2021泰迪杯B题数据处理4.1
文章目录
- 涉及需要处理的数据文件
- 任务 4 肥料产品的多维度对比分析
-
- 数据样式
- 最终需要处理的结果的样式
- 数据处理总共分为3部分
-
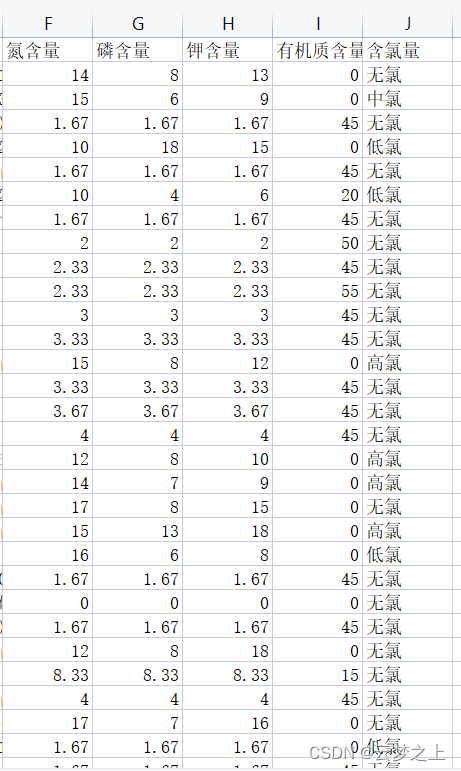
- ①获取氮磷钾的含量
- ②获取氯含量
- ③获取有机质含量
- ④程序执行导出结果
- 总结
涉及需要处理的数据文件
需要处理的文件:提取码zxcv
任务 4 肥料产品的多维度对比分析
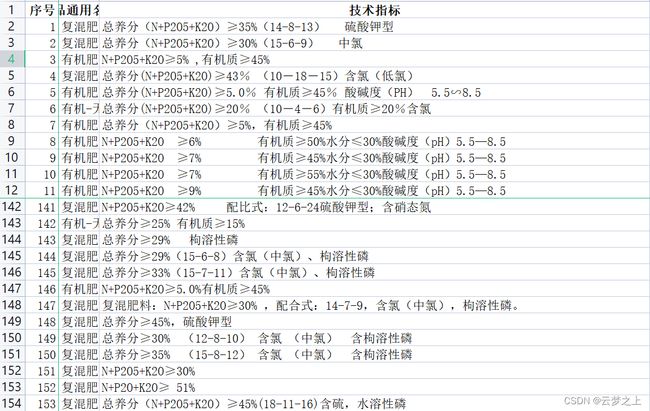
任务 4.1 设计算法或处理流程,从附件 4 技术指标中提取出氮、磷、钾养
分和有机质的百分比,以及肥料含氯的程度。请在报告中给出处理思路及过程,并将结果保存到文件“result4_1.xlsx”中。
注 如果技术指标中只给出总养分百分比(“≥”按照“=”处理)而无明
细数据,则氮、磷、钾养分的百分比按照总百分比的 1/3 来计算,结果保留 3 位小数(例如 1.0%,即 0.010)。复混肥料属于无机肥料,它的有机质百分比设定为 0。含氯情况分为“无氯”、“低氯”、“中氯”和“高氯”4 种。如果肥料
产品的技术指标中没有给出含氯情况,则视为“无氯”;如果注明“含氯”,则
视为“低氯".
数据样式
最终需要处理的结果的样式
数据处理总共分为3部分
①获取氮磷钾的含量
# _*_ coding:utf-8 _*_
# 作者:yunmeng
# 日期:2021年11月14日
import pandas as pd
import copy
import re
###获取氮磷钾的含量
def search_dan_lin_jia(str_li,fuhunfei):
for i in range(len(str_li)):
a = str_li[i].replace(' ', '').replace('%', '%').replace('―', '-').replace('(', '').replace(')', '') \
.replace(')', '').replace('(', '').replace('.0', '').replace('≧', '≥').replace('份','分').replace('总含量','总养分')
try:
sem0 = re.findall('O≥([0-9]*)%|≥([0-9]*)%N|总养分≥([0-9]*)%', a)[0]
sum1 = [j for j in sem0 if j != '']
if sum1 == []:
print(0, 0, 0)
continue
if re.findall('([0-9]*)-([0-9]*)-([0-9]*)', a) == []:
dan = round(int(sum1[0]) / 3, 2)
lin = round(int(sum1[0]) / 3, 2)
jia = round(int(sum1[0]) / 3, 2)
df.loc[fuhunfei['序号'] == i + 1, ['氮含量']] = dan
df.loc[fuhunfei['序号'] == i + 1, ['磷含量']] = lin
df.loc[fuhunfei['序号'] == i + 1, ['钾含量']] = jia
print(dan, lin, jia)
else:
dan = int(re.findall('([0-9]*)-([0-9]*)-([0-9]*)', a)[0][0])
lin = int(re.findall('([0-9]*)-([0-9]*)-([0-9]*)', a)[0][1])
jia = int(re.findall('([0-9]*)-([0-9]*)-([0-9]*)', a)[0][2])
df.loc[fuhunfei['序号'] == i + 1, ['氮含量']] = dan
df.loc[fuhunfei['序号'] == i + 1, ['磷含量']] = lin
df.loc[fuhunfei['序号'] == i + 1, ['钾含量']] = jia
print(dan, lin, jia)
except:
print(0, 0, 0)
②获取氯含量
###获取氯含量
def search_cl (str_li,fuhunfei):
for i in range(len(str_li)):
a = str_li[i].replace(' ', '').replace('%', '%')
signal_one=re.findall('含氯',a)
signal_two=re.findall('(.氯)',a.replace('含氯',''))
if signal_two!=[]:
# i['含氯量'] = signal_two[0]
df.loc[fuhunfei['序号'] == i + 1, ['含氯量']] = signal_two[0]
elif signal_one!=[]:
# i['含氯量'] = '低氯'
df.loc[fuhunfei['序号'] == i + 1, ['含氯量']] = '低氯'
③获取有机质含量
def search_organical (str_li,fuhunfei):
for i in range(len(str_li)):
a = str_li[i].replace(' ', '').replace('%', '%')
value=re.findall('有机质≥([0-9]*).', a)
if value!=[]:
# fuhunfei['有机质含量'] = value[0]
df.loc[fuhunfei['序号'] == i+1, ['有机质含量']] = value[0]
else:
print(0)
④程序执行导出结果
if '__name__'=='main':
da = pd.read_excel(r'D:\Users\yunmeng\PycharmProjects\数据分析\泰迪\2021泰迪题目\B题\相关文件\附件4.xlsx', header=0, sheet_name=0)
df = copy.deepcopy(da)
df['氮含量'] = 0
df['磷含量'] = 0
df['钾含量'] = 0
df['有机质含量'] = 0
df['含氯量'] = "无氯"
df['技术指标']
str_li = df['技术指标'].astype('str').to_list()
search_organical(str_li,df)
search_dan_lin_jia(str_li,df)
search_cl(str_li,df)
df.to_csv(r'C:\Users\yunmeng\Desktop\4.1.csv')
总共处理的数据200条,剩下20条因为数据实在太乱了所以需要自己手动修改。

总结
首先时对任务分为3个块进行设计函数
重要的地方在于,对于数据的预处理,一开始很多数据不规范,如果在设计代码的时候调整效率会很低得改来改去。因此一开始要做的时尽可能规范化数据
包括
对空格进行替换,对输入错误的字进行替换,对同种类型的词语进行替换,这些都是为了后期的准确字符匹配做准备。
a = str_li[i].replace(' ', '').replace('%', '%').
replace('―', '-').replace('(', '').replace(')', '')
.replace(')', '').replace('(', '').replace('.0', '').
replace('≧', '≥').replace('份','分').
replace('总含量','总养分')
我这里的一大堆代码就是后期不断发现的错误。而这应该是一开始需要注意的点,可以先观察用excel进行替换,减小后续的任务量。