如何利用指标和日志排查App Mesh相关网络问题


点击上方【凌云驭势 重塑未来】
一起共赴年度科技盛宴!
Amazon App Mesh 是亚马逊云科技的托管服务网格解决方案。通过使用 Sidecar 部署方式,App Mesh 可以在不对应用程序进行更改的前提下,提供网络流量控制、流量加密和可观测性,帮助您轻松运行服务,而无需修改应用源代码。
Amazon App Mesh 使用开源的 Envoy 代理来接管进出容器的网络流量,以达到进行流量控制的目的。但由于流量需要通过 Envoy 进行转发,在相对复杂的网络环境下,Envoy 和应用自身产生的非正常返回值(如503、504等)会混杂在一起,导致很难判断具体故障。
Envoy 有着完善的可观测性功能,会以通用的 Prometheus 格式暴露指标。管理员可以通过指标直观地查看 Envoy 的运行状况并定位故障。Envoy 也同时提供访问日志功能,可以更详细地查找每条请求的来源、目标、返回值等基本信息。对于非正常返回的请求,也会通过自定义 Header 或在报错中包含的方式,提示问题根因。
本文会介绍如何在 Amazon Elastic Kubernetes Service (以下简称 Amazon EKS) 环境下收集 App Mesh 暴露的指标和日志,并通过这些资源分析问题。其他运行环境(Amazon Elastic Container Service,Amazon EC2)下仅有采集方式不同,分析方式相对一致,故在此不再赘述。
Amazon App Mesh:
https://aws.amazon.com/cn/app-mesh/
Envoy:
https://www.envoyproxy.io/
Prometheus:
https://prometheus.io/
Amazon Elastic Kubernetes Service:
https://aws.amazon.com/cn/eks/
先决条件
1.拥有管理员权限的亚马逊云科技账号;
2.正在运行的 Amazon EKS 集群,版本为1.21以上;
3.已安装 kubectl 和 helm 客户端;
4.使用者对 Amazon EKS 和 Amazon App Mesh 有基本了解。

部署示例应用
“
部署 Amazon App Mesh Controller
在 Amazon EKS 环境,可以使用 Amazon App Mesh Controller 创建并管理 Amazon App Mesh 资源,并自动为启动的 Pod 注入 Envoy。Amazon App Mesh Controller 可以通过 Helm Chart 部署。请参考此文档以部署 Amazon App Mesh Controller。
此文档:
https://github.com/awseks-charts/tree/master/stable/appmesh-controller
“
部署示例应用
亚马逊云科技提供了示例应用以演示 Amazon App Mesh 的功能。运行以下命令以部署 howto-k8s-connection-pools 应用,该应用会演示连接池功能。请将123456789012替换为您的12位亚马逊云科技账户 ID, us-west-2 替换为您 Amazon EKS 集群所在的区域。
cd ~
git clone https://github.com/aws/aws-app-mesh-examples
cd aws-app-mesh-examples/walkthroughs/howto-k8s-connection-pools/
export AWS_ACCOUNT_ID=123456789012
export AWS_DEFAULT_REGION=us-west-2
./deploy.sh左滑查看更多
这一部署脚本会构建应用镜像,推送至 Amazon ECR,并将应用部署到 Amazon EKS。Amazon App Mesh Controller 会自动在 Pod 中插入 Envoy。
可以通过 kubectl get all -n howto-k8s-connection-pools 检查是否部署完成:
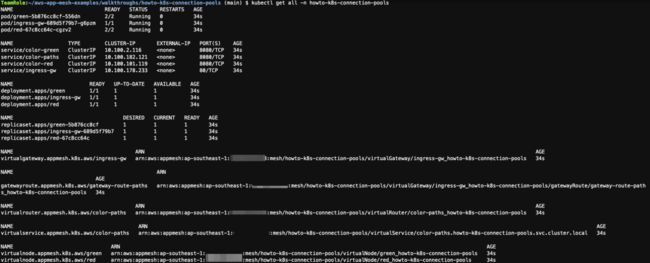
部署完成后,将创建的 Service 打上标签以便下一步进行服务发现。运行下列命令:
kubectl label svc color-green -n howto-k8s-connection-pools package=howto-k8s-connection-pools
kubectl label svc color-red -n howto-k8s-connection-pools package=howto-k8s-connection-pools
kubectl label svc color-paths -n howto-k8s-connection-pools package=howto-k8s-connection-pools
kubectl label svc ingress-gw -n howto-k8s-connection-pools package=howto-k8s-connection-pools左滑查看更多
Amazon ECR:
https://aws.amazon.com/cn/ecr/

利用 Prometheus
抓取 Amazon App Mesh 数据平面指标
Amazon App Mesh 采用 Envoy 作为数据平面。Envoy通过 /stats 接口提供数百个指标以展现 Envoy 自身和处理的连接状况。连接会根据其状况(返回值、是否触发连接池、是否重试、中断原因等)被添加到某项指标中。Envoy 支持通过 statsd 和 Prometheus 格式暴露指标。在 Amazon EKS 环境下,可以使用 Prometheus 收集指标,并使用 Grafana 可视化分析。
“
安装 Prometheus
使用 kube-prometheus 快速部署完整的 Prometheus 集群。该方案会部署 Prometheus Operator,并通过 Operator 部署 Prometheus 实例。同时会部署 node-exporter, kube-state-metrics, alertmanager 和 Grafana,快速构建完整的监控体系。在终端运行以下命令:
cd ~/environment/
git clone https://github.com/prometheus-operatorkube-prometheus.git --branch release-0.11
cd kube-prometheus左滑查看更多
默认情况下,创建的 Prometheus 没有持久化存储,会导致数据在 Pod 重启后丢失。可参考文档编辑 manifests/prometheus-prometheus.yaml,自行为 Prometheus 添加持久化存储。
为访问 Prometheus 查询指标,需要将 Prometheus 通过负载均衡器对外暴露。修改 manifests/prometheus-service.yaml:
apiVersion: v1
kind: Service
...
spec:
...
sessionAffinity: ClientIP # 删除该行
type: LoadBalancer # 添加该行默认情况下,Prometheus 无法抓取来自其他 Namespace 的内容。需要为 Prometheus 提供更多权限。将 manifestsprometheus-clusterRole.yaml 替换成以下内容:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/instance: k8s
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.36.1
name: prometheus-k8s
rules:
- apiGroups:
- ""
resources:
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
- apiGroups:
- ""
resources:
- services
- endpoints
- pods
verbs:
- get
- list
- watch
- apiGroups:
- networking.k8s.io
resources:
- ingresses
verbs:
- get
- list
- watch左滑查看更多
修改完成后,进行部署:
kubectl apply --server-side -f manifests/setup
until kubectl get servicemonitors --all-namespaces ; do date; sleep 1; echo ""; done
kubectl apply -f manifests/左滑查看更多
组件默认会部署在 monitoring 命名空间。部署完成后,可使 kubectl get po -n monitoring 检查 Pod 运行状况:
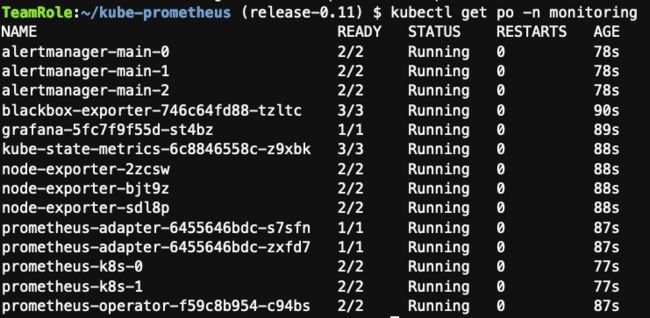
可以通过 kubectl get svc prometheus-k8s -n monitoring 获取访问 Prometheus 的地址,并通过 http://:9090/ 访问:

kube-prometheus:
https://github.com/prometheus-operator/kube-prometheus
文档:
https://github.com/prometheus-operator/prometheus-operator/blob/main/Documentation/user-guides/storage.md
“
利用 Prometheus 获取 Envoy 指标
Envoy 默认将指标通过 /stats/prometheus 接口以 Prometheus 兼容格式将指标暴露出来。通过配置 ServiceMonitor,Prometheus 可以通过服务发现的形式,自动抓取 Service 对应的 Pod,从而捕获 Envoy 暴露的指标。
创建 servicemonitor.yaml,内容如下:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: howto-k8s-connection-pools
namespace: monitoring
labels:
package: howto-k8s-connection-pools
spec:
endpoints:
- targetPort: 9901
path: /stats/prometheus
interval: 5s
namespaceSelector:
any: true
selector:
matchLabels:
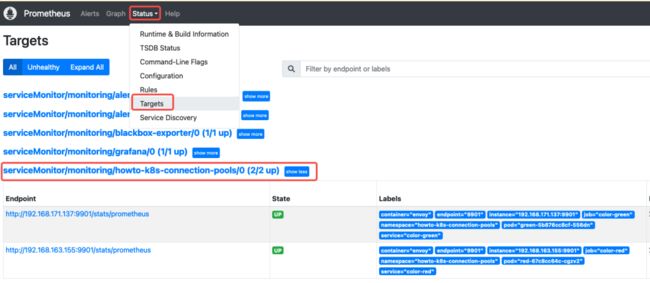
package: howto-k8s-connection-pools运行 kubectl apply -f servicemonitor.yaml 将其部署至集群。部署完成后,在 Prometheus 界面中的 Status – Targets 应当可以看到运行的 Pod。
返回 Graph,运行查询 envoy_server_live{} ,结果数量应与目前部署 Pod 数量一致。
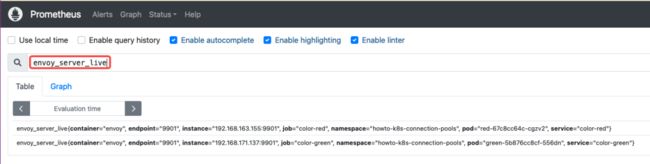
此时,Envoy 的指标已被 Prometheus 所捕获,可以通过 Prometheus 对指标进行分析。

启用 Envoy 访问日志
Amazon App Mesh 允许用户快速启用 Envoy 访问日志。默认日志的格式为:
[%START_TIME%] "%REQ(:METHOD)% %REQ(X-ENVOY-ORIGINAL-PATH?:PATH)% %PROTOCOL%"
%RESPONSE_CODE% %RESPONSE_FLAGS% %BYTES_RECEIVED% %BYTES_SENT% %DURATION%
%RESP(X-ENVOY-UPSTREAM-SERVICE-TIME)% "%REQ(X-FORWARDED-FOR)%" "%REQ(USER-AGENT)%"
"%REQ(X-REQUEST-ID)%" "%REQ(:AUTHORITY)%" "%UPSTREAM_HOST%"\n左滑查看更多
可以参考此 Envoy 文档获取日志各字段的详细含义。其中对故障排查作用较大的为 RESPONSE_CODE 和 RESPONSE_FLAGS,这两个指标描述了返回值和非正常返回时的报错原因。
可以通过修改 Virtual Node 的参数以启用访问日志。运行以下命令编辑创建好的 Virtual Node:
kubectl edit virtualnode green -n howto-k8s-connection-pools
apiVersion: appmesh.k8s.aws/v1beta2
kind: VirtualNode
metadata:
...
spec:
...
serviceDiscovery:
dns:
hostname: color-green.howto-k8s-connection-pools.svc.cluster.local
logging: # 加入以下内容
accessLog:
file:
path: "/dev/stdout"左滑查看更多
该配置生效后,Envoy 会将访问日志输出至标准输出,可以通过 kubectl logs

可以通过 Fluent Bit 等日志收集器将日志收集到其他存储,或使用 Log Hub 等日志解决方案进行收集。
注:目前通过 Amazon App Mesh Controller 创建的 Virtual Node 无法自定义日志格式。
Envoy 文档:
https://www.envoyproxy.io/docs/envoy/latest/configuration/observability/access_log/usage#command-operators
Fluent Bit:
https://fluentbit.io/
Log Hub:
https://awslabs.github.io/log-hub/zh/

通过指标和日志进行分析
下面会以连接池场景为例,测试如何根据指标和日志分析错误原因。样例应用已经为 green Virtual Node 配置了连接池,详细配置可以通过 kubectl get virtualnode green -n howto-k8s-connection-pools -o yaml 查看。具体配置如下所示:
listeners:
- connectionPool:
http:
maxConnections: 10
maxPendingRequests: 10可以看到,该配置允许最多10个并发请求,在连接池中还可以有10个请求在等待。
在部署示例应用时,同时在 default 命名空间部署了一个 fortio Pod。Fortio 是一个负载测试组件,可以进行基于 http 或 grpc 的负载测试。您可以利用部署的 fortio 生成远超于该并发数的流量以进行测试,以模拟流量过载的场景。运行以下命令:
FORTIO=$(kubectl get pod -l "app=fortio" --output=jsonpath={.items..metadata.name})
kubectl exec -it $FORTIO -- fortio load -allow-initial-errors -c 30 -qps 9000 -t 600s http://color-green.howto-k8s-connection-pools:8080左滑查看更多
此时您可以新建一个终端窗口,模拟其他用户访问:
FORTIO=$(kubectl get pod -l "app=fortio" --output=jsonpath={.items..metadata.name})
kubectl exec -it $FORTIO -- fortio load --curl http://color-green.howto-k8s-connection-pools:8080左滑查看更多
多运行几次,会发现访问出错,错误日志如下所示:
$ kubectl exec -it $FORTIO -- fortio load --curl http://color-green.howto-k8s-connection-pools:8080
10:04:04 W http_client.go:942> [0] Non ok http code 503 (HTTP/1.1 503)
HTTP/1.1 503 Service Unavailable
x-envoy-overloaded: true
content-length: 81
content-type: text/plain
date: Thu, 01 Dec 2022 10:04:04 GMT
server: envoy
upstream connect error or disconnect/reset before headers. reset reason: overflow左滑查看更多
根据返回 HTTP 头中的 server 字段,可以判断该报错是由 Envoy 返回。您可以从报错信息和 Envoy 添加的自定义 HTTP 头 x-envoy-overloaded: true 中了解到错误原因是 overflow。通过查询 Envoy 文档,可以发现该错误来源于断路器,当连接池满时会产生该报错。
您可以检查 Envoy 访问日志以进一步确认:
[2022-12-01T10:04:07.584Z] "GET / HTTP/1.1" 503 UO 0 81 0 - "-" "fortio.org/fortio-1.39.0-pre4" "93739f95-2dbe-90c3-9f68-b9b829cf652c" "color-green.howto-k8s-connection-pools:8080" "-"左滑查看更多
可以看到,该请求返回值是503,错误码是 UO。通过查询 Envoy 访问日志文档,UO 错误码代表 Upstream overflow (circuit breaking) in addition to 503 response code.,同样显示断路器开启,导致 Envoy 直接返回503。
除了访问日志外,您还可以通过指标查找错误原因。由于断路器工作在 Cluster 层面,您可以从 Cluster 的指标列表中找到相关指标,在 Prometheus 上运行:
envoy_cluster_circuit_breakers_default_cx_open{pod~="green-.*"}

此时可以看到,标注为
envoy_cluster_name="cds_ingress_howto-k8s-connection-pools_green_howto-k8s-connection-pools_http_8080"的值为1。根据 App Mesh 的命名规则,带 Ingress 前缀的 Cluster 的作用是 Envoy 向应用发送入站请求。该指标值1意味着入站断路器开启,Envoy 阻断了发往应用的请求。
为检查应用本身的运行状况,可以运行下列查询:
envoy_cluster_upstream_rq_timeout{pod~="green-.*",envoy_cluster_name="cds_ingress_howto-k8s-connection-pools_green_howto-k8s-connection-pools_http_8080"}
envoy_cluster_upstream_cx_connect_fail{pod~="green-.*",envoy_cluster_name="cds_ingress_howto-k8s-connection-pools_green_howto-k8s-connection-pools_http_8080"}}
这两条查询会反馈 Envoy 向应用发出的请求是否超时或连接失败。可以看到,这两次查询返回值都是0,也就意味着应用正常工作。
综合以上分析可以得知,此时应用仍然正常工作,但受断路器限制,连接在 Envoy 处由于连接池满,被提前终止,从而返回503错误。通过修改 Virtual Node 中的 ConnectionPool 配置,问题解决。
Fortio:
https://github.com/fortio/fortio
Envoy 文档:
https://www.envoyproxy.io/docs/envoy/latest/intro/arch_overview/upstream/circuit_breaking
Envoy 访问日志文档:
https://www.envoyproxy.io/docs/envoy/latest/configuration/observability/access_log/usage#command-operators
Cluster 的指标列表:
https://www.envoyproxy.io/docs/envoy/latest/configuration/upstream/cluster_manager/cluster_stats#circuit-breakers-statistics
App Mesh 的命名规则:
https://docs.aws.amazon.com/app-mesh/latest/userguide/envoy-metrics.html
“
常见的故障分析流程
从刚才的示例中您可以看到,Envoy 会通过多种手段暴露错误信息以便排查。在真实环境,不知道错误来源的情况下,可以按照以下步骤进行排查:
1.如果可以获得报错时的完整响应 Header 和消息,则 Envoy 会尽可能的将错误原因通过自定义 Header(一般为 x-envoy 开头)返回。可以根据错误原因查找对应的指标或日志错误码。
2.可以通过分布式跟踪,日志搜索或指标监控确定报错时访问到的 Pod,通过查找访问日志确定问题来源和根因。
3.如果无法获得访问日志,则需要通过指标查询来确认具体问题根因。由于涉及到的指标较多,建议提前对关键的报错指标设置告警。
“
清理
为防止创建的资源产生额外费用,您可以清理创建的资源。
1.在终端中,运行 kubectl delete all -n howto-k8s-connection-pools 以删除部署的示例应用,负载均衡器及 Amazon App Mesh 资源。
2.运行以下命令以删除部署的 Prometheus 实例。
cd ~/environment/kube-prometheus
kubectl delete -f manifests/
kubectl delete -f manifests/setup3.进入 Amazon ECR 控制台,删除创建的镜像仓库。

总结
Envoy 提供了指标,错误消息和访问日志三种方式,来帮助管理员分析异常返回的具体原因。本文简单介绍了如何使用 Prometheus 监控 Envoy 指标,如何开启访问日志,以及在故障发生时如何利用这三种手段快速定位问题。限于篇幅,本文并未详细介绍 Envoy 的其他指标和日志含义,各位可以从 Envoy 官方文档和社区资源中自行探索。

扩展阅读
App Mesh 访问日志文档:
https://docs.aws.amazon.com/app-mesh/latest/userguide/envoy-logs.html
App Mesh 指标文档:
https://docs.aws.amazon.com/app-mesh/latest/userguide/envoy-metrics.html
Envoy 指标总览:
https://www.envoyproxy.io/docs/envoy/latest/operations/stats_overview
Envoy 错误消息列表:
https://www.envoyproxy.io/docs/envoy/latest/configuration/http/http_conn_man/response_code_details
本篇作者

于昺蛟
亚马逊云科技现代化应用解决方案架构师,负责亚马逊云科技容器和无服务器产品的架构咨询和设计。在容器平台的建设和运维,应用现代化,DevOps 等领域有多年经验,致力于容器技术和现代化应用的推广。
2022亚马逊云科技 re:Invent 全球大会
中国行现已开启!
点击下方图片即刻注册

听说,点完下面4个按钮
就不会碰到bug了!
