云原生数据库高可用,一键实现跨可用区,跨区域灾备


点击上方【凌云驭势 重塑未来】
一起共赴年度科技盛宴!
云原生数据库
全球架构,一键部署,无需担心灾难恢复
数字时代背景下,企业的 IT 基础设施最头痛的问题就是——灾备。
数据中心突然失去服务能力、影响业务,而不论是电力中断、网络故障、硬件故障,还是人为操作失误或恶意破坏,以及自然灾害等都有可能导致这一“灾难”的发生,所以为了保证数据库稳定运行、损失降到最低,提前进行容灾备份是十分有必要的。
亚马逊云科技的云原生数据库以高可用作为第一考量,而亚马逊云科技云原生数据库可以轻松全球部署,实现异地灾备和全球客户体验一致的目标,进而保证业务拓展到全球。不同区域的客户可以享受到同样的数据访问体验。解决数据库全球扩展问题,在业务快速发展阶段,可以有效帮助底层数据架构的扩展。
云原生数据库高可用——Region(区域)内的跨可用区(Multi Availability Zone)高可用
亚马逊云科技所有云原生数据库都具备 Multi-AZ 高可用特性,我们以 Amazon RDS Multi-AZ 和 Aurora 作为案例分享,云上托管数据库服务 Amazon RDS 提供了丰富的多可用区部署选项,用户可以有一个备用或两个备用数据库实例。当部署有一个备用数据库实例时,称为多可用区数据库实例部署。多可用区数据库实例部署有一个备用数据库实例,可提供故障转移支持,但不提供读取流量。当部署有两个备用数据库实例时,称为多可用区数据库集群部署。多可用区数据库集群部署具有备用数据库实例,可提供故障转移支持,还可以提供读取流量。
Amazon RDS 多可用区部署让 RDS 数据库(DB)实例的可用性和持久性得到提升,使其成为生产系统数据库工作负载的天然搭档。当您预置多可用区数据库实例时、Amazon RDS 会自动创建主数据库实例,并将数据同步复制到不同可用区(AZ)中的备用实例。每个可用区在其独立的、不同的基础设施中运行,并具备高可靠性。如果基础设施出现故障停机,Amazon RDS 会自动执行故障转移到备用设备(如果是 Amazon Aurora,则可以转移到只读副本),以便在故障转移完成后立即恢复数据库操作。由于数据库实例的终端节点在故障转移后保持一致,所以应用程序无需手动管理干预即可恢复数据库操作。
值得一提的是,云原生数据库 Amazon Aurora 通过采用专为数据库工作负载构建、基于 SSD 的虚拟化存储层,进一步扩展了多可用区的优势。它会跨三个可用区自动以六种方式复制存储。Amazon Aurora 使用容错存储,它能够以透明方式应对最多两个数据副本丢失的情况,而不会影响数据库写入可用性,还能在不影响读取可用性的情况下应对最多三个副本丢失的情况。无论数据库是否使用只读副本,Aurora 都始终会跨三个可用区复制您的数据。
多可用区集群部署工作原理(带两个可读备用实例的 Amazon RDS)
使用 Amazon RDS Multi-AZ 在三个可用区中部署具有高可用性和持久性的 MySQL 或 PostgreSQL 数据库,并提供两个可读备用实例。通常在不到 35 秒的时间内实现自动故障转移,与带一个备用实例的 Amazon RDS Multi-AZ 多可用区数据库实例部署相比,事务提交延迟快 2 倍,拥有额外的读取容量。

多可用区数据库集群部署特点:
通常在 35 秒内自动故障转移 |
通常在 35 秒内自动进行故障转移,不会丢失数据,无需手动干预。 |
使用单独的终端节点进行读取和写入 |
将查询路由到写服务器和适当的只读副本备用实例,以最大限度地提高性能和可扩展性。 |
事务提交延迟提高多达 2 倍 |
与带有一个备用实例的多可用区相比,写入延迟提高了 2 倍。 |
增加读取容量 |
通过在两个可读备用实例之间分配流量,获得读取可扩展性。 |
云原生数据库超强的高可用——借助全球数据库实现跨区域高可用
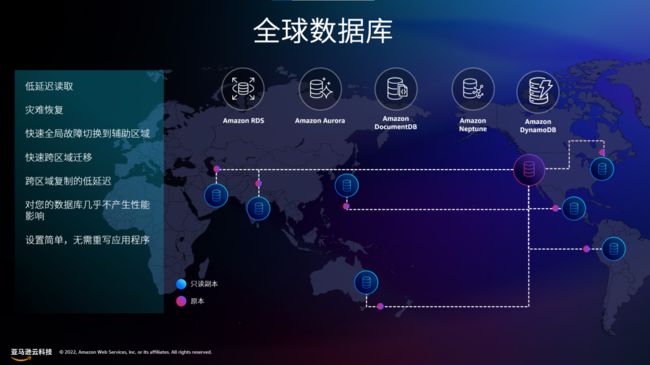
我们提供了多种全球数据库方案供客户挑选,其中就包括了 Amazon Aurora 、Amazon DynamoDB,Amazon ElastiCache,Amazon DocumentDB。

我们以 Amazon Aurora 为例
Amazon Aurora 被称为保护组的 10 GB 逻辑块中构建其存储卷。然后,它将每个保护组中的数据复制到跨同一区域的三个可用区分配的六个存储节点。如果数据量超过当前分配的存储量,Aurora 会无缝扩展数据量以满足需求,并在必要时添加新的保护组。
Aurora 全球数据库(发布于 re:Invent 2018 )将此复制过程扩展到其他区域。这提供了更快的跨区域灾难恢复,并实现了高性能、低延迟、跨区域读取扩展。借助 Aurora 全球数据库,您可以将数据库扩展到多个区域,同时将对数据库性能的影响降到最低。

什么是 Aurora 全球数据库?
Aurora 全球数据库跨越多个区域,提供从区域范围的中断中恢复的能力,并支持低延迟的全球读取。
作为 Aurora 的一项功能,全局数据库使用 Aurora 专门构建的存储层中的专用基础设施来处理跨区域的复制。存储层中的专用复制服务器处理复制,从而在不影响数据库性能的情况下为您提供增强的恢复和可用性目标。
MySQL 二进制日志复制和 Aurora Global Database 使用的基于存储的复制有几个关键区别。逻辑复制或二进制日志复制记录复制源(主)上的数据修改语句或行更改,并在复制目标(副本)上重新应用它们。主数据库和副本数据库是独立的,可以包含不同的数据集。
另一方面,Aurora Global Database 采用物理存储级复制来创建具有相同数据集的主数据库副本,从而消除了对二进制日志的任何依赖。全局数据库的辅助 Region 实例不会重放数据修改语句。这极大地减少了复制开销,并为应用程序工作负载留下更多可用容量。
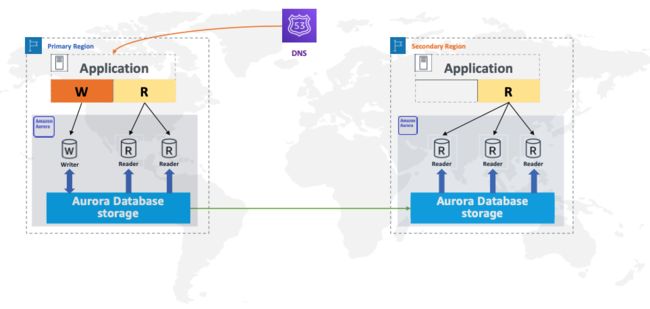
这意味着来自编写器的已提交事务更改将全局复制到您选择的区域,通常在一秒钟内完成。虽然全局数据库处理此复制,但数据仍持久存储在集群每个区域的三个可用区中。
为什么要使用全球数据库?
Aurora Global Database 提供了几个重要的特性:
快速全局故障转移到次要区域
跨区域的低复制延迟
对您的数据库几乎没有性能影响
MySQL 兼容性
快速全局故障转移到次要区域
一个有信心的灾难恢复计划可以让您对您的业务连续性计划更有信心,以防发生意外事件。Aurora Global Database 在灾难恢复的两个重要指标方面表现出色:
l RTO(恢复时间目标)— 灾难发生后您需要多长时间才能恢复到工作状态。
l RPO(恢复点目标)——您可能丢失多少数据。
借助 Aurora Global Database,可以实现
RPO 不到 5 秒,最大限度地减少了数据丢失
RTO 不到一分钟,从而减少了停机时间。
Aurora Global Database 提供灾难恢复和即使在区域范围内发生故障时也能继续运行的能力。在数据库可能降级或隔离期间,Aurora 全局数据库会快速响应以提升次要区域。通过基于全局存储的复制,这个提升的区域可以在一分钟内完成全部读/写工作负载,从而最大限度地减少对应用程序正常运行时间的影响。
跨区域的低复制延迟
除了提供灾难恢复外,Aurora Global Database 还允许您将读取从主要区域快速卸载到次要区域。Aurora Global Database 保持典型的复制延迟小于一秒,上限为 5 秒。这种低延迟为在线事务处理(OLTP)工作负载提供了全局读取横向扩展。
低延迟让您可以更接近(更快地从)全球客户端应用程序读取,以获得最佳用户体验和参与度。运行共享通用配置数据的多区域应用程序堆栈的客户可以依靠 Aurora 全球数据库几乎即时地复制数据。

如果您在全球设有多个办事处和全球客户群,您可以在主要区域上传您的内容,并以本地延迟将其提供给世界各地的客户。且对您的数据库上层应用几乎没有性能影响。
什么是云原生数据库?
亚马逊云科技云原生数据库是云原生数据基础设施的重要组成部分,是一种完全利用公有云优势的数据库,具备极致的弹性伸缩能力、无服务器(Serverless)特性、全球架构高可用与低成本,并可以与云上其他服务集成联动。其中,关系型数据库以 Amazon Aurora 为范例,非关系型数据库以 Amazon DynamoDB、Amazon DocumentDB 为范例。
![]()
2022亚马逊云科技 re:Invent 全球大会
中国行现已开启!
点击下方图片即刻注册



听说,点完下面4个按钮
就不会碰到bug了!
