词向量和句法分析
文章目录
- 一、词向量
-
- 1.WordNet
- 2.One-hot编码
-
- (1)单词的One-hot编码
- (2)句子的One-hot编码
- 3.Word2Vec
-
- (1)连续词袋模型(CBOW)
- (2)skip-gram
- (3)负采样
- (4)hierarchical softmax
- 4.SVD分解
- 5.GloVe
-
- 代码实现
- 二、命名实体识别
- 三、依存句法分析
-
- 1.成分句法分析
- 2.依存句法分析
-
- (一)Transition-based Dependency Parsing
- (二)Neural Dependency Parsing
- 3.评估结果
参考资料:
详细翻译:CS224n-2019 笔记列表
总结:斯坦福CS224N深度学习自然语言处理2019冬学习笔记目录
一、词向量
NLP——Natural Language Processing,其中Natural Language指的就是人类语言。想让机器理解人类的语言是一项很复杂的任务,而且有很多有趣又实用的研究方向如机器翻译、问答系统等等。
在NLP中,一个重要的问题是如何表示一个单词的含义。几种表示方法如下。
1.WordNet
WordNet,是一个包含同义词集和上位词(“is a”关系)的列表的辞典,例如nltk,一个单词的含义就由它的同义词集合和下义词集合来定义。
这一表示方法有很多问题,例如
- 一个单词只在某些语境下和另一个词为同义词而其他语境下不是
- 缺少单词的新含义,难以持续更新
- 主观的,需要人类劳动来创造和调整
- 无法计算单词相似度
2.One-hot编码
(1)单词的One-hot编码
用one-hot的向量来表示单词,即该单词对应所在元素为1,向量中其他元素均为0,向量的维度就等于词库中的单词数目。例子如下:

One-hot编码的问题是由于所有向量都是互相正交的,我们无法有效的表示两个向量间的相似度,并且向量维度过大。
(2)句子的One-hot编码
![]()
- boolean类型:我们 今天 去 爬山:[1,0,1,1,1,0,0,0]
- count类型:你们 又 去 爬山 又 去 跑步:[0,2,2,1,0,1,0,1]
和词典对应,句子中有词典的词为1或出现次数,没有为0
3.Word2Vec
另一种表示单词含义的方法是分布式语义方法。分布式语义的意思是指一个单词的意思是由经常出现在它附近的单词给出的,一种非常流行的方法是Word2Vec。
Word2vec 是一个学习单词向量的框架,其核心思想就是已知我们有了很大的文本库,当我们用固定窗口不断的扫过文本库的句子时,我们有位于中间的中心词 c 及其上下文词 o, 而它们的相似度可用给定c的情况下o的条件概率来表示,我们不断的调整word vector使得这个概率最大化。每个单词w可用两个向量表示,一个是它作为中心词的向量 Wc 以及它作为上下文词时的向量 Wo 。

在word2vec中,条件概率写作上下文词与中心词的点乘形式再对其做softmax运算,
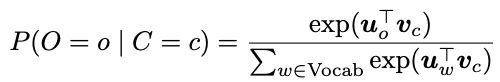
整体的似然率就可以写成这些条件概率的联乘积形式,其中 θ 为所有需要优化的变量:

而我们的目标函数或者损失函数就可以写作如下形式:
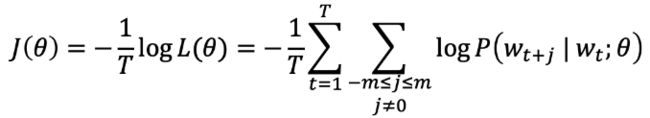
其中log形式是方便将联乘转化为求和,负号是希望将极大化似然率转化为极小化损失函数的等价问题。有了目标函数以及每个条件概率的表现形式,我们就可以利用梯度下降算法来逐步求得使目标函数最小的word vector的形式了。
在Word2Vec中,有两个分支算法,分别是continuous bag-of-words(CBOW)和 skip-gram。还有两种能够优化的训练算法,分别是negative sampling 和 hierarchical softmax。
(1)连续词袋模型(CBOW)
连续词袋模型是从上下文中预测中心词的方法,在CBOW中,我们希望学习两个向量:当词是中心词时的输出向量以及当词在上下文时的输入向量。为此,我们构建两个词矩阵V和U分别代表输入词矩阵和输出词矩阵。其步骤与原理图如下:
- 输入层:上下文单词的onehot
- 通过输入词矩阵 W 得到上下文的嵌入词向量
- 对上述向量求平均值
- 使用平均后的向量和输出词矩阵 W’ 生成一个分数向量并使用softmax转换为概率
- 最后我们希望生成的概率和实际的概率匹配,使输出的词刚好是这个one-hot向量
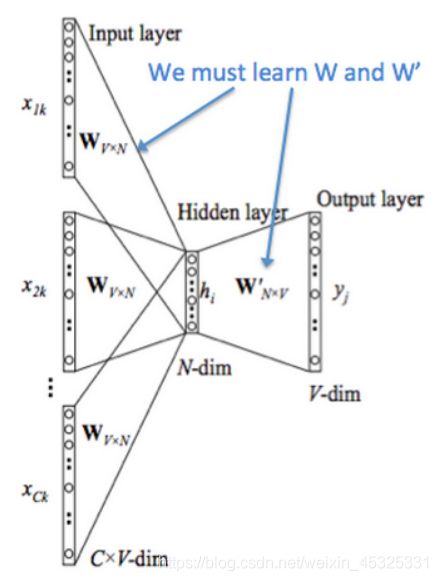
使用交叉熵得出损失函数并使用SGD进行参数更新可以得到最终的结果。
(2)skip-gram
Skip-Gram模型的理论实现与CBOW大体相同,但它是从中心词预测上下文的方法,与之前的CBOW的计算步骤的区别在于将输入和输出调换位置,在计算目标函数的时候引用了朴素的贝叶斯假设来拆分概率,这里假定给定中心词,所有输出的词是完全独立的。

但是在实际实现的过程中发现 W 和 W‘ 的矩阵维度非常大,尤其对于 W‘ 处理矩阵运算的时间很长,因此会采用负采样的方式来模拟多分类任务(负采样见下小节)。
因此对skip-gram模型的实际操作变为:
- 输入三个tensor,分别是代表中心词tensor V ,代表目标词的tensor T,两者形状相同,另一个是代表目标词标签的tensor,大小为 [batch-size,1],包含的元素仅为0或1
- 训练时用 V 查询 W,用 T 查询 W‘,得到两个tensor,分别记为 H1、H2
- 点乘两个tensor H1、H2得到矩阵 O
- 对 O 使用sigmoid函数,根据标签tensor L 进行训练
(3)负采样
在计算目标函数的过程中,输入词矩阵 |V| 的求和计算量是很大的,负采样(negative sampling)解决了这个问题,它是用来提高训练速度并且改善所得到词向量的质量的一种方法。不同于原本每个训练样本更新所有的权重,负采样每次让一个训练样本仅仅更新一小部分的权重,这样就会降低梯度下降过程中的计算量。
在每一个训练的时间步,我们不去遍历整个词汇表,而仅仅是抽取一些负样例进行权重更新。这样做就将原本的 softmax 变成了一个二分类任务。
选择负样本的方法:使用一元模型分布(unigram distribution)来选择负样本,一个单词被选作负样本的概率跟它出现的频次有关,出现频次越高的单词越容易被选作负样本。

上式中 f(w) 代表单词出现的频次
(4)hierarchical softmax
Hierarchical softmax 基本思想是将复杂的归一化概率分解为一系列条件概率乘积的形式:

每一层条件概率对应一个二分类问题,通过逻辑回归函数可以去拟合。对v个词的概率归一化问题就转化成了对logv个词的概率拟合问题。
Hierarchical softmax 使用一个二叉树来表示词表中的所有词。树中的白色节点表示词汇表中的所有单词,黑色节点表示隐节点,对于每个叶子节点,有一条唯一的路径可以从根节点到达该叶子节点,该路径被用来计算该叶子结点所代表的单词的概率。

对于一个节点,假设其对应二叉树编码为{1,0,1…1},则构造的似然函数为

其中每一项乘积因子都是一个逻辑回归函数。可以通过最大化这个似然函数来求解二叉树的参数,即非叶子节点上的向量,用来计算游走到某一子节点的概率。
Hierarchical softmax通过构造一棵二叉树将目标概率的计算复杂度从最初的V降低到了logV的量级。但是却增加了词与词之间的耦合性。比如一个word出现的条件概率的变化会影响到其路径上所有非叶子节点的概率变化。间接地对其他word出现的条件概率带来影响。Hierarchical softmax 对低频词往往表现得更好,负采样对高频词和较低维度向量表现得更好。
4.SVD分解
除了基于上下文模型的Word2Vec模型。还有一类模型是count based的模型,其中的典型代表是奇异值分解(Single Value Decomposition)模型。
通常我们先扫过一遍所有数据,然后得到单词同时出现的共现(co-occurrence)矩阵,然后我们对该矩阵进行SVD得到原矩阵的分解形式 。
获得共现矩阵的两种方法:
- word-document:该方法基本假设是在同一篇文章中出现的单词更有可能相互关联。假设单词 i 出现在文章 j 中,则矩阵元素 Xij 加一,当我们处理完数据库中的所有文章后,就得到了共现矩阵,其大小为 |V| x M,其中 |V| 为词汇量,而 M 为文章数。
- window-based:利用某个定长窗口中单词与单词同时出现的次数来产生共现矩阵。假设窗口大小为1并且数据包含以下几个句子:
I like deep learning.
I like NLP.
I enjoy flying。
则得到的共现矩阵如下图:

简单的共现矩阵存在的问题是随着单词的增多矩阵大小会变大,需要很大的存储空间进行存储,模型的鲁棒性较差等等。使用SVD方法对共现矩阵进行分解可以得到一个对角矩阵,对角线上的值为矩阵的奇异值,和两个对应于行和列的正交基。
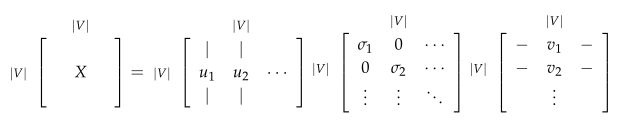
为了减少尺度同时尽量保存有效信息,可保留对角矩阵的最大的k个值,并将矩阵U和V的相应的行列保留。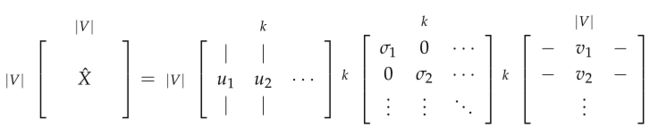
在基于计数的方法中可以使用的一些技巧:
- 对高频词进行缩放:log缩放/直接忽略/设置上限
- 在基于window的计数中,提高更加接近的单词的计数
- 使用Person相关系数
对比Word2Vec这类基于迭代的方法和共现矩阵这类基于计数的方法:
- 基于迭代
- 优点:可以捕捉除了相似性的复杂模型、提高对其他任务的性能
- 缺点:统计数据的低效使用、训练速度与语料库有关
- 基于计数
- 优点:训练速度快、高效利用统计数据
- 缺点:主要用于捕捉单词相似性、对于大量数据重要性不成比例
5.GloVe
参考论文:Glove
GloVe(Global Vectors)算法结合上面基于计数和转换计数两种方法的优点,能够有效的利用全局统计信息。
GloVe算法的关键思想:共现概率的比值可以对meaning component进行编码

例如上图我们想区分热力学上两种不同状态ice冰与蒸汽steam,它们之间的关系可通过与不同的单词 x 的共现概率的比值来描述。比如对于solid固态,虽然P(solid|ice)和P(solid|stream)的值很小不能透露有效信息,但两者的比值很大,因此solid在ice上下文出现的概率比较大,对于gas则恰恰相反,而对于water这种和两者都有紧密关系或者fashion这种毫无关系的单词,比值接近于1。
GloVe的损失函数形式
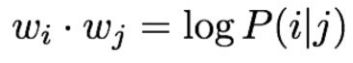

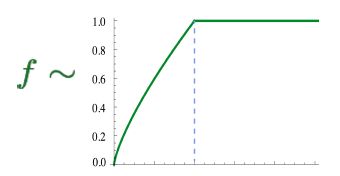
f(X)用来进行权重限制,图像如下:
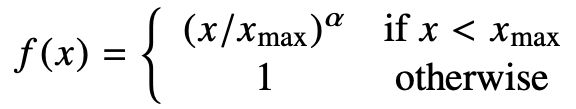
代码实现
首先安装Glove包pip install glove-python
demo展示
from glove import Glove
from glove import Corpus
# 数据集准备
sentences = [['你', '是', '谁']]
corpus_model = Corpus()
corpus_model.fit(sentences, windows=10)
corpus_model.save('corpus.model')
# glove训练
glove = Glove(no_components=100, learning_rate=0.05)
glove.fit(corpus_model.matrix, epochs=10, no_threads=1, verbose=True)
glove.add_dictionary(corpus_model.dictionary)
# 模型保存与加载
glove.save('glove.model')
glove = Glove.load('glove.model')
# Corpus保存与加载
corpus_model.save('corpus.model')
corpus_model = Corpus.load('corpus.model')
# 使用:求相似词
glove.most_similar('我', number=10)
# 全部词向量矩阵
glove.word_vectors
二、命名实体识别
命名实体识别(Named Entity Recognition):主要是要找到文本中的名字并对其进行分类,例如下图中找到地点类名词和人物类名词。

NER的应用场景较多,例如
- 跟踪文档中提到的特定实体(组织、个人、地点、歌曲名、电影名等)
- 对于问题回答,答案通常是命名实体
- 许多需要的信息实际上是命名实体之间的关联
- 同样的技术可以扩展到其他 slot-filling 槽填充分类
NER的难点也有很多,包括:
- 有的时候很难区分Named Entity的边界
- 有的时候很难判断一个词是不是Named Entity
- Named Entity依赖于上下文,同一个名词可能在某些语境中是机构名,在其他语境中又是人名。
鉴于同一个词在不同上下文可能是不同的Named Entity,一个思路是通过对该词在某一窗口内附近的词来对其进行分类(这里的类别是人名,地点,机构名等等),该窗口的思路和之前Word2Vec的思路类似。
例如对于下图中的句子museums in Paris are amazing, 我们希望探测到地点名Paris。假设窗口大小为2,并且通过词向量方法如word2vec得到窗口内5个单词的词向量,则我们可以将这5个向量连在一起得到更大的向量,再对该向量进行分类。

对于具有多个class的分类问题,我们通常用softmax分类来解决,假设用x来表示输入的词向量,y表示对应的class,总共有k个class,则x对应类别为y的概率为:

损失函数为交叉熵:

为了处理输入的元素间的非线性关系,我们可以利神经网络,并且输出层是计算每一个class的概率的softmax layer。

之后我们就可以利用随机梯度下降算法SGD来更新网络并利用反向传播算法来有效的计算梯度。
三、依存句法分析
句法结构(syntactic structure)分析是给定一个输入句子 S,分析句子的句法依存结构的任务。确切地说,在依存语法中有两个子问题:
- 学习:给定用依赖语法图标注的句子的训练集 D,创建一个可以用于解析新句子的解析模型 M
- 解析:给定解析模型 M 和句子 S,根据 M 得到 S 的最优依存语法图
对于句法结构分析,主要有两种方式:成分句法分析(Constituency Parsing)与依存句法分析(Dependency Parsing)。
1.成分句法分析
成分句法分析主要用phrase structure grammer即短语语法来不断的将词语整理成嵌套的组成成分,又被称为context-free grammers,简写做CFG。
成分句法分析是使用逐步嵌套的单元构建的
- 起步单元:每个单词被赋予一个类别 (part of speech=pos 词性)
- 单词组合成不同类别的短语
- 短语可以递归地组合成更大的短语
例子如下图所示,单词与单词组合得到短语,短语和短语组合得到更大的短语,最后形成句子。

关于成分句法分析后续会涉及
2.依存句法分析
依存句法分析展示了词语之前的依赖关系,通常用箭头表示其依存关系,有时也会在箭头上标出其具体的语法关系,如是主语还是宾语关系等。词与词之间的二元非对称关系称为关联语法,也叫作依存关系(Dependency Grammar),一般这些依存关系形成依存结构(Dependency Structure)。
依存结构有两种表现形式,一种是直接在句子上标出依存关系箭头及语法关系

另一种是将其做成树状机构(Dependency Tree Graph)
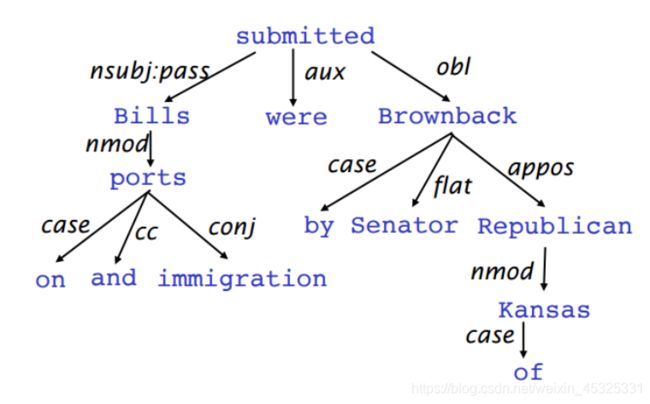
- 箭头通常标记(type)为语法关系的名称
- 箭头连接头部和一个依赖
- 通常添加一个伪根指向整个句子的头部,这样每个单词都精确地依赖于另一个节点
- 只有一个单词是依赖于根的,不存在闭环
因此依存句法分析可以看做是给定输入句子构建对应的依存树图的任务。构建方法有很多种,例如动态规划、图算法,这里介绍一个有效的构建方法是Transition-based Dependency Parsing。
(一)Transition-based Dependency Parsing
Transition-based 依存语法依赖于定义可能转换的状态机,以创建从输入句到依存句法树的映射。学习问题是创建一个可以根据转移历史来预测状态机中的下一个转换的模型。分析问题是使用在学习问题中得到的模型对输入句子构建一个最优的转移序列。大多数 Transition-based 系统不会使用正式的语法。
Greedy Deterministic Transition-Based Parsing方法如下图所示,
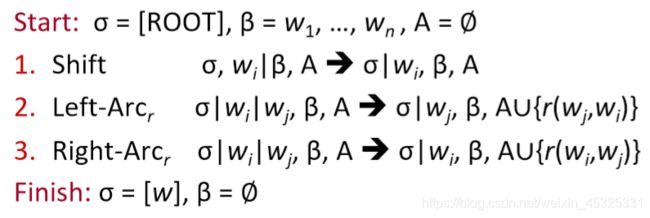
在初始状态下,我们有三个状态机组成,
- 栈σ,初始状态下仅有ROOT w0,里面可以存放若干个单词
- 缓存β,初始状态下存放所有单词w1、w2……
- 依存关系集合A,初始为空,用来存放dependency arc,即描述依存关系的结果
三个状态之间的转换有三类:
- SHIFT:将 buffer 中的第一个词移出并放到 stack 上。
- LEFT-ARC:将 (wj, r, wi) 加入边的集合 A ,其中 wi 是stack上的次顶层的词, wj 是stack上的最顶层的词。
- RIGHT-ARC:将 (wi, r, wj) 加入边的集合 A ,其中 wi 是stack上的次顶层的词, wj 是stack上的最顶层的词。
我们不断的进行上述三类操作,直到从初始态达到最终态。在每个状态下如何选择哪种操作呢?当我们考虑到LEFT-ARC与RIGHT-ARC有很多类,我们可以将其看做是的分类问题,可以用SVM等传统机器学习方法解决。
(二)Neural Dependency Parsing
传统的Transition-based Dependency Parsing对特征工程要求较高,我们可以用神经网络来进行改良。神经网络依存语法解析器性能和效果更好。与以前模型的主要区别在于这类模型依赖稠密而不是稀疏的特征表示。
对于Neural Dependency Parser,其输入特征通常包含三种:
- stack和buffer中的单词及其dependent word。
- 单词的词性标注(Part-of-Speech tag)。词性标注是由离散集合P={NN,NNP,NNS,DT,JJ,…}
- 单词的依存标签。依存标签是由一个依存关系的离散集合组成: L={amod,tmod,nsubj,csubj,dobj,…}。
对每种特征类型,我们都有一个对应的将特征的 one-hot 编码映射到一个 d 维的稠密的向量表示的嵌入矩阵。
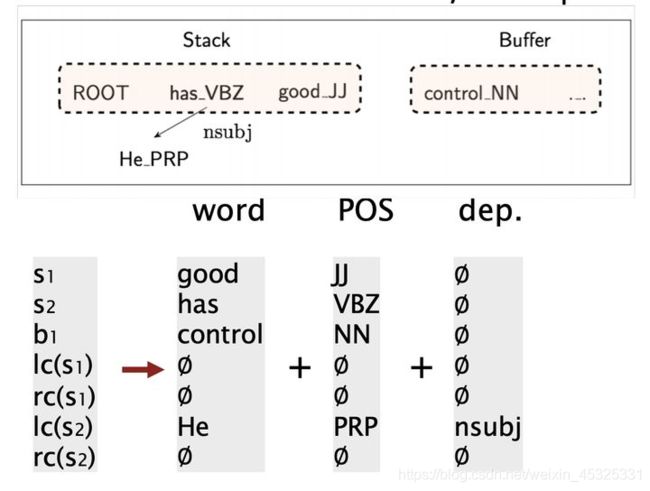
我们将其转换为词向量并将它们联结起来作为输入层,再经过若干非线性的隐藏层,最后加入softmax layer得到每个class的概率。

利用这样简单的前置神经网络,我们就可以减少feature engineering并提高准确度。在之后的研究中海油基于图的依存关系分析等更好的模型。
3.评估结果
评估句法分析有两个指标,一个是LAS(labeled attachment score)即只有arc的箭头方向以及语法关系均正确时才算正确,以及UAS(unlabeled attachment score)即只要arc的箭头方向正确即可。例子如下图,
