如何高效创建 C++ 并行构建?

在“CPPCon 2019”中,谷歌首席软件工程师 Chandler Carruth 的演讲《没有零成本的抽象》向大家展示了抽象与成本的关系。抽象需要运行时间、构建时间和人力成本。他清晰地向大家解释了使用 Arena 内存分配器降低运行时成本,反而导致构建成本增加的原因。他也提到,编译本质上是一个高度输出的分布式系统。但是,首先我们要如何建立这样一个系统的?如何有效地进行分布?如何创建高效的并行构建?欲知详情,请继续阅读…
知己知彼,百战百胜
你的构建时间以哪种度量单位计算?几秒、几分,还是几小时?在几秒钟内完成构建,这是每个程序员梦寐以求的事。正如我们把 WTK 的数据当做唯一有效的代码评审指标一样?,程序员耗费在喝咖啡等待构建完成的时间,也是衡量工作效率的一个有效指标。我希望这个时间不要超过 5 分钟。但该如何实现这个目标?大致有以下两种方法:
- 微观优化
- 宏观优化
微观优化,加速构建
使用 MSBuild 在命令行上执行构建时,你可能看到以下消息:
Building the projects in this solution one at a time. To enable parallel build, please add the “-m” switch.
在此解决方案中一次只能构建一个项目。要启用并行构建,请添加“-m”开关。
MSBuild 并行编译是通过 -m 开关启用的,并且我们可以限定并行构建的进程数量。如果未使用开关,则会收到上述消息;如果在使用 -m 开关时未限定具体的并行进程数值,则 MSBuild 默认设置为计算机上的处理器数量。
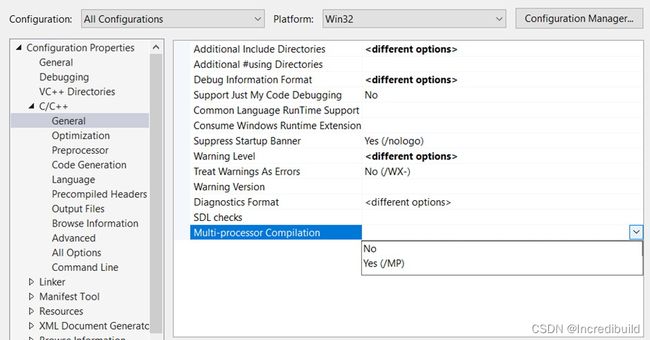
C++ 的 Visual Studio 并行构建需要在配置选项中设置。(项目属性 > C/C++ > 通用 > 多核并行编译,如图)
如果使用 Make 进行构建,请记住使用 -j 标志。此参数允许多个独立任务并行运行,减少构建时间。
对于 CMake 并行构建,你可以参考博客《现代 CMake 使用技巧》第 15 条(DRY 是我个人很喜欢遵循的一个原则,且不仅局限于软件工程领域)
使用预编译头文件可以大大加快后续构建的速度。在编译过程中,每个文件都会解析并概括成抽象语法树。这个语法树是解析文件的中间格式,另外,预编译头文件本身也是中间格式,保存着那些很少更改的头文件。顾名思义,对于预编译的头文件,解析和编译步骤都已避免,因此减少了项目构建时间。
美中不足的是,在分布式构建场景中,预编译头文件有时也会出错。预编译头不是并行构建的多个单元,而是聚合单元,因此任务无法并行处理。所以,如果需要重新编译预编译头文件,那么分布式构建反而拖累了进程。
因此,尽量保证每个编译单元的依赖关系简单清晰。在编译单元中,依赖关系可以通过类/结构引用、函数调用、相应头文件的 API 调用(标准系统库、STL、第三方库等)。如果已包含常见的头文件时,你可以进行如下间接引用:
这里有一些小诀窍——我向大家推荐一个可以减少头文件依赖性的小工具,叫做 include-what-you-use(可以顺便看看这篇讨论如何利用 include-what-you-use 的文章)。这个小工具最初用于谷歌源代码树,现在仍处于内测状态,但我用过,的确很方便。
如果你已经在 D:\Tools\IWYU 中安装了 include-what-you-use,可以参考下列内容,了解如何在 CMake 并行构建中使用这个工具:
CMake -H. -Bbuild -DCMAKE_CXX_INCLUDE_WHAT_YOU_USE=”D:\Tools\IWYU\include-what-you-use.exe;-Xiwyu;any;-Xiwyu;iwyu;-Xiwyu;–driver-mode=cl” -DCMAKE_C_INCLUDE_WHAT_YOU_USE=”D:\Tools\IWYU\include-what-you-use.exe;-Xiwyu;any;-Xiwyu;iwyu;-Xiwyu;–driver-mode=cl” -G “Ninja”
(你不用 CMake? 点击链接了解 CMake 相关博客)
这是有关格式问题的警告:
[2/72] Building CXX object CMakeFiles\mysecretproject\secret_vector_core.cpp.obj
…/secret_vector_core.cpp should add these lines:
#include
#include
#include
#include // for pow
…/secret_vector_core.cpp should remove these lines:
– #include
– #include // lines 7-7
The full include-list for …/secret_vector_core.cpp:
#include
#include
#include
#include
#include
#include
#include // for pow
—
以下是如何在 Windows 上使用 include-what-you-use 的建议:
- CMake 对 include-what-you-use 本地兼容,但请记住,如果源代码树同时包含 C 和 CPP 文件,则需要同时设定两个选项:CMAKE_CXX_INCLUDE_WHAT_YOU_USE 和CMAKE_C_INCLUDE_WHAT_YOU_USE
- 如果使用 Visual Studio 编译器进行构建,则需要设定 –driver mode=cl 参数
- 生成器必须是 Ninja,因为 Windows 默认的 Visual Studio 生成器不支持include-what-you-use。
宏观优化,加速构建
在开始介绍任何宏观优化加速 C 或 C++ 构建的内容之前,我想先说明一下。我是 Incredibuild 的技术首席官,我们公司的职责是为客户提供更快的构建方案。我们一开始只是帮助客户减少编译时间,现在,我们提供多种解决方案,包括编译速度、测试、代码分析、模拟等等,大幅提速持续集成周期。
加速构建的第一个宏观优化技术是多核并行处理器扩展。多核并行处理器局限于单一的机器中,但如果我们可以使用大量联网的计算机来分配工作进程呢? Incredibuild 等工具就完美实现这一点,帮助提高性能。
快速构建的第二个宏观优化技术,是优化持续集成管道的每个部分——无论是Azure DevOps 还是 Jenkins 构建。设置 Jenkins 并行构建就像配置一个主节点和两个从节点以上一样简单。向 Jenkins 节点添加分布式构建功能(使用Incredibuild)可以将构建节点转换为具有上百个内核的超级计算机,这些超级计算机可以使用本地网络中的空闲 CPU 或无缝扩展到公共云中。关于如何使用 Jenkins 声明式和命令式管道方法建立 Jenkins 并行构建的方法,网上有很多资料。但在大多数持续集成构建中,都涉及多个步骤,例如:签出分支、运行配置检查、执行 CMake 配置、执行 CMake 构建,甚至快速冒烟测试,确保构建质量过关。你必须优化管道中的每个阶段以提升构建速度。在这一点上,我强烈建议大家看看我之前关于左移策略的博客。
结论
凡事预则立,行以致远。准备和实践在编程中也至为关键。在任何项目中,都应该有技术领航人,了解优化如构建等普通任务的价值。这些任务看似微不足道,实则极大地影响了开发人员的工作效率。建立高效的并行构建并非易事,如果这已成为开发的瓶颈,建议使用 Incredibuild 等分布式处理技术。
点击获取试用 License !