【读点论文】PP-ShiTu: A Practical Lightweight Image Recognition System,百度推出的强大人工智能产品
PP-ShiTu: A Practical Lightweight Image Recognition System
图像识别,是指利用计算机对图像进行处理、分析和理解,以识别各种不同模式的目标和对象的技术,是应用深度学习算法的一种实践应用。图像的传统识别流程分为四个步骤:图像采集→图像预处理→特征提取→图像识别。在于特征提取阶段,利用传统的分类网络,需要提前在训练集中补充所需识别的类别的训练图片,一旦有新增的类别就需要对模型重新训练,无论是训练成本还是数据成本都很高。
Metric Learning可以借助一系列观测,根据不一样的任务来自主学习出针对某个特定任务的度量距离函数,通过计算两张图片之间的相似度,使得输入图片被归入到相似度大的图片类别中去,从而学习数据间的的距离或差异,有效地描述样本之间的相似度。相比于传统的识别网络是丢弃经典神经网络最后的softmax层,改成直接输出feature vector,去特征库里面按照Metric Learning寻找最近邻的类别作为匹配项。
拥有了强大的特征提取网络,一套完美的识别系统当然也少不了高效的检索模块。在PP-ShiTu中,PaddleClas使用了经过广泛验证并且能够适配于多端多平台的检索系统:faiss。
避免每次新增类别重新训练的困难,并且对于样本数量很少的类别,在拥有了较好的特征提取网络的前提下,能够直接将小样本数据补充进特征检索库,避免了训练集的大量数据要求,从而实现识别效果。
图像识别一共包含4个步骤
- 准备好需要识别的图片;
- 通过主体检测模型,定位主体所在位置;
- 利用metric learning进行特征提取;
- 经过检索快速匹配最相似结果。

Abstract
在不同的领域出现了大量的研究和技术,如人脸识别、行人和车辆重新识别、地标检索和产品识别。本文提出了一个实用的轻量级图像识别系统PP-ShiTu,它由主体检测、特征提取和向量搜索三个模块组成。
引入了度量学习、深度哈希、知识提取和模型量化等流行策略,以提高准确性和推理速度。
PP_ShiTu可以在不同的场景中很好地工作,并在混合数据集上训练一组模型。在不同的数据集和基准测试上的实验表明,该系统在不同的图像识别领域具有广泛的有效性。
PP-ShiTu引入目标检测、度量学习、图像检索等技术,并将每个模块性能最大化,才构建成了统一、通用的图像识别系统
图像识别任务实际产业落地过程中又面临很多实际难点:
- 识别类别数以万计!
- 细分类差别极其细微,实际图像角度多变刁钻
- 算法上线运行速度要求极高
Introduction
本文提出了一个实用的轻量级图像识别系统PP-ShiTu。介绍了一个通用的管道和实用的策略,包括PP-PicoDet、UDML、Arcmargin loss和DeepHash。
图像识别是计算机视觉的一项普遍任务。得益于深度学习的快速发展和巨大的市场需求,图像识别得到了迅速的发展,并发展成多个子领域。
PP-ShiTu中使用PP-PicoDet模型作为主体检测算法,PP-PicoDet模型性能和速度均达到业内SOTA的水平,为整个识别系统实现精准高效识别打下了坚实的基础。
在特征提取的训练阶段,PP-ShiTu通过使用度量学习,更好地解决高相似度物体的区分问题。不仅如此,PP-ShiTu所使用的骨干网络PP-LCNet作为业内SOTA模型,大幅度提升预测速度的同时,还提高了精度,并且可能直接支持多种应用方向和场景!
许多应用程序使用类似的管道,例如人脸识别、行人和车辆重新识别、地标识别、产品识别等。此外,在一个应用程序中工作的策略通常对其他应用程序也是有效的。
将策略迁移到另一个应用程序时,成本很高。鉴于此,提出了PP-ShiTu图像识别系统来解决同一管道中的类似问题。下图展示了PP-ShiTu的框架。PP-ShiTu包含三个模块,即主体检测、特征提取和向量搜索。
- 首先,获取图像时,我们首先检测一个或多个主体区域找到图像的主要区域。
- 然后使用CNN模型从这些区域提取特征。特征是浮点数向量或二元向量。根据度量学习理论,特征意味着两个对象的相似性。两个特征之间的距离越短,原始两个对象就越相似。
- 最后,使用向量搜索算法在图库中找到与我们从图像中提取的特征最接近的特征,并使用相应的标签作为我们的识别结果。
除了构建通用管道,还在系统中引入了一些有效的策略。使用带有PP_LCNet主干的PP_Picodet作为主体检测模型的主干。采用具有度量学习策略的PP_LCNet,知识提炼策略在系统中得到了广泛的应用。使用SSLD蒸馏策略训练的主干,还使用SSLD训练特征提取模型。模型量化帮助减少模型的存储大小。使用DeepHash策略压缩特征,以加速向量搜索。烧蚀实验表明了上述策略的有效性。
还训练了主体检测模型和将多个数据集混合在一起的混合数据集特征提取模型。PP ShiTu在不同的场景下都能很好地工作,并在许多数据集和基准测试中获得有竞争力的结果。

Modules and Strategies
Mainbody Detection
主体检测技术是一种应用广泛的检测技术,指的是检测图像中所有前景物体。主体检测是整个识别任务的第一步,可以有效提高识别精度。
物体检测方法多种多样,如常用的两级探测器(FasterRCNN系列等)、单级探测器(YOLO、SSD等)、无锚探测器(PP PicoDet、FCOS等)等。PadleDetection为服务器端场景开发了PP-YOLOv2模型,为端端场景(CPU和移动设备)开发了PP-PicoDet模型,这两种模型在各自的场景中都是SOTA。
通过结合许多优化技巧,如Drop Block、Matrix NMS、IoU损耗等,PP-YOLOv2在准确性和效率上都超过了YOLOv5。PP_PicoDet以PP_LCNet为主干,并结合了许多其他检测器训练技巧,如PAN FPN、CSP Net、SimOTA,最终成为第一个在输入大小为416时在1M参数范围内mAP(0.5:0.95)超过COCO数据集0.30+的对象检测器。
轻量级图像识别系统需要一个轻量级的主体检测模型。因此,在PP_ShiTu中使用PP_PicoDet。
Lightweight CPU Network (PP-LCNet)
- 为了在英特尔CPU上获得更好的精度和速度权衡,在比较不同网络推断的基础上获得了一个基本网络,并添加了不同的方法来进一步提高该网络的精度,从而产生了PP_LCNet,它提供了一种更快速、更准确的识别算法,并启用了mkldnn。
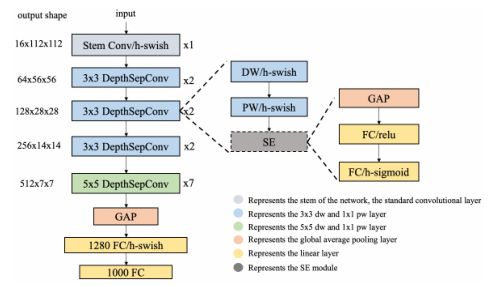
- 上图为PP_LCNet网络结构。虚线框代表可选模块。茎部采用标准的3×3卷积。DepthSepConv表示深度可分离卷积,DW表示深度卷积,PW表示逐点卷积,GAP表示全局平均池。
- mkldnn:mkldnn是intel开发的开源项目,就是针对cpu上运行神经网络做了一些并行优化; 是用于深度神经网络的英特尔数学核心库,是一款面向深度学习应用的开源性能库。该库包括针对英特尔架构处理器和英特尔处理器显卡优化的神经网络的基本构建模块。
Better activation function
为了提高BaseNet的匹配能力,在原有ReLU的基础上,用H-Swish替换了网络中的激活函数,在推理时间略有增加的情况下,可以显著提高准确度。
Swish 激活函数已经被证明是一种比 ReLU 更佳的激活函数,但是相比 ReLU,它的计算更复杂,因为有 sigmoid 函数。为了能够在移动设备上应用 swish 并降低它的计算开销, 提出了 h-swish。β是个常数或可训练的参数.Swish 具备无上界有下界、平滑、非单调的特性。所以Swish函数可以看做是介于线性函数与ReLU函数之间的平滑函数.
- 【激活函数】h-swish激活函数详解_Roaddd的博客-CSDN博客_h-swish激活函数
s w i s h ( x ) = x ∗ δ ( β x ) h − s w i s h [ x ] = x ∗ R e L U 6 ( x + 3 ) 6 swish(x)=x*\delta(\beta{x})\\ h-swish[x]=x*\frac{ReLU6(x+3)}{6} swish(x)=x∗δ(βx)h−swish[x]=x∗6ReLU6(x+3)
ReLU6:ReLU6就是普通的ReLU但是限制最大输出值为6(对输出值做clip),这是为了在移动端设备float16的低精度的时候,也能有很好的数值分辨率,如果对ReLU的激活范围不加限制,输出范围为0到正无穷,如果激活值非常大,分布在一个很大的范围内,则低精度的float16无法很好地精确描述如此大范围的数值,带来精度损失。 R e L U 6 = m i n ( m a x ( f e a t u r e s , 0 ) , 6 ) ReLU6=min(max(features,0),6) ReLU6=min(max(features,0),6).
SE modules at appropriate positions
是一种对网络通道进行加权以获得更好功能的好方法,并被用于许多轻量级网络,如MobileNetV3。然而,在英特尔CPU上,SE模块会增加推理时间,因此无法将其用于整个网络。
事实上,通过大量实验发现越靠近网络的尾部,SE模块就越有效。因此,只需将SE模块添加到网络尾部附近的块中,就可以实现更好的精度速度平衡。SE模块中两层的激活功能是ReLU和H-Sigmoid有效。
SENet是Squeeze-and-Excitation Networks的简称,拿到了ImageNet2017分类比赛冠军,其效果得到了认可,其提出的SE模块思想简单,易于实现,并且很容易可以加载到现有的网络模型框架中。SENet主要是学习了channel之间的相关性,筛选出了针对通道的注意力,稍微增加了一点计算量,但是效果比较好。
其中Fsq(·)为压缩操作,这个操作就是一个全局平均池化(global average pooling)。经过压缩操作后特征图被压缩为1×1×C向量。
Fex(·,W)为激励操作**(Excitation)**:由两个全连接层组成,其中SERatio是一个缩放参数,这个参数的目的是为了减少通道个数从而降低计算量。
- 第一个全连接层有C*SERatio个神经元,输入为1×1×C,输出1×1×C×SERadio。
- 第二个全连接层有C个神经元,输入为1×1×C×SERadio,输出为1×1×C。
Fscale(·,·)为scale操作:在得到1×1×C向量之后,就可以对原来的特征图进行scale操作了。很简单,就是通道权重相乘,原有特征向量为W×H×C,将SE模块计算出来的各通道权重值分别和原特征图对应通道的二维矩阵相乘,得出的结果输出。
SE模块首先对卷积得到的特征图进行Squeeze操作,得到channel级的全局特征,然后对全局特征进行Excitation操作,学习各个channel间的关系,也得到不同channel的权重,最后乘以原来的特征图得到最终特征。
SE模块是在channel维度上做attention或者gating操作,这种注意力机制让模型可以更加关注信息量最大的channel特征,而抑制那些不重要的channel特征。另外一点是SE模块是通用的,这意味着其可以嵌入到现有的网络架构中。
Larger convolution kernels
- 卷积核的大小往往会影响网络的最终性能。在mixnet中分析了不同大小的卷积核对网络性能的影响,最终在网络的同一层中混合了不同大小的卷积核。然而,这种混合会减慢模型的推理速度,因此尝试增加卷积核的大小,但尽量减少推理时间的增加。最后,将网络尾部卷积核的大小设置为5×5。
Larger dimensional 1 × 1 conv layer after GAP
- 在PP_LCNet中,间隙后网络的输出维数较小,直接连接最终的分类层将失去特征的组合。为了使网络具有更强的匹配能力,在间隙层和最终分类层之间插入了一个1280维的1x1conv,这在不增加推理时间的情况下为模型提供了更多的存储空间。
PP-PicoDet
PP_PicoDet是PaddleDetection开发的一系列新的目标检测模型。对于主干模型,使用了上述PP_LCNet,这有助于提高检测器的推理速度和映射。
对anchor-free策略在轻量型目标检测模型中的应用进行了探索;对骨干结构进行了增强并设计了一种轻量型Neck结构以提升模型的特征提取能力;对label assignment策略与损失函数进行了改进以促进更稳定、更高效的训练。通过上述优化,构建了一类实时目标检测器PP-PicoDet,它在移动端设备上取得了非常优异的性能。
对于颈部,将CSP网络与PAN-FPN相结合,开发了一种称为CSP-PAN的新FPN结构,这有助于增强特征图提取能力。用SimOTA,并在网络训练过程中使用改进的GFocal loss功能。 此外,还对PP-PicoDet进行了一些经验改进。例如,在FPN中使用5x5内核的深度卷积,而不是3x3,因为它可以将mAP提高0.5%,并且几乎不影响推理速度。更多细节可以在网上看到。对于主体检测任务,所有对象都被视为前景,因此标签列表中只有一个名为前景的类。
- FPN 高维度向低维度传递语义信息(大目标更明确)
- PAN 低维度向高维度再传递一次语义信息(小目标也更明确)
在实际应用中,海量的图像、视频特征不仅会消耗巨大的存储空间,而且检索时间极长,给图像识别的最后一公里设下路障。PP-ShiTu则是结合DeepHash和度量学习,甚至在检索库特征数量大于10万时,依然使得所需的存储空间减少32倍,检索速度提高5倍以上。
- 度量学习(metric learning)研究如何在一个特定的任务上学习一个距离函数,使得该距离函数能够帮助基于近邻的算法(kNN、k-means等)取得较好的性能。
- 深度度量学习(deep metric learning)是度量学习的一种方法,它的目标是学习一个从原始特征到低维稠密的向量空间(称之为嵌入空间,embedding space)的映射,使得同类对象在嵌入空间上使用常用的距离函数(欧氏距离、cosine距离等)计算的距离比较近,而不同类的对象之间的距离则比较远。深度度量学习在计算机视觉领域取得了非常多的成功的应用,比如人脸识别、人脸验证、图像检索、签名验证、行人重识别等。
除此以外PP-ShiTu使用的向量搜索模块Faiss,可以更好地适应多平台的需求(Linux, Windows, MacOs),为实际应用提供灵活选择。




Feature Extraction
图像识别的主要问题是如何从模型中提取更好的特征。因此,特征提取的能力直接影响图像识别的性能。在特征提取的训练阶段,使用度量学习方法来学习图像的特征。
Additive Angular Margin Loss (ArcMargin loss)
度量学习试图将数据映射到一个嵌入空间,在这个空间中,相似的数据靠得很近,而不同的数据相隔很远。在度量学习中,特征的质量取决于损失、主干、数据质量和数量以及训练策略。损失是度量学习中最重要的部分。
度量学习的损失分为两种类型,即基于损失分类的损失和基于配对的损失。由于改进版的基于分类的损失更为稳健,这类损失已被越来越多地使用。在PP-ShiTu中,使用ArcMargin损耗,这是基于Softmax损耗的改进。Arcmargin的损失,该损失使角度空间中的分类极限最大化,从而更好地提取和组织特征。
L = − 1 N ∑ i = 1 N l o g e s ( c o s ( θ y i + m ) ) e s ( c o s ( θ y i + m ) ) + ∑ j = 1 , j ≠ y i n e s ∗ c o s θ j L=-\frac{1}{N}\sum_{i=1}^{N}log\frac{e^{s(cos(\theta_{y_i}+m))}}{e^{s(cos(\theta_{y_i}+m))}+\sum_{j=1,j\neq{y_i}}^{n}e^{s*cos\theta_j}} L=−N1i=1∑Nloges(cos(θyi+m))+∑j=1,j=yines∗cosθjes(cos(θyi+m))
其中θj是权重和特征之间的角度。批次大小和类别号分别为N和n。m是目标角度 θ y i θ_{yi} θyi上的角裕度惩罚,s是特征尺度。
Unified-Deep Mutual Learning (U-DML)
深度相互学习是一种两个学生网络相互学习的方法,知识提炼不需要具有预先训练权重的更大教师网络。在DML中,对于图像分类任务,损失函数包含两部分:
- 学生网络和 groundtruth之间的损失函数。
- Kullback–Leibler divergence (KL-Div) loss在学生网络的输出soft labels。
Hard Label vs Soft Label
- hard label更容易标注,但是会丢失类内、类间的关联,并且引入噪声。
- soft label给模型带来更强的泛化能力,携带更多的信息,对噪声更加鲁棒,但是获取难度大。
Label Smoothing
Softmax Cross Entropy不仅可以做分类任务(目标为one-hot label),还可以做回归任务(目标为soft label)。设网络输出的softmax prob为p,soft label为q,那Softmax Cross Entropy定义为:
- ζ = − ∑ k = 1 K q k l o g ( p k ) \zeta=-\sum_{k=1}^{K}q_klog({p_k}) ζ=−k=1∑Kqklog(pk)
Label Smoothing虽然仍是做分类任务,但其目标q从one-hot label变为soft label了,原来是1的位置变为 1 − α 1-\alpha 1−α , 其他的原来是0的位置变为 α / ( K − 1 ) \alpha/(K-1) α/(K−1) , α \alpha α通常取0.1。InfoNCE的损失函数,InfoNCE可以拆分成两个部分,alignment和uniformity。
- alignment部分只跟positive pair相关,希望positive pair的feature拉近,uniformity部分只跟negative pair相关,希望所有点的feature尽可能均匀分布在unit hypersphere上。
从softmax和InfoNCE损失函数上理解,把InoNCE公式的分母想象成soft label的所有位置相加,也就是最大值的那个位置可以看成是positive pair,其他位置都可以看成是negative pair,softmax的损失函数不是跟InfoNCE损失函数一模一样,异曲同工!也就是说hard label可以认为只有positive pair,而soft label仍然保留negative pair。因此,soft label更容易避免退化解问题。Softmax Cross Entropy 的loss曲线其实跟sigmoid类似,越靠近1的时候,loss曲线会越平缓
从softmax的损失函数曲线上理解,hard label监督下,由于softmax的作用,one-hot的最大值位置无限往1进行优化,但是永远不可能等于1,从上图可知优化到达一定程度时,优化效率就会很低,到达饱和区。而soft label可以保证优化过程始终处于优化效率最高的中间区域,避免进入饱和区。
Knowledge Distillation(知识蒸馏)
knowledge distillation相比于label smoothing,最主要的差别在于,知识蒸馏的soft label是通过网络推理得到的,而label smoothing的soft label是人为设置的。



 > >
> >
原始训练模型的做法是让模型的softmax分布与真实标签进行匹配,而知识蒸馏方法是让student模型与teacher模型的softmax分布进行匹配。后者比前者具有这样一个优势:经过训练后的原模型,其softmax分布包含有一定的知识——真实标签只能告诉我们,某个图像样本是一辆宝马,不是一辆垃圾车,也不是一颗萝卜;而经过训练的softmax可能会告诉我们,它最可能是一辆宝马,不大可能是一辆垃圾车,但绝不可能是一颗萝卜。
知识蒸馏得到的soft label相当于对数据集的有效信息进行了统计,保留了类间的关联信息,剔除部分无效的冗余信息。 相比于label smoothing,模型在数据集上训练得到的soft label更加可靠。
蒸馏过程使用了学生网络和教师网络之间的特征映射距离。在学生网络特征图上执行转换,以保持特征图对齐。 为了避免教师模型训练过程过于耗时,本文在DML的基础上,提出了U-DML,在提取过程中对特征映射进行监督。
蒸馏过程有两个网络:学生网络和教师网络。它们具有完全相同的网络结构和不同的初始权重。其目标是,对于相同的输入图像,两个网络可以得到相同的输出,不仅对于预测结果,而且对于特征映射。
总损失函数由三部分组成:
- 边际损失。由于这两个网络的颈部和头部都是从零开始训练的,所以可以利用弧裕度损失来实现网络的收敛;
- DML损失。两个网络的最终输出分布预计相同,因此需要DML损耗以确保两个网络之间分布的一致性;
- 特征损失 。这两个网络的结构是相同的,因此它们的特征映射应该是相同的,特征丢失可以用来约束两个网络的中间特征映射距离。
L o s s a r c = A r c m a r g i n ( S h o u t , g t ) + A r c m a r g i n ( T h o u t , g t ) Loss_{arc}=Arcmargin(S_{hout},gt)+Arcmargin(T_{hout},gt) Lossarc=Arcmargin(Shout,gt)+Arcmargin(Thout,gt)
- 其中 S h o u t S_{hout} Shout表示学生网络的头部输出, T h o u t T_{hout} Thout表示教师网络的头部输出。gt提供输入图像的GroundTruth标签。
DML loss:在DML中,每个子网络的参数分别更新。在这里,为了简化训练过程,计算两个子网络之间的KL散度损失,并同时更新所有参数。DML损失如下所示。
L o s s d m l = K L ( S p o u t ∣ ∣ T p o u t ) + K L ( T p o u t ∣ ∣ P p o u t ) 2 Loss_{dml}=\frac{KL(S_{pout}||T_{pout})+KL(T_{pout}||P_{pout})}{2} Lossdml=2KL(Spout∣∣Tpout)+KL(Tpout∣∣Ppout)
其中KL(p||q)表示p和q的KL散度。Spout和Tpout可计算: S p o u t = S o f t m a x ( S h o u t ) , S p o u t = S o f t m a x ( S h o u t ) S_{pout}=Softmax(S_{hout}),S_{pout}=Softmax(S_{hout}) Spout=Softmax(Shout),Spout=Softmax(Shout)
Feature loss:在训练过程中,希望学生网络的主干输出与教师网络的主干输出相同。因此,与Overhaul类似,特征损失用于蒸馏过程。损失的计算方法: L o s s f e a t = L 2 ( S b o u t , T b o u t ) Loss_{feat}=L2(S_{bout},T_{bout}) Lossfeat=L2(Sbout,Tbout) 。其中 S b o u t S_{bout} Sbout表示学生网络的主干输出, T b o u t T_{bout} Tbout表示教师网络的主干输出。这里使用了均方误差损失。值得注意的是,对于特征损失,不需要进行特征映射变换,因为用于计算损失的两个特征映射完全相同
U-DML训练过程的总损失: L o s s t o t a l = L o s s a r c + l o s s d m l + L o s s f e a t Loss_{total}=Loss_{arc}+loss_{dml}+Loss_{feat} Losstotal=Lossarc+lossdml+Lossfeat。
DeepHash
- 实际应用中,海量的检索图像和视频特征数据库不仅会消耗巨大的存储空间,而且会导致检索时间过长,在某些应用场景中是不可接受的。移动设备上的存储空间有限,这对海量功能存储提出了进一步的挑战。考虑到这一点,除了PP _Shitu的度量学习功能,我们还集成了DeepHash功能,这有助于减少存储并加快检索 .
- DeepHash研究如何利用deep神经网络获取具有代表性的二值特征,deep神经网络使用位存储二值特征,并采用Hamming距离来度量两个特征向量之间的距离。
- 采用优化的DSHSD算法来获得用于商品识别的实用二进制特征。与实值模型相比,检索精度可能略有下降,但当搜索库规模大于10万时,库特征的存储空间可减少32倍,检索速度可提高5倍以上。

Vector Search
为了在多个操作系统上运行,包括Linux、Windows和MacOS,我们使用Faiss作为向量搜索模块,这是一个用于高效相似性搜索的库,包含支持在任意大小的向量集合中搜索的算法,最多支持在RAM中可能不适合的向量集合。在PP_ShiTu中,选择了三种算法,HNSW32、IVF和FLAT,以满足不同场景的需求。值得注意的是,在矢量搜索之前需要建立一个功能库。特征库由从标记图像中提取的特征组成。在PP-ShiTu管道中,通过相似性搜索从特征库中获取查询标签。
HNSW32:Hierarchical NSW (分层的NSW算法),是近似k近邻搜索中的新方法,也是对NSW方法的改进,它由多层的邻近图组成,因此称为分层的NSW方法。
信息搜索的一种常用方法是:K-Nearest Neighbor Search(K-NNS)。K-NNS假设你具有一个已定义好的关于数据元素之间的距离函数(distance function),目标是:为一个query从数据集中寻找K个具有最小distance的elements。
K-NNS的一种naive方法是:计算query与数据集中的每个element的距离,并选择具有最小距离的elements。不幸的是,naive方法的复杂度与所存储的elements的总数是成线性增长的,这使得它在大规模数据集上是不可行的。
由于“维数灾难”,当只有考虑相对低维的数据时,K-NNS的exact方法可以提供一个较大的搜索加速。为了克服该问题,提出了近似最近邻搜索(Approximate Nearest Neighbors Search (K-ANNS) ),它允许存在一小部分的错误(errors),从而放宽exact search的条件。
inexact search(recall)的质量被定义成(true NN数目/K数目)的比值。最流行的K-ANNS解法有:基于树的近似版本、LSH、以及PQ(乘积量化:product quantization)。在高维数据集上,邻近图K-ANNS算法由于良好的表现最近变得流行起来。然而,在低维或聚类数据上,邻近图路由(proximity graph routing)的幂律扩展(power-law scaling)会造成严重性能下降。
提出了Hierarchical Navigable Small World(Hierarchical NSW, HNSW),一种基于增量K-ANNS结构的新的完全图,可以提供更好的对数复杂度扩展(logarithmic complexity)。主要贡献有:
- 图的入点节点(enter-point node)的显式选取(explicit selection)
- 通过不同尺度(scales)将连接(links)进行分离
- 使用一个高级的启发法(heuristic)来选择neighbors
HNSW算法可以被看成是一种使用邻近图(proximity graphs,而非链表)的概率型跳表结构(probabilistic skip list structure)的扩展。效果评估表明,针对常用指标空间(general metric space)提出的该方法,效果要好于只应用于向量空间的state-of-the-art方法。
- Hierarchical NSW算法的思想是:将links根据它们的length scale分离到不同的layers上,接着以multilayer graph的形式进行search。在该case中,只需为每个element评估一个固定数目的connections(独立于networks size),从而允许一个log scalability。在这样的structure中,搜索会从upper layer开始(它具有最长的links)(即:“zoom-in”阶段)。该算法会贪婪地遍历upper layer中的elements,直到到达一个local minimum。接着,该search会切换到lower layer(它具有更短的links);然后从在前一layer上具有local minimum的element进行restart,并重复该过程。在所有layers中的每个element上的connections的最大数目是常量,这样可以允许在NSW网络路由中进行一个log scaling复杂度。

- search会从top layer的一个element开始(红色部分)。红色箭头表示greedy算法的方向,从entry point到该query(绿色部分)
- 输入索引路径和图片;
- 根据索引路径加载索引,并对图片提取特征;
- 获取需要搜索的近邻数K,并将图片特征作为节点输入搜索算法;
- 在L层找到距离q最近的一个节点ep,并作为下一层的输入;
- 在l=2层中,从ep开始,在ep的邻居中找到距离q最近的一个邻居,作为新的ep,并作为下一层的输入;
- 在l=1层中,从ep开始,在ep的邻居中找到距离q最近的一个邻居,作为新的ep,并作为下一层的输入;
- 在最底层中,从ep开始,搜索距离q最近的K个节点;
- 输出节点q和K个近邻。
IVF(inverted file system)
- 个性化推荐系统中,常见的流程为 召回->粗排->精排->重排 四阶段。当前的召回阶段通常为向量化召回,即一切皆用embedding来表示。
- 在保证一定的精度的前提下,尽可能的提高向量计算的效率。
- 结合聚类算法,将源数据N进行聚类,计算每个簇的簇心Ci于待搜索的向量Q进行距离计算,得到距离最近的的一个簇C1,接下来仅需要计算C1中所有元素于Q之间的距离即可。平均搜索计算次数:C+N/C
- 使用Faiss的时候首先需要基于原始的向量build一个索引文件,然后再对索引文件进行一个查询操作,在第一次build索引文件的时候,需要经过Train和Add两个过程,后续如果有新的向量需要被添加到索引文件的话还可以有一个Add操作从而实现增量build索引,但是如果增量的量级与原始索引差不多的话,整个向量空间就可能发生了一些变化,这个时候就需要重新build整个索引文件,也就是再用全部的向量来走一遍Train和Add,至于具体是怎么Train和Add的,就关系到Faiss的核心原理了。
- Faiss的核心原理其实就两个部分:Product Quantizer, 简称PQ,Inverted File System, 简称IVF.
PQ(Product Quantization)
- 降低计算次数,允许一定精度损失。
- 中文名乘积量化。他解决了啥问题?他进行了向量压缩。PQ有一个Pre-train的过程,一般分为两步操作,第一步是Clustering,第二部是Assign,这两步合起来就是对应到前文提到Faiss数据流的Train阶段,可以以一个128维的向量库为例:


- 在做PQ之前,首先需要指定一个参数M,这个M就是指定向量要被切分成多少段,所以M一定要能整除向量的维度,在上图中M=4,所以向量库的每一个向量就被切分成了4段,然后把所有向量的第一段取出来做Clustering得到256(假如)个簇心,再把所有向量的第二段取出来做Clustering得到256个簇心,直至对所有向量的第N段做完Clustering,从而最终得到了256*M个簇心,做完Clustering就开始对所有向量做Assign操作。
- 这里的Assign就是把原来的N维的向量映射到M个数字,以N=128,M=4为例,首先把向量切成四段,然后对于每一段向量,都可以找到对应的最近的簇心 ID,4段向量就对应了4个簇心 ID,一个128维的向量就变成了一个由4个ID组成的向量,这样就可以完成了Assign操作的过程。
- 完成了PQ的Pre-train,就可以看看如何基于PQ做向量检索了。
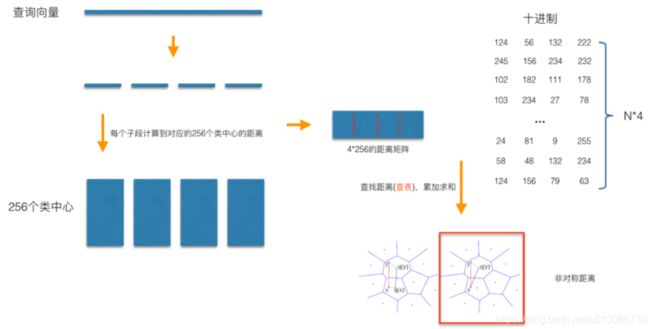
- 同样是以N=128,M=4为例,对于每一个查询向量,以相同的方法把128维分成4段32维向量,然后计算每一段向量与之前预训练好的簇心的距离,得到一个4*256的表,就可以开始计算查询向量与库里面的向量的距离,而PQ优化的点就在这里,在计算查询向量和向量库向量的距离的时候,向量库的向量已经被量化成M个簇心 ID,而查询向量的M段子向量与各自的256个簇心距离已经预计算好了,所以在计算两个向量的时候只用查M次表,比如的库里的某个向量被量化成了[124, 56, 132, 222], 那么首先查表得到查询向量第一段子向量与其ID为124的簇心的距离,然后再查表得到查询向量第二段子向量与其ID为56的簇心的距离。最后就可以得到四个距离d1、d2、d3、d4,查询向量跟库里向量的距离d = d1+d2+d3+d4。所以在提出的例子里面,使用PQ只用4×256次128维向量距离计算加上4xN次查表,而最原始的暴力计算则有N次128维向量距离计算,很显然随着向量个数N的增加,后者相较于前者会越来越耗时。
Experiments
- Datasets
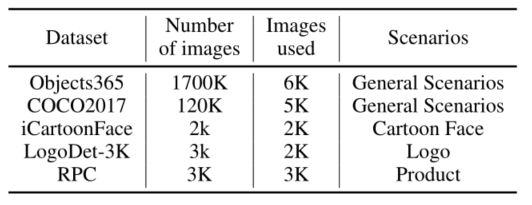
- 使用了很多不同场景的公共数据集来训练我们的模型,在主体检测训练过程中,使用了5个公共数据集:Objects365、COCO2017、iCartoonFace、LogoDet-3k和RPC。
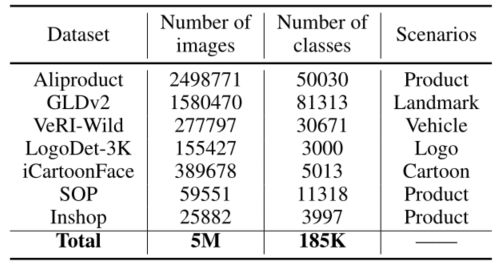
- General Recognition:使用7个公共数据集,包括Aliproduct、GLDv2、VeRI Wild、LogoDet-3K、iCartoonFace、SOP、Inshop。这些数据集还用于一般训练、模型提取和深度散列。
- Test set :为了评估PP_ShiTu的速度,发布了一个由查询图像集和特征库组成的测试集。从互联网上收集了200幅图像作为查询集。查询数据集可以在GitHub存储库中找到。对于gallery,结合使用Products10k和从互联网下载的一些常见物品,并使用image gallery构建功能库。查询集中的每个图像至少包含一个gallery中的对象。
- Ablation study
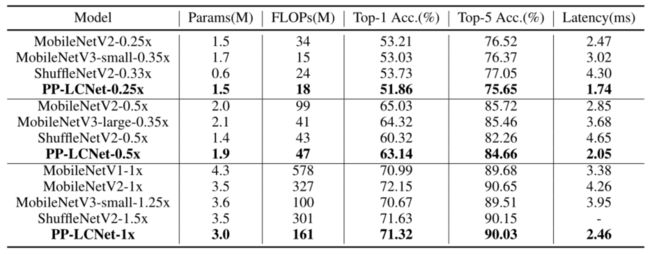
- PP_LCNet的消融研究:为了测试模型的泛化能力,在整个模型设计过程中使用了具有挑战性的数据集,如ImageNet-1k。PPLCNet和其他有竞争力的轻量级机型之间的精度和速度比较。PP_LCNet在速度和准确性方面都具有显著优势,即使与MobileNetV3这样的竞争非常激烈的网络相比也是如此。
- 比较最先进的轻量级网络的分类精度。在批量大小为1且启用了MKLDNN的Intelr Xeonr Gold 6148处理器上测试的延迟,线程数为10。 (mkldnn的作用是为cpu运行网络加速;)
- Ablation study for U-DML:基于通用的PP_LCNet-2.5x识别模型,对U-DML进行了消融研究,并进行了一些实验。该训练策略与基本PP-LCNet-2.5x识别模型训练过程几乎相同,只是采用了蒸馏损失。
- 没有微调模型训练过程中的任何超参数,例如损失率。更重要的是,与标准训练过程(最终训练损失为2.64)相比,蒸馏模型更易于推广,收敛时间更长(学生网络的最终训练损失为2.75)。随着时间的推移,蒸馏模型的性能会更好。
- Ablation study for DeepHash:在DSHSD算法的基础上,结合其他DeepHash方法进行了实验。基于MobileNetv3的不同策略的一些结果。可以看出,通过标签平滑,可以进一步提高二进制特征表示能力。
- Inference time latency on test set
- 在测试集上,比较了PP-ShiTu和服务器模型的推理速度。服务器模型在Packerclas上发布,并使用ResNet-50主干网进行检测和特征提取。两款模型F1成绩均为0.3306。在CPU和GPU服务器上测试的两个模型的延迟。
- PP-ShiTu和服务器模型在测试集上的推理时间。在批处理大小为1且启用了MKLDNN的模型上测试的延迟,线程数为10。